
下記の記事でお知らせした通り、 RINEARNでは先日、Java®/C#/C++/Rust製のソフトウェア開発で利用できる、オープンソース&著作権フリーの式計算ライブラリ 「 Exevalator(エグゼバレータ、式の計算/評価器を意味する Expression Evaluator の略)」をリリースしました。
» 2022/04/16の記事: 多言語対応&著作権フリーの式計算ライブラリ「 Exevalator(エグゼバレータ)」をリリース
この Exevalator はオープンソースのソフトウェアですので、必要に応じて、ソースコードを改造/流用する事なども可能です。 そこで今回は、Exevalator の内部構造について解説します。
なお、今回の記事は、ソースコードの内容を追う際の参考資料としての位置づけも想定しています。 従って、普通に地の文を書くと長く冗長になってしまうため、文の丁寧さなどは置いておき、淡々とまとめていきます。 内容が次々と唐突に変わるかもしれませんが、ご容赦ください。
また、Exevalator のソースコードは Java/C#/C++/Rust 版がありますが、特に断りの無い限り Java 版のソースコードの構造を前提に解説します。 大まかな構造はどの言語用の版でも同じですが、微妙な違いは存在します。
はじめに、Exevalator 内部の全体像を図示したブロックダイアグラムを見てみましょう。下図の通りです。
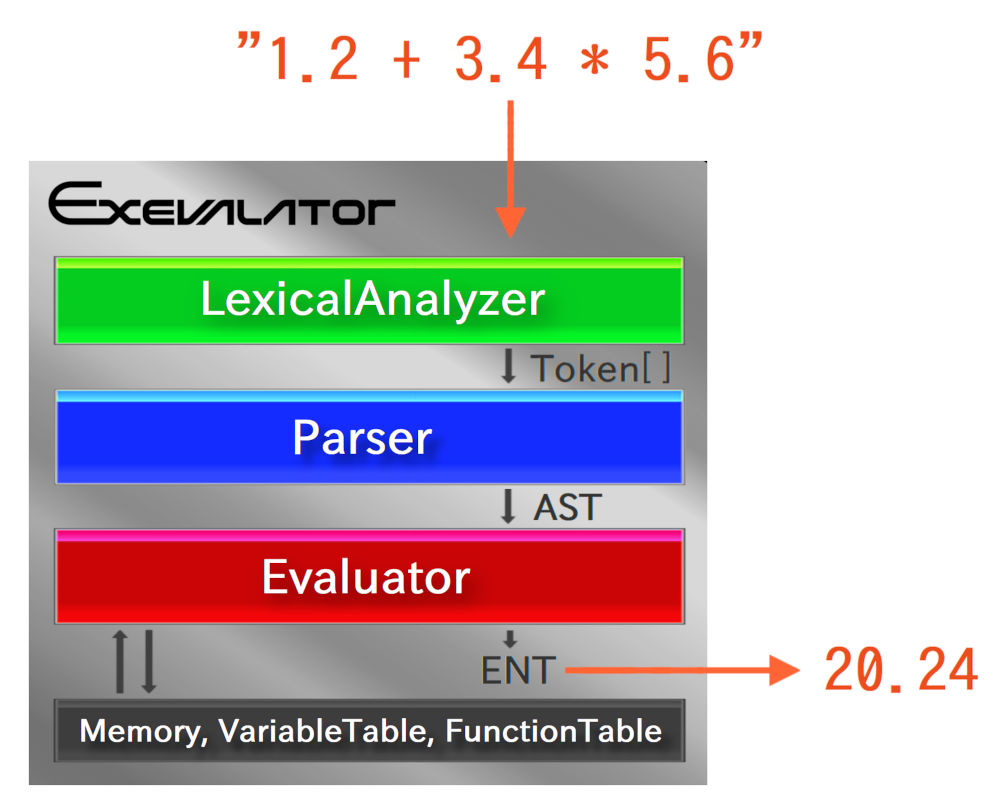
上図の通り、Exevalator 内で大きな役割を担うコンポーネントとして、まず以下の3つが挙げられます:
また、規模的に上図ではまとめて1つのブロックとして描かれていますが、以下の要素も、場面においては存在を認識しておく必要があります:
これら3つは、内容の通り、変数や関数の機能を使用する際に必要となるものです。 それは結構後のステージなので、それまでは一旦忘れてしまっても問題ありません。
本当に必須なのは、最初に述べた LexicalAnalyzer、Parser、Evaluator の3つです。この記事でも主にこれら3つに、順を追ってフォーカスしていきます。
それでは内部を追っていきましょう。ここからは前提として、以下の計算式が入力されたものとします:
この式が Exevalator 内部で、先の図の各コンポーネントを通って処理されていく様子を追いかけていきます。
最初に通るのが LexicalAnalyzer (レキシカルアナライザ、字句解析器) です。 これはその通りの名前のクラスとして実装されていて、その analyze メソッドに、文字列の(String型の)計算式が入力されます。 すると、計算式の内容がトークン単位(後述)に分割されて、Token型の配列として返されます。
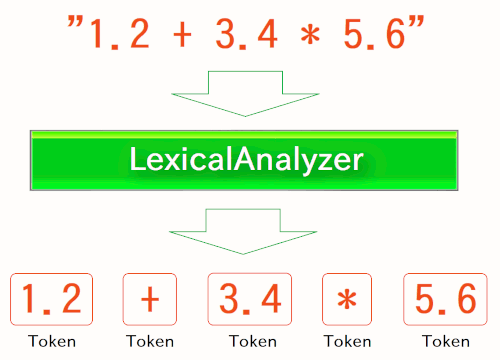
ここでトークンとは、「 1.2 」などの数値や、「 + 」などの演算子といったように、式をほどほどの粒度に砕いた単語/記号の事です。
続いて、トークン列は Parser (パーサ、構文解析器) を通ります。 これもその通りの名前のクラスとして実装されていて、その parse メソッドに、Token 型の配列が入力されます。 すると、式の構文が解析されて、そのAST(抽象構文木、後述)が構築され、そのルートノードが AstNode 型のオブジェクトとして返されます。子孫階層のノードも AstNode の getChildNodes メソッドで辿れます。
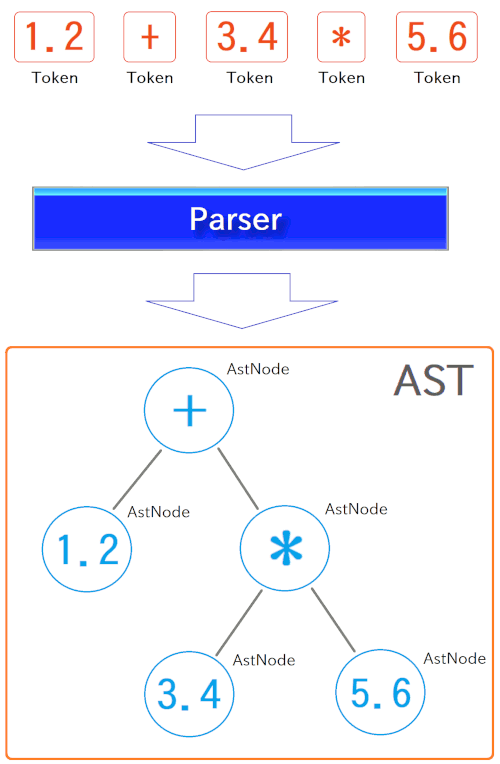
AST/抽象構文木とは、思いきりラフに述べると、トークン間の構文的な関係や、それぞれの役割などを表現するものです。
ここでの「構文的な関係」が少し難しいかもしれないため、実例を挙げて補足します。 例えば同じ「 1.2 + 3.4 * 5.6 」でも、「 (1.2 + 3.4) * 5.6 」と「 1.2 + (3.4 * 5.6) 」とどちらに解釈するかによって、結果が異なりますね。大抵の言語では(Exevalatorでも)演算子の優先順位により、正しくは後者になります。 つまり、「 この『 * 』演算子はこっちとあっちにかかって掛け算を意味し、その結果に『 + 』演算子がかかって、左の値との足し算を意味し、… 」といったような解析が必要になるわけで、それが構文解析の一つのイメージです。
そしてASTは、そういった「かかり方」の関係などを、木構造でうまい具合に表しています。
次は主要コンポーネントの最後、Evaluator (エバリュエータ、評価器)です。これもその通りの名前のクラスとして実装されていますが、後述する通り、動作は少しだけ変則的です。 そのため、前置き的な説明を少し加えます。
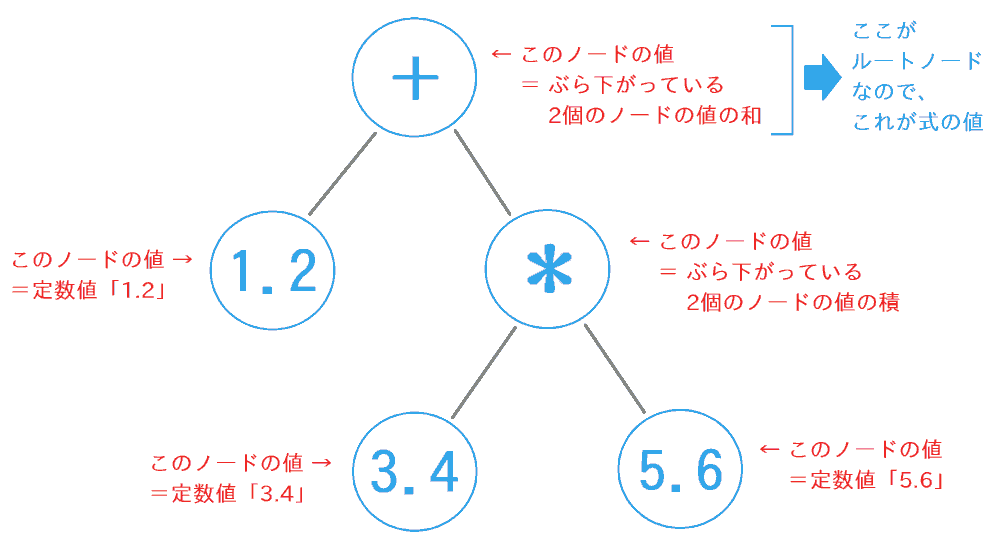
Evaluator は、ASTの形で表された式の値を計算(評価)する役割を担います。これ自体は、処理速度を特に気にしなければ、とても簡単な方法で行えます。
具体的には、ASTを末端から順に辿っていき、演算子ノードの位置では、その左右にぶら下がっているノードの値に演算を行って、結果をその演算子ノードの値(つまり上層から参照される際に返す値)とするだけです。 数値リテラル(式内に直接書かれた定数値)のノードの値は、その定数値そのものとします。変数ノードは、メモリから値を読んでくるようにすればOKです。 すると、ルートノードの値として、式全体の値が得られます。簡単ですね。
さて問題は、上記のような処理を、どういう形で実装するかです。 最も素直な方法は、「 ループや再帰処理でASTのノードを辿りながら、if 文や switch 文でノードの種類に応じた処理を行う事で、個々のノードの値を求めていく 」といった形で実装する事です。 これは一般にツリーウォーカーなどと呼ばれるタイプの実装です。
しかし、直球な実装のツリーウォーカーは分岐処理が多くなり、それによる処理速度の壁ができます。 その壁を超えるために、関数ポインタ的なものや動的ディスパッチ的な振る舞いをうまいこと使ったりして、分岐を低減する方法が色々と考えられます(その一つの究極がJITです)。
Exevalator でも処理速度的な観点から、少し工夫がされています。具体的には、まずASTの各ノードに対して、それぞれ「 EvaluatorNode 」というクラスを継承した各種サブクラスのインスタンスが生成され、ASTと同じツリー構造に結合されます。 以下ではそのツリー構造を、EvaluatorNode Tree を略した語として「 ENT 」と書きます(※ これはASTとは異なり、一般に通じる呼称ではありません)。
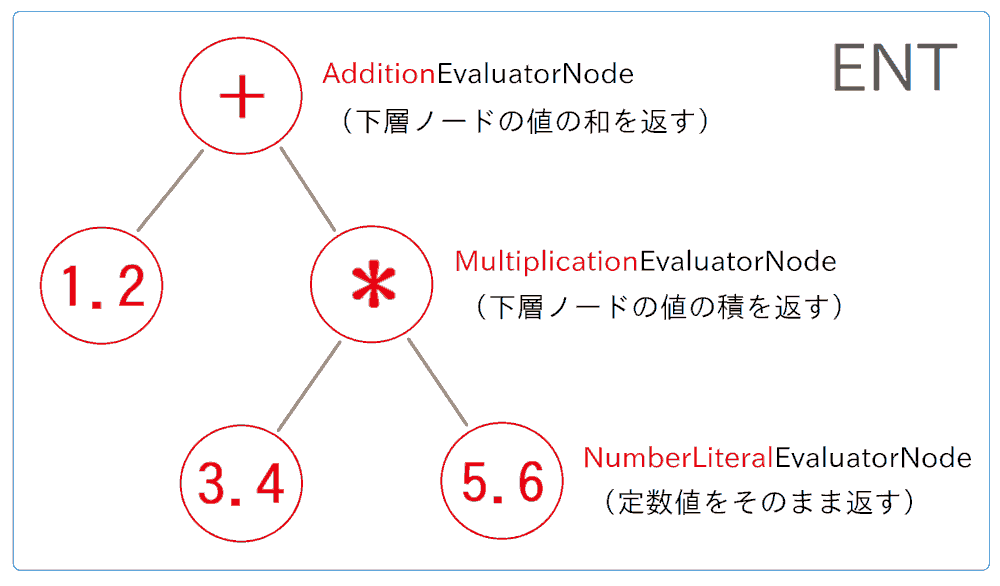
ENTのノードを構成する EvaluatorNode サブクラスは、多くの種類が存在し、対応するASTノードの役割に応じて機能分化しています。 具体的には、evaluate メソッドの振る舞いがオーバーライドされています。例えば可算を行う AdditionEvaluatorNode クラスであれば、自身の下層のノード2個の(それぞれのevaluateメソッド戻り値の)和を返します。 同様に、MultiplicationEvaluatorNode クラスは自身の下層ノード2個の値の積を返します。以上のような具合です。
さて、少し長くなりましたが本題です。上述の EvaluatorNode サブクラス群は、Evaluator クラスの内部クラスとして実装されています。そして、Parser から出力されたASTは Evaluator に入力され、その内部でENTが構築されて、出力としてENTのルートノードが返されます。
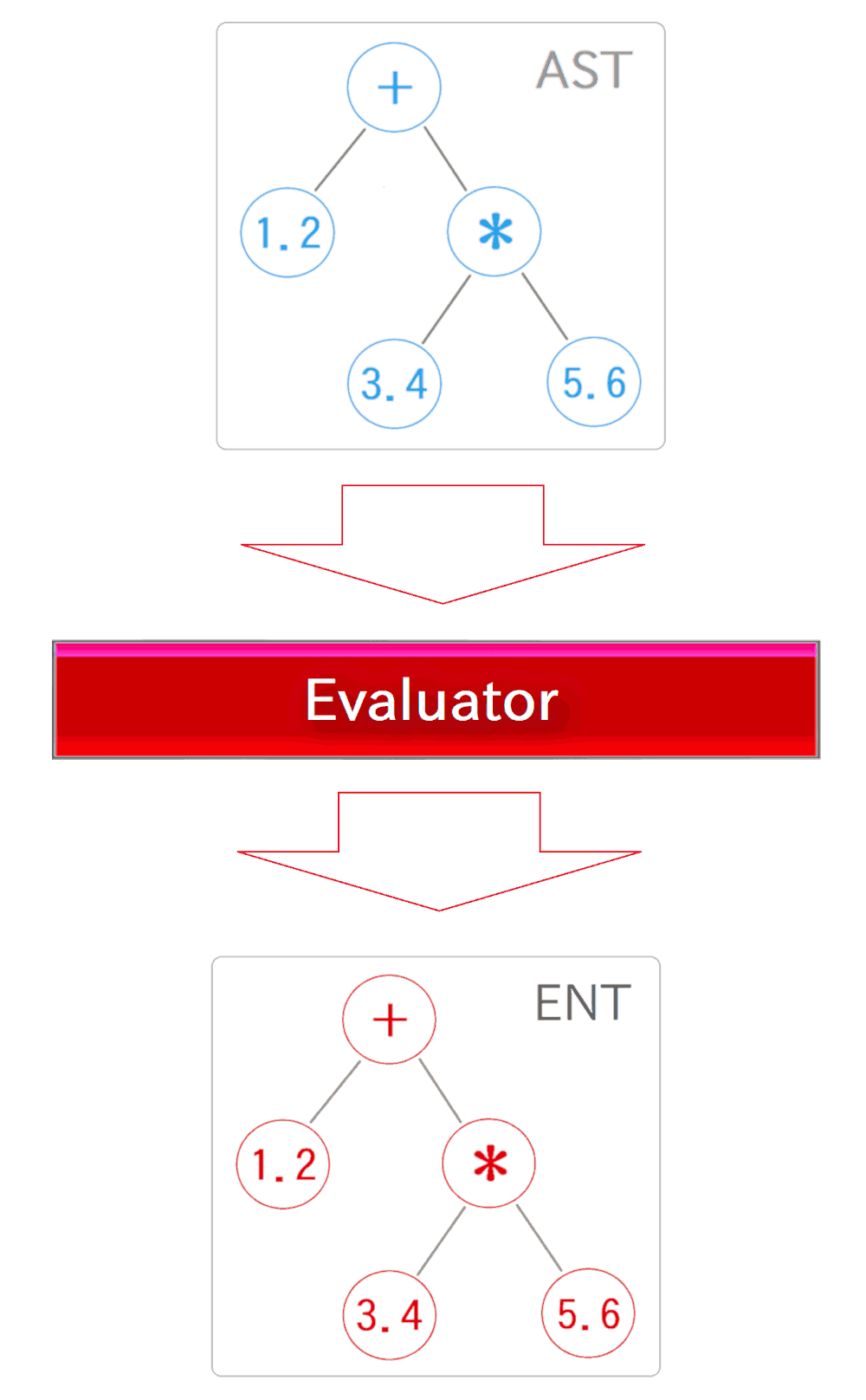
返されたENTルートノードの evaluate メソッドを呼ぶと、処理フローは再帰的にENTの木構造の末端まで到達し、下層から順に evaluate メソッドが実行されて、値が上層へ返され、それがルート階層まで伝搬していきます。 そして最終的にルートの戻り値として、晴れて式全体の値が得られます。
このような実行方法によって、処理内容の切り分けが switch 文のような分岐ではなく、仮想関数テーブルを引くコストだけで済み、「計算処理のみに注目すると」だいぶ高速になります。
一方で、その準備であるENTの構築処理においては、やはり分岐がたくさん入るのと、ノードのインスタンスを生成しまくる事になるため、この時点ではまだ直球のツリーウォーカーより速いとは言えません。 高速化が見込めるのは、すぐ下で説明するように、ENTをキャッシュして使いまわす際です。
基本については、ここまでで全て説明し終えました。ここからは、少し枝葉の話に入ります。
まずは、「 前回計算したのと同じ式が入力された場合 」です。これは、例えば「 変数 x の値を小刻みに変えながら、関数 f(x) の点列を得たい場合 」や、「 大量のデータ要素に同じ式で変換を行いたい場合 」などに生じます。
この場合、式の内容が同じなので、字句解析や構文解析の結果は全く変わらず、最終的に得られる ENT も全く同じ内容になります。 一方で、ENTに含まれる変数ノードは、変数の最新の値を動的に参照するようになっているため、変数値が変わると ENT の計算(評価)結果もちゃんと変化します。 つまり完全に同じENTのインスタンスを使いまわしても、何も問題が生じません。
従って Exevalator は、前回計算した際の ENT を内部的にキャッシュしていて、同じ式が入力された場合はそのまま流用します。 これまでに述べた処理の中で、圧倒的に時間を食うのは字句&構文解析で、次点でENTの構築処理です。 それらを全て省略できるため、キャッシュしない場合と比べると100倍以上の高速化になっています。
続いて、変数を使った式の計算のされ方についてです。これはENTを構成する各種ノードクラスの中で、VariableEvaluatorNode クラスのインスタンスが担います。 このクラスは、内部に変数のアドレスを保持しています。アドレス自体は、ENT構築時に、変数テーブルが引かれて取得されます。
そして VariableEvaluatorNode インスタンスの evaluate メソッドが呼ばれると、メモリー(= double 型配列)内の該当アドレスの値を読んで、それを上層に返します。
変数の次は、関数を使った式についてです。
まず前提として、Exevalator の式で関数を使う場合は、事前に Exevalator.FunctionInterface を実装した関数実行オブジェクトを作成し、 登録しておく必要があります。
そして、ENT内での関数コールの箇所では、FunctionEvaluatorNode クラスのインスタンスが組み込まれますが、これが内部で上記の関数実行オブジェクトを参照しています。 その関数オブジェクトは、ENT構築時に、関数テーブルが引かれて取得されます。
そして FunctionEvaluatorNode インスタンスの evaluate メソッドが呼ばれると、関数実行オブジェクトの invoke メソッドを呼び出して実行します。 その際の引数としては、子ノードとしてぶら下がっているノードの(evaluate結果の)値が渡されます。 そして、関数実行オブジェクトの戻り値が、そのままENTの上層に返されます。
説明の繋がりの都合で、順序が逆になってしまいましたが、最後に変数や関数の登録や書き換え操作についてです。
既に登場した通り、Exevalator はフィールドとして、変数テーブルや関数テーブル、および変数値を控えるメモリー(としての double 型配列)を持っています。 そして、変数や関数の登録や、変数値の書き換えのリクエストなどが来る度に、それらの内容を更新します。 そして、その情報がENT構築時などに参照されてノードに埋め込まれ、実行時に使用されます。
具体的には、新規変数の登録(宣言)は、アプリ開発者が Exevalator の "declareVariable(String name)" メソッドを呼んで行います。 これが呼ばれると、Exevalator はメモリー配列内の未使用アドレス(インデックス)を 1 つ確保して、 そのアドレスと変数名の組を、変数テーブルに登録します。そしてそれが、ENT構築時などに、アドレス取得用に参照されます。
変数値の更新は、Exevalator の "writeVariable(String name, double value)" メソッドを用いて行います。これが呼ばれると、Exevalator は変数テーブルを引いてアドレスを求め、 そしてメモリー配列内でそのアドレスに対応する要素の値を書き換えます。 それがENTの計算時に反映される仕組みは、既に説明した通りです。
関数の登録もよく似ていて、より簡単です。 これは Exevalator の "connectFunction(String name, FunctionInterface functionObject)" メソッド を呼んで行いますが、 その際に、Exevalator は関数名と関数オブジェクトの組を、関数テーブルに登録します。 あとはそれがENT構築時に参照されるだけです。変数のようにアドレスを仲介したりは行われません。 実行時にどのように呼ばれるかは、直前のセクションでの説明の通りです。
◇以上が、Exevalator の内部アーキテクチャの大まかな様子です。 Exevalator 関連の続報については、今後もこのコーナーで随時お知らせしていきます。
