
As I mentioned in the previous article, RINEARN has recently started offering Assistant AIs that help users with our software.
This article, along with the next one, is a continuation of the previous content. From here on, I'll be sharing the behind-the-scenes details of how we created the Assistant AIs mentioned above!
However, before diving into how to build an Assistant AI and refine it through actual usage, it's important to first have a solid understanding of the AI itself and the surrounding systems. Simply explaining how to build it might enable you to replicate the exact same AI, but when it comes to customizing it for your own needs, you might hit some roadblocks.

So, I'll split this into two (or possibly more) parts, and in this first article, Iüfll explain the fundamental knowledge youüfll want to grasp beforehand. In the next article, weüfll actually create an Assistant AI using ChatGPT. If you feel you're already familiar with this background knowledge, feel free to skip this one and proceed to the next article.
Now, letüfs dive into the basics together!
First and foremost, it's essential to understand the AI itself. So, let's start there.
Many of the conversational AIs that have rapidly gained popularity recently, such as ChatGPT, are built on a system known as Large Language Models (LLMs). The reason why modern AIs can hold such natural conversations, excel at answering questions, and perform tasks like translation so effectively is largely due to the meteoric rise of these LLM-based AIs.

As we use an LLM-based AI as an assistant through ChatGPTüfs service, itüfs crucial to first understand the background and characteristics of LLMs. So, letüfs dive into that.
Now, this might sound like it's flipping the script on everything from the introduction of this article, but the truth is that there are still many unknowns about how LLMs achieve such results. In fact, itüfs difficult to explain their behavior with solid reasoning.

Of course, weüfve reached this point thanks to the efforts of countless researchers steadily working toward "the day these kinds of systems would emerge." This breakthrough didnüft appear out of thin air. Research on ügAI that can hold conversationsüh and ügAI capable of natural reading and writingüh has been ongoing for a long time.
However, there was a major technical leap a few years ago, and from there, the pace of development accelerated dramatically, reaching today's level of performance at an astonishing speed.
But why is this method so successful? What sort of "revolution" is happening inside the neural networks (the brain-like structures that act as the thought circuits of the AI)? The fact is, we still donüft fully understand these questions.
In other words, the advancement of these models is outpacing our understanding, and now the world is scrambling to research and figure out why they work so well. The historical development of this field is quite fascinating, and tracing it will help us grasp the current state of affairs.
Letüfs hop into a time machine and go back about seven years to 2017. At that time, AIs weren't yet capable of generating or understanding natural conversation and text at the level we see today.
In general, to correctly understand human language (natural language), it seems pretty important to be able to "read between the lines" and understand the context. In fact, this was one of the big challenges at the time. Various attempts were made to enable neural networks to better handle context in natural language processing.
One such attempt was the mechanism called "Attention." Roughly speaking, it's like identifying connections between different parts of the context, such as, "this part of the context is linked to this particular word over here" with varying degrees of strength (thatüfs my non-expert interpretation, at least).
The Attention mechanism had already been in use for a while, combined with other techniques. But, over time, it became clear that Attention was fundamentally very important, and if used effectively, other techniques could be drastically reduced - and with enough data and computational power, it could still achieve great results.
In particular, it seemed that the idea of processing sentences sequentially from beginning to end, with each part influencing the next (as in RNNs), might not be necessary. This had previously been a bottleneck for efficiency, but by eliminating that constraint, parallel processing became possible.
With parallel processing, we could take full advantage of the power of GPUs and TPUs (along with massive server clusters) to accelerate learning and training, allowing for larger-scale models that were previously computationally impractical.
The key paper that introduced this concept was titled "Attention Is All You Need." This was a paper by Google, and it introduced a neural network model based on this concept called the Transformer).
Thanks to the application of Transformer-based models, the efficiency of learning and training improved significantly, and handling natural language saw major progress. In fact, today's AI breakthroughs are largely built on the foundation of the Transformer. It's practically the core technology of the current LLMs.

In fact, Google itself applied the Transformer and created a powerful practical model called BERT in 2018. BERT gained a high level of understanding of text by learning through a massive fill-in-the-blank approach, where it essentially filled in missing words in sentences to grasp the "concepts that form human language." Additionally, through training for question-answering tasks, BERT became capable of handling those too, and it has been used for chatbot applications in various fields.
BERT is still widely used in natural language processing today. It's capable of many things that seem like the roots of ChatGPT's abilities, but for some reason, it didn't explode in popularity with the general public the way ChatGPT did. I'm not exactly sure why, but maybe it's because BERT is more specialized, and there's a difference in the scale and amount of knowledge it holds?
BERT isn't the kind of model that can answer anything and everything across a broad range. It needs to be trained and fine-tuned for specific tasks. However, the abilities to understand text and answer questions did exist with BERT, so it wasn't like ChatGPT was a sudden revolution in that sense (at least from a chronological perspective).
ü” * Additional note: After asking ChatGPT about this point, it explained that "ChatGPT (the GPT series) is a 'generative' model, excelling at predicting the next word and generating new text, whereas BERT is 'bidirectional,' focusing on understanding the entire sentence and filling in missing parts. In other words, BERT emphasizes understanding rather than generation." This suggests that the key difference lies in the focus of their architectures. As We'll explain later, ChatGPT's emphasis on generation likely made it a better fit for general-use applications.
Even though BERT is smaller in scale compared to the GPT models we'll talk about later, we still don't fully understand *why* it was able to acquire such capabilities through its training. From here on, it becomes more of a discussion of outcomes and phenomena - essentially, "we did this, and we got these results."
Just like how we haven't fully figured out how the human brain works, it's extremely difficult to understand what's happening inside large neural networks, how they make judgments, and how they operate. While there are studies that explore these areas bit by bit, much of it remains a mystery, much like brain research.
Now, we finally get to the appearance of
It was probably something like, "If it learns tons of text, it should be able to write all sorts of text naturally, right?" That seemed to be the thinking at the time.

This GPT evolved through versions such as GPT-1, GPT-2, and so on. With each version, the scale (in terms of the number of parameters) grew, and the amount of text it trained on also increased. Along with this growth, GPT gained a vast amount of knowledge, allowing it to generate natural text on a variety of topics at a level far more sophisticated than earlier models.
If I remember correctly, around the time of GPT-2, there was news about how "the text generated by GPT had become so natural that it was hard to distinguish from human-written content, and it could be dangerous." That news created quite a buzz (*). This is probably when I first came across the term "GPT." However, at the time, it was still mainly regarded as a tool for generating natural text - progress within the initial concept of GPT.
Then came GPT-3, which likely garnered a lot of attention, but while its derivative, "InstructGPT," didn't make headlines, it was actually a crucial development that laid the groundwork for what was to come. InstructGPT incorporated a method called Reinforcement Learning with Human Feedback (RLHF), which allowed the model's outputs to be efficiently refined based on human feedback. This resulted in significant improvements in accuracy and quality, and I remember it being a hot topic when ChatGPT first appeared. Although I don't personally know the exact mechanisms, it's likely that RLHF played a major role in bringing the model to a practical level, based on the buzz at the time.
And finally, they got a model that was fine-tuned from InstructGPT to "interpret inputs as human questions and generate appropriate responses." This worked incredibly well (*), enabling human-AI interactions to become remarkably natural, with the AI freely engaging in conversation, armed with a wealth of knowledge. This led to the birth of ChatGPT.

And so, all the pieces came together:
With all these elements in place, it was clear that this wasn't just useful for AI developers but also incredibly practical for general users.
And what took these capabilities to the level of a practical service was the release of ChatGPT as a web service for the public. That was in 2022.
As you know, since then, ChatGPT has become a global hit, the models have continued to evolve, and the range of tasks it can handle has expanded even further.
So, in terms of the timeline, that's how things unfolded. Hopefully, I've conveyed the general idea that after the breakthrough in efficiency with Transformers, scaling up and experimenting with various techniques eventually led to the results we see today.
But still, the question remains: "Why? How is AI even capable of doing this?"
As I mentioned earlier, the inner workings of large neural network language models (LLMs) are so complex that we don't fully understand how they make decisions or operate - they're kind of like the human brain. However, through observation and outcomes, two important characteristics have become apparent:

It kind of feels like an RPG where you suddenly learn a new spell after leveling up, doesn't it? The way LLMs evolve is almost like biological evolution in some ways.
Because of these characteristics, when it comes to LLMs, if you're solely focused on performance without worrying about cost-effectiveness, then bigger models are fundamentally advantageous. However, large LLMs are also heavy and require a lot of resources to train. The cutting-edge, massive models are trained over long periods of time using the server clusters in the data centers of large corporations.
That's why we've now entered an era where massive corporations are scrambling to gather as many GPUs as possible to train gigantic LLMs with enormous numbers of parameters. High-end GPUs for this type of training have become scarce and difficult to purchase globally.
As a result, LLMs, which initially could only handle natural language understanding and generation (with a little extra), have progressed at an incredible pace. Now, they can do various sorts of things, even things that don't seem directly related to language.
In addition to question-answering, LLMs can now provide answers that seem as though they are "thinking deeply" (though there are differing opinions on that), write programming code upon request, help with data analysis, understand images (multimodal capabilities), and more. And they'll likely keep expanding their abilities going forward.
With the broad, versatile abilities that LLMs have developed, we've decided to have them serve as our Assistant AI. Specifically, here's what they do:
This is what our Assistant AI is actually doing in practice.
That's right - today's LLMs can already handle tasks like these! It's surprising, isn't it? But we still don't know exactly how it's possible. It's likely that it's because the folks at OpenAI trained the model so skillfully and effectively that it just turned out this way.

Even though it's been trained extensively, you can't help but feel like there must be some kind of intelligence inside for it to pull this off, right? There's this overwhelming sense that "something has been born."
In other words, we're asking this entity - this "something we might even need to call a new form of intelligence," something that humanity doesn't fully understand yet - to act as our Assistant AI. I think it's important to approach it with that mindset. Calling it a "bug" when things don't work right won't get us anywhere. After all, no one really knows why it can do what it does. It's fundamentally different from traditional software. All we can do is continue to accumulate "experience that helps us work well with it."
Technically, the fundamental mechanism behind LLMs is determined by generating the next word based on a probability distribution, but we have no idea how the massive neural network responsible for determining that probability distribution chooses the next word.
Initially, it was probably just an attempt at something like, ügCould we use statistics learned from vast amounts of text to pick the most likely next word? And if we repeat that process, could it generate plausible sentences?üh But now we've reached a point where it can do far more than what was originally expected.
This raises the question: are LLMs ügthinkingüh like humans? But then again, what does it even mean to ügthinküh? Could it be that human thought, which appears to be complex, can actually be explained by simple probabilistic behavior with just a higher number of dimensions? This leads to more fundamental mysteries. Humanity is now facing questions that challenge the very definition of intelligence itself.
Perhaps, when a massive neural network and training that organizes knowledge come together, something we might call "intelligence" naturally emerges. In that case, language models may simply be the interface through which this emerges. In fact, there are many aspects of recent image generation AI that give off a sense of "intelligence."
Or, conversely, maybe it's language itself that's crucial. We used to think of language as a tool for communication and assisting thought (at the level of the Sapir-Whorf hypothesis), but what if language itself is the key to creating intelligence? In fact, what if language and intelligence are not separable but projections of a single, higher-dimensional entity?
Both of these could have implications not just for AI but for understanding the roots of human intelligence, making them fascinating questions for all of us.
Alright, the first half of this article has already gotten quite long, but my AI enthusiasm for today hasn't been fully vented yet. Let's move on to the second half, where we'll discuss another important system: RAG.
As I mentioned in the first half, GPT-based LLMs have pre-trained (that's what the ügPüh in GPT stands for) on a vast range of knowledge from around the world, allowing them to answer user questions based on that knowledge.
However, there are times when you want your custom AI to learn additional information that it doesn't already know. You might also want to tweak its behavior a bit to make it more suited to a specific purpose.
This kind of additional learning is actually called fine-tuning, and those running small-scale open-source LLMs on their own might find it easier to try out (though it would still require a high-performance machine). OpenAI also offers fine-tuning capabilities on their side if you have an API contract, allowing you to fine-tune GPT models in their environment.
That said, even though I haven't tried fine-tuning myself, it seems much more challenging than it initially sounds. In general, teaching neural network models anything is quite difficult, requiring a lot of expertise, and just assembling a good dataset is already a specialized and business-level task.

It seems like fine-tuning is the way to go when you want to adjust or refine behavior for specific use cases (and sometimes it's the only option), but for simpler use cases, like ügI've got a small document, and I'd like the AI to answer questions based on its content,üh fine-tuning doesn't seem to be the best fit. I'd like to try it out myself at some point, but I imagine it would be quite a challenge.
So, what's the practical solution when you just want to "add a bit of knowledge to your Assistant AI"? The go-to method for this is RAG (Retrieval-Augmented Generation).
Rather than having the model itself memorize new knowledge, the idea is to create something like a "knowledge retrieval system for AI" and have the AI use that.
In other words, instead of the AI relying solely on its pre-trained knowledge, it searches through a pre-registered set of information, reads and understands the relevant results, and then answers the user's question. It's kind of like how a person would Google something before giving an answer.
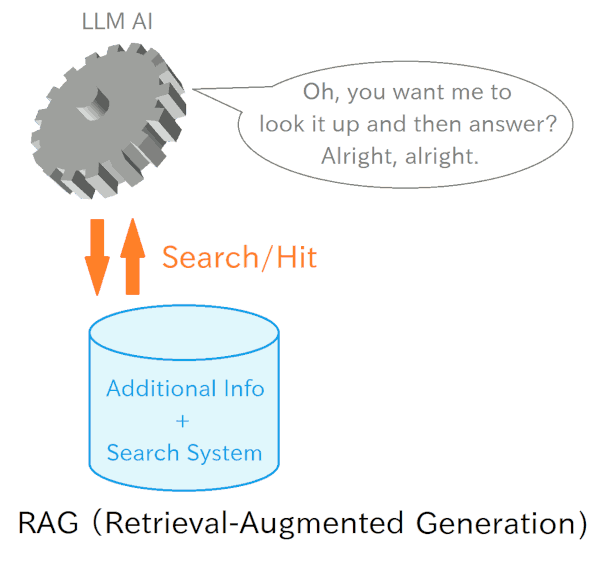
Now, RAG is something that many companies are starting to build in-house, but with ChatGPT, a paid Plus member can easily set it up and use it via a web browser.
Specifically, with the "Knowledge" feature, you can register the knowledge, and the GPT model will automatically search and refer to it when answering questions. In other words, it becomes a simplified RAG. Compared to fine-tuning the GPT model itself (even if you could), this approach is much more accessible.
In fact, the project we worked on to create the RINEARN Graph 3D Assistant is essentially a ChatGPT that has been RAG-ified, with all the user manuals and related materials for RINEARN Graph 3D loaded into the Knowledge system, making them searchable. It references the necessary information and answers user questions based on that.
So, when building something like an Assistant AI, using a system like RAG can be very useful.
However, if you just throw data into RAG without much thought, you might end up getting nonsensical answers and feel disappointed because it doesnüft seem useful at all. But donüft lose hope just yet!
To achieve practical levels of accuracy, you'll need to go through a phase of trial and error and tuning. As a foundation for that, it's important to understand some of the challenges and techniques behind the RAG system.
The first and most important challenge is that LLM-based AIs have a limit on their recognizable context length.
The "recognizable context length" refers to the maximum length of text that the AI can read and keep "in mind" while generating a response.
For example, in a normal ChatGPT conversation, the AI doesn't just respond to your latest question but also considers the history of the conversation. It's able to respond while taking into account what has been said before because that past conversation is still within its "recognizable context."
However, when a conversation gets really long, you might notice that the AI starts forgetting earlier parts of the discussion. This happens because the conversation has exceeded the recognizable context length, and earlier parts have been "forgotten" (there may also be effects related to how attention weakens with distance).
Now, imagine giving the AI the full text of a document that's hundreds of pages long as reference material without any special processing. As the AI reads through it, the document will exceed the recognizable length, and parts of it will fall out of the AI's "awareness."

When that happens, the AI won't be able to keep track of what's said where, and even summarizing the important sections would be difficult. Additionally, the prompt itself, which must also be kept in mind, might get squeezed out.
In other words, trying to provide the AI with a massive document by just pasting the entire text into the prompt is simply impractical (though this might work with smaller documents).
At this point, you might be wondering, "Wait, but ChatGPT's Knowledge feature lets you register really long files, and the AI still recognizes them, right?" And yes, that's correct.
This works because, behind the scenes in the Knowledge system, techniques like chunking - splitting the text into smaller, manageable sections - are likely being used (the exact details are not public, but based on its behavior, this seems very likely).
And in fact, how this chunking is done seems to have a big impact on the accuracy of the AI's responses. So even if you're not explicitly chunking the data yourself, it's important to be aware of this process and its effects.
So, a natural approach would be to split the document into smaller sections, called chunks, and then have the AI search through them and pick the relevant ones. Or you could take the search results and further split them into chunks, focusing on the most relevant sections.
By splitting the document into chunks, you can indeed avoid exceeding the AI's recognizable context limit and work around the issue we mentioned earlier. However, this introduces another challenge: the context between chunks gets cut off.
For example, think about those tweet threads on X (formerly Twitter). Sometimes, you come across a tweet in the middle of a long thread and think, "Huh? What's this about?" You can't understand it until you trace the whole thread and read everything in context. You might even realize, "Oh, I totally misunderstood it at first!" Doesn't this happen to you?

The same applies to regular documents. Although we usually don't think about it, there's always a connection between sections that ties everything together. That's precisely the kind of "context" that modern AIs are so good at reading, as we discussed in the first half of this article.
But chunking cuts this essential context, splitting it apart. The chunks lose their connection to one another, and each chunk becomes an isolated piece of text.
If the chunks are not split properly, reading just one specific chunk may make it hard to grasp the meaning, or worse, you might interpret it as something entirely different. That's the downside.
That said, splitting large documents into chunks is pretty much unavoidable, so the key question becomes where and how the chunks are split. This is especially important when the chunking is done automatically, like in ChatGPT's Knowledge feature.
Now for the next challenge. When you split a document into chunks, you need to make sure that the AI can search for the chunk that contains the information it needs.
This is obviously important. However, when using AI services like ChatGPT or those provided by big tech companies, you don't have control over the search process itself - you have to use the system as it's designed. That said, it's still effective to have a rough idea of what kind of search the system is likely doing behind the scenes and then optimize or tweak the information you register accordingly. I went through a lot of trial and error on this while building the Assistant AI for this project.
So, let's take a look at the different types of searches that are commonly used.
Now, here comes a difficult concept right off the bat. Just from the title above, you might be thinking, "??? What are you talking about???" And I get it, this is a tough topic. Sorry about that.
So, let's dive in. In 3D space, a point's location is specified by three values, (x, y, z), right?
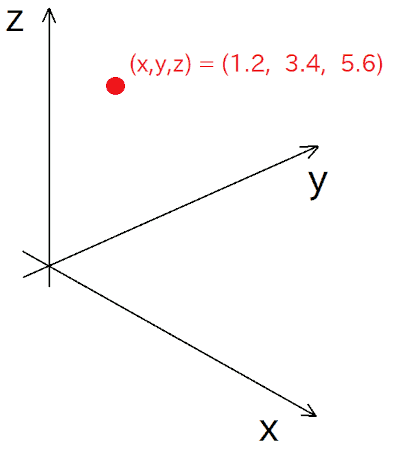
In the same way, we can think about an n-dimensional space, where the position of a point is specified by n values:
Basically, it's like an N-dimensional vector.
Now, imagine we could somehow represent "meaning" from our real world as positions in this n-dimensional space.
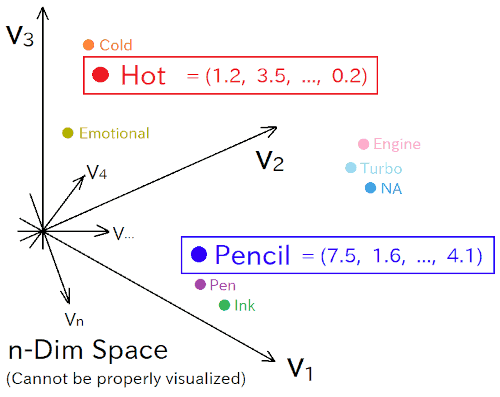
For example, the position (1.2, 3.5, ..., 0.2) could represent the concept of "hot," while (7.5, 1.6, ..., 4.1) might represent "pencil." Close positions would represent similar meanings, while distant ones would represent completely different meanings.
So, how do we actually construct this convenient space? The idea is to take a lot of words and sentences and arrange them within this n-dimensional space so that similar meanings are placed close together, while different meanings are placed far apart. This process is called "embedding."
Doing this manually would be nearly impossible, so many techniques have been developed over the years. In 2013, Google developed a technology called Word2vec, which allowed this process to be done efficiently and with high accuracy. In Word2vec, a neural network analyzes a large corpus of text and automatically determines the relative positions of words based on their meanings. This technology underpins many modern natural language processing techniques, including LLMs.
Now, after this long introduction, let's think about how we can use this semantic space for chunk search. The idea is to split a document into chunks, embed each chunk into the semantic space, and calculate its corresponding embedding vector (its position in that space).
Then, when you need to search for information, you convert the "meaning" of the query into a vector in the semantic space. The system then searches for the chunk whose embedding vector is closest to the query's vector. The chunk corresponding to that vector will likely contain the information most "semantically" relevant to the search.
So, what's the advantage of doing something this complex? The key benefit is that you can find information that's semantically similar, even if the text is expressed differently. For instance, "automobile" and "car" mean pretty much the same thing, but their text representation is completely different. So, even if there's detailed information on "automobiles," a simple keyword search for "car" might not find it. But with a semantic search, it would hit the mark.
Next up is a simple one: the keyword-based search method that's been around for ages.
In this method, when you input a keyword into the search system, it returns information that contains a simple (text-based) match for that keyword.
The system works by generating a list of keywords from each chunk when it is registered, and creating an index that links the keywords to the content of the chunk. Then, during a search, when you input several keywords related to the information you're looking for, the chunks with the highest match rate are returned.
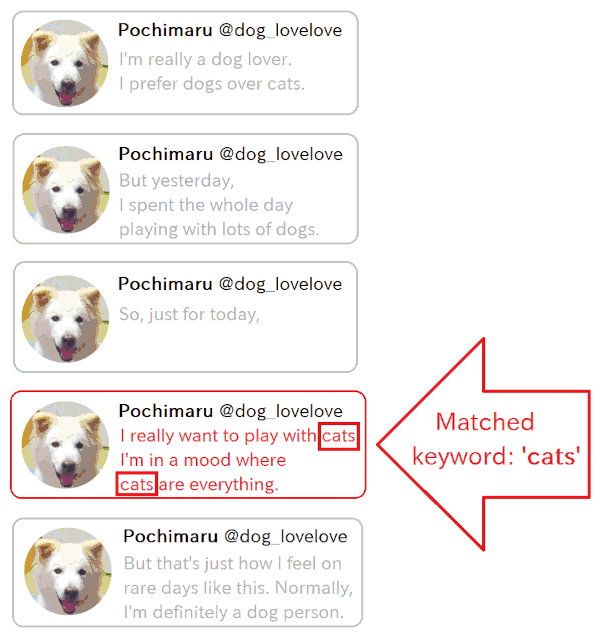
While it's a simple method, it's actually quite useful. Personally, I suspect that the RAG systems provided by major tech companies probably combine not just vector searches, but also this kind of keyword matching. The strengths of both methods seem to complement each other.
When I was fine-tuning the Knowledge system registered in ChatGPT, I tested it out while consulting with the AI itself. During these tests, I noticed several moments where it seemed like keyword-based search was being used. In fact, there were cases where the output accidentally included what looked like keyword-based queries (which was kind of cute). Of course, it's also possible that these seemingly keyword-based queries were further converted into vectors for semantic search, so I canüft say anything for certain.
To test this, I asked questions using both words that appear in the Knowledge I registered and words with similar meanings that aren't in the Knowledge, and it felt like I got more accurate responses when I used the former. This gave me the impression that ChatGPT's Knowledge system seems to rely quite a bit on keyword-based text searches, though it's likely using a combination of methods.
Now, this next part is not based on any known facts, just a personal hunch. It's more like, "maybe they're doing something like this?"
When I was building the assistant AI this time, I experimented a lot with different ways of chunking the Knowledge in JSON format, trying to find the optimal length and places to cut. At first, I thought that the chunks would just be pulled out by the search process I mentioned earlier, and that the assistant AI would read them directly. I figured, "This length seems readable, right?"
But then I noticed that longer chunks seemed to perform much better than expected. Even chunks that were so long they should've exceeded the recognizable context length didn't cause confusion - they still accurately found the right place. This led me to think, "Could the chunks be automatically split into smaller sub-chunks?" But even so, I didn't sense the kind of disjointedness or randomness that you'd expect if the context was getting cut off. Normally, if you split things up too finely, the answers would start becoming nonsensical.
That's when I started to wonder: Could it be that they're using some lightweight LLM or another system to extract and summarize the relevant parts from within each chunk before returning the answer to the main AI? I'm not sure, but it's a possibility that came to mind.
If that's the case, there may not be a need to cut chunks too finely when using ChatGPT's Knowledge system (since doing so could sever important contextual links). In fact, for the assistant AI I built this time, I ended up sticking with relatively long chunks.
Finally, this point is a bit outside the realm of information retrieval itself, but it's an important consideration when using the system: What happens when multiple chunks are equally relevant according to the search? Which one gets prioritized?
When you register a large amount of information into a RAG system, you'll often encounter cases where different chunks overlap in terms of meaning or keywords (but still say different things). As a result, you might experience frustrating moments like, "Ah, it read that chunk instead of this one. For this question, I really wanted it to read from the other partüc"
If you're building your own RAG system, you might be able to adjust the rules for this. However, when using a system provided by ChatGPT or other big tech companies, you can't tweak those rules. Instead, you'll need to guess how the system works and adjust the information you register accordingly.
In the case of ChatGPT's Knowledge, my impression is that the chunks closer to the beginning seem to be prioritized. Since the specifics of the system aren't public, this is purely based on my personal experience, but I've seen similar observations online.
I particularly noticed this when I tried to prevent hallucinations by creating a "list of frequently misanswered questions" and adding it to the Knowledge as a filter. At first, I inserted it toward the end of the Knowledge file as an appendix, but it didn't seem to help at all. However, once I moved it to the very beginning of the Knowledge file, it worked remarkably well. This experience made me realize how important it is to understand how priority is determined in the RAG system you're using, since it can greatly affect tuning results.
Once again, this has turned into an incredibly long article, but that wraps up the "Basic Knowledge" section.
At first, I thought about combining both the basic knowledge and the assistant AI creation steps into one article, explaining the fundamentals as we build the AI. However, I figured that might make the article too long, so I decided to split it into this article (the Basic Knowledge edition) and the next one (the Creation edition). Judging by the length of this part alone, that was definitely the right decision.
Next time, we'll actually build an assistant AI (GPTs) using ChatGPT Plus features. Stay tuned!

