
このコーナーでも何度かお知らせした通り(下記リンク参照)、RINEARNでは現在、 Java®製のアプリケーション組み込み用スクリプトエンジン「 Vnano 」を、オープンソースで開発中です。 今回は、このスクリプトエンジンのアーキテクチャ面を掘り下げて解説します。
Vnano のアーキテクチャ解説は今後数回に分けてお伝えする予定で、第1回となる今回は、 「 スクリプトエンジンがどのようなコンポーネントで構成されているか 」という俯瞰的な視点で、 全体的なアーキテクチャの概要をお伝えします。 そして第2回以降では、コンパイラなどの各コンポーネントをクローズアップしていきます。
最初に、Vnanoそのものの概要について簡単に触れておきましょう。
Vnano は、Java® 言語で記述された一般のソフトウェア上に搭載し、 文字列データとして渡された計算式やちょっとしたスクリプトを処理する機能を提供するための、小型・軽量のスクリプトエンジンです。

言語仕様面では、C言語系のシンプルな文法を採用しつつ、 アプリ組み込みのスクリプト用途には不要となる機能を大幅に削る事で、全体をコンパクトに抑えたものとなっています。 これにより学習コストを抑え、いわゆる「 電卓ソフトなど、ソフト組み込みのスクリプト機能にありがちな、Cっぽい簡易言語 」といった感覚で、 気軽にソフトウェアに組み込めて、ユーザーにとっても手軽に扱えるものを目指しています。
性能面では、一般的なPC環境での倍精度浮動小数点数(double)演算において、ピーク値で概ね数百MFLOPS(スカラ演算)~数GFLOPS(ベクトル演算)程度の速度水準を見込んでいます。 これにより、そこそこの規模のデータ解析/変換/計算処理などを扱うソフトウェアにおいて、 一部をスクリプト化してプログラマブルにするといった用途にも耐え得るものを目指しています。 実際に、将来的にはRINEARN製のグラフソフトであるリニアングラフ3Dなどでも、ユーザーによるデータ変換機能などでの使用を見込んでいます。
Vnanoはオープンソースのスクリプトエンジンで、ソースコードリポジトリは以下の場所(GitHub)です:
続いて、Vnanoのアーキテクチャ面の解説に入るための下準備として、まず「 Vnanoのスクリプトエンジンを搭載する Java®製のアプリケーション 」の具体的なコード例を見ておきましょう。 なお、Vnanoでは、このようなエンジン搭載側のアプリケーションの事を「 ホストアプリケーション 」と呼びます。
- ホストアプリケーションのサンプルコード -このコードはVnanoのリポジトリに同梱されていて、使用方法もそちらのREADMEに記載されています。
さて、上記のホストアプリケーション側の処理は:
の3ステップです。比較的単純ですね。
ここでクローズアップしたいのは、最も重要な「 3. スクリプトコードをスクリプトエンジンに渡して実行 」の部分です。 先のコード内で、この処理に該当する箇所は以下の通りです:
ここでは簡単にするために、スクリプトコードを文字列リテラルとしてそのまま記述していますが、もちろん動的に生成したり読み込んだりした文字列でも大丈夫です。 さて、この処理が実行された結果として、1から100までの和( = 5050 )がスクリプトによって計算されて、 標準出力に以下の値が出力されます:
これを出力しているのは、スクリプト内では最後に output 関数を呼んでいる箇所ですが、 この output 関数はホストアプリケーション側の内部クラス ExamplePlugin に output メソッドとして実装されていて、 スクリプトエンジンに接続されているものです:
同様に、スクリプトコード内からアクセスしている変数LOOP_MAXも、同クラスのフィールドとして実装されていますね。
ここでのスクリプト処理を、ホストアプリケーション - スクリプトエンジン間のやり取りの視点でまとめると:
という具合になっています。その結果として、1から100までの和を計算するスクリプトコードが実行されて、結果がスクリプト内からの関数呼び出しによって、 ホストアプリケーション側の output メソッドを介して、標準出力に System.out.println されたわけです。
ここまでに見た、スクリプトエンジンとホストアプリケーションの関係を図にすると以下の通りです:
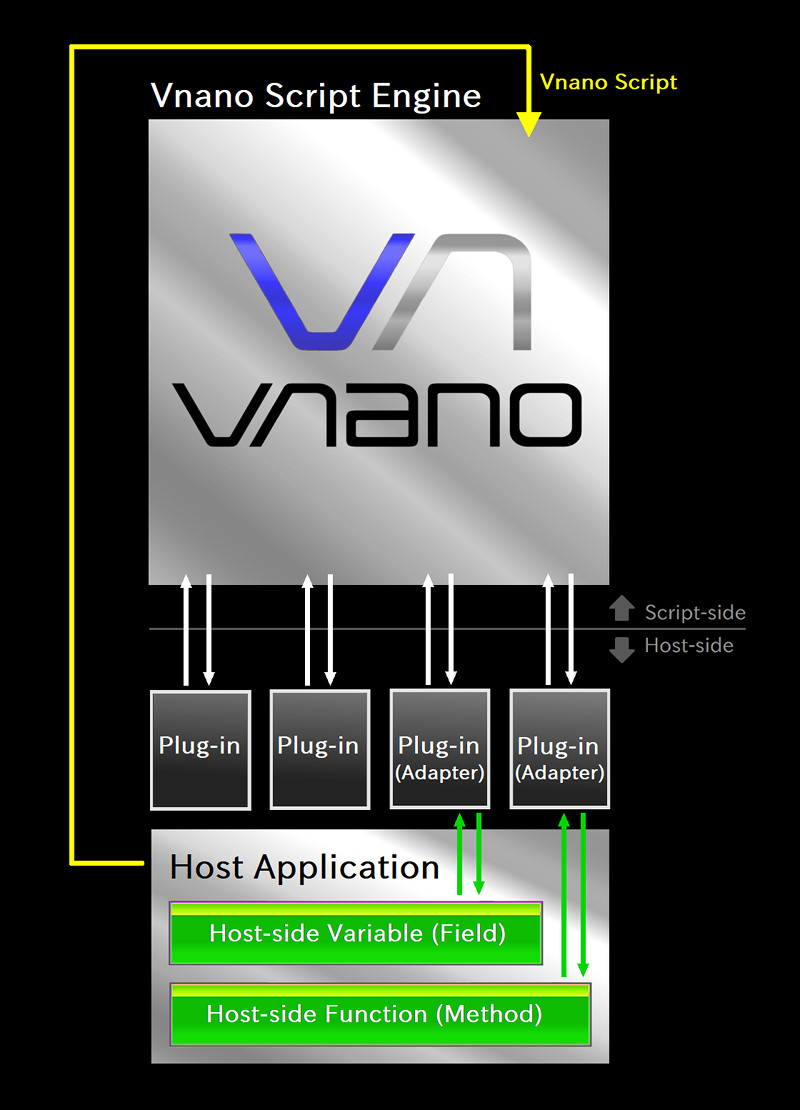
上側のシルバーのブロックがVnanoのスクリプトエンジン、下側のシルバーのブロックがホストアプリケーションを表しています。 矢印はデータや処理のやり取りを表しています。
この図のスクリプトエンジンのブロックに相当する具体的なクラスは、先のサンプルコード内で実際にインスタンスを生成している VnanoEngine クラスです。 実装コードはこちらで、 より下層の構成コンポーネントを組み合わせて使用しているだけなので、これ自体は結構短いコードです。
さて、ここからはいよいよ今回の本題、スクリプトエンジンのアーキテクチャ面を掘り下げて見ていきます。
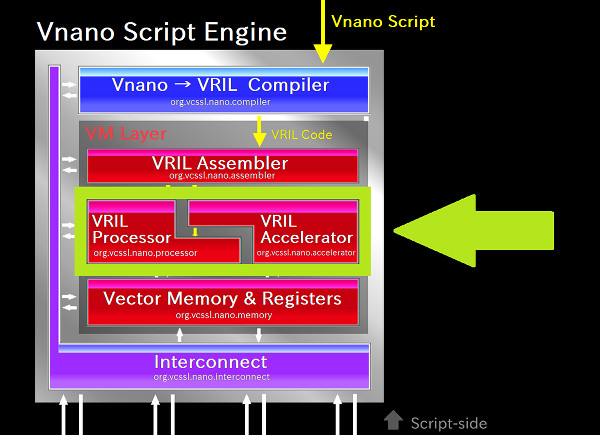
まずは先の図において、Vnanoのスクリプトエンジンを表していた上側のシルバーのブロックの内部を、より細かく描いた図を見てみましょう:
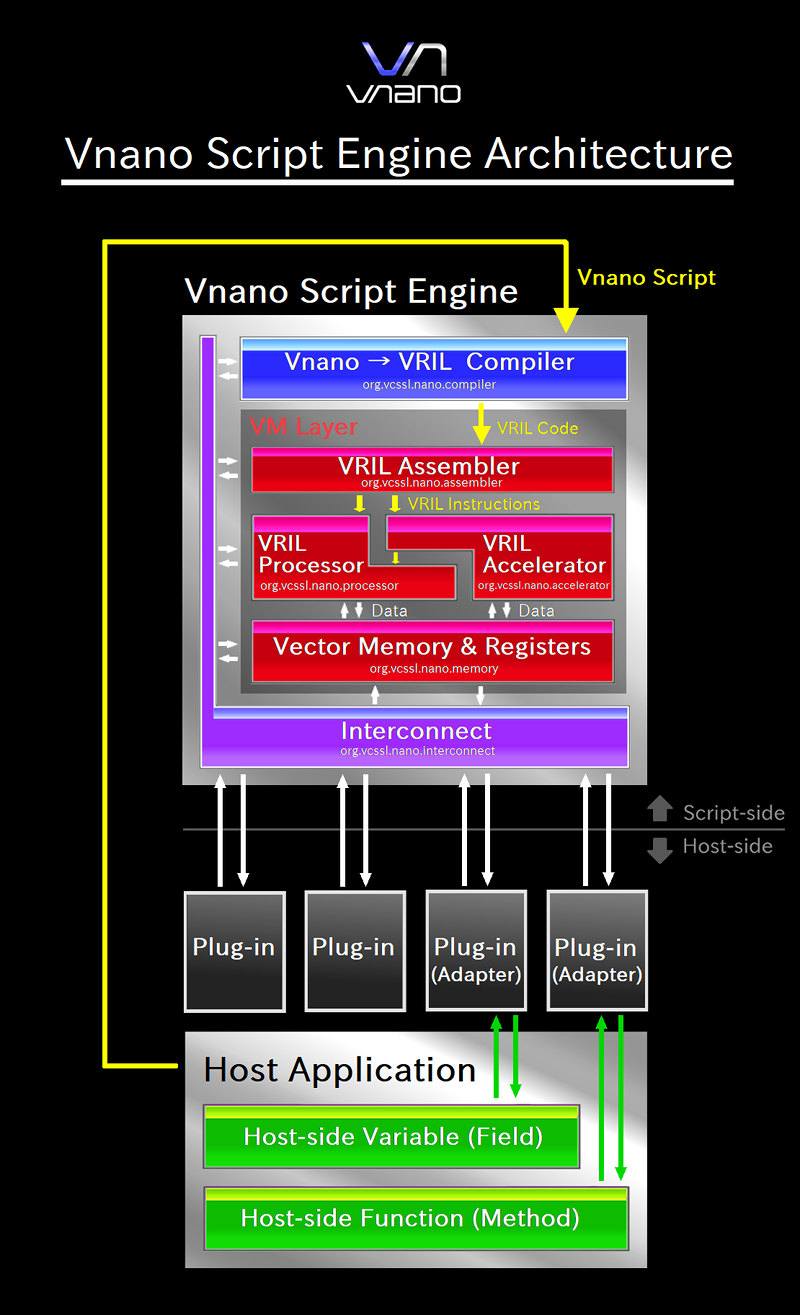
一気にカラフルなブロックが増えましたね。これらがスクリプトエンジンを構成する内部のコンポーネントを表しています。 一番上に「 ~ Compiler 」と書かれた青色のコンポーネントがあり、その下に「 VM Layer 」として囲まれた赤色の領域がある通り、 Vnano のスクリプトエンジンは、オーソドックスな「 コンパイラ + 仮想マシン(VM) 」の形式を採用しています。 ただし、VM は図の通り、さらにいくつかのコンポーネントで構成されています。
図で描かれたそれぞれのコンポーネントは、実装コードのレベルでは、それぞれ1個ずつのJavaのパッケージになっています。 そしてその中にそれぞれ、数個~数十個程度のクラスが含まれていますが、ここで全てを把握する必要はありません。 スクリプトエンジンの全体的なアーキテクチャを把握するには、この図にブロックで書いたコンポーネントくらいの粒度で十分です。
各コンポーネントの概要は以下の通りです:
ここからは、実際にスクリプトエンジンに入力されたスクリプトコードが、各コンポーネントを経て実行される具体的な流れを、上層から順に追いかけながら見ていきましょう。 以下の文中では、登場するクラス名やパッケージ名の箇所に、GitHub上の実装コードのページへのリンクを張ってあるため、必要に応じてそちらも参考にしてください。
入力されるスクリプトコードは以下の内容とします:
- 入力スクリプトコード -それでは、いまホストアプリケーションから、上記のスクリプトコードが文字列データとして、 Vnanoのスクリプトエンジン実装の最上層である org.vcssl.nano.VnanoEngine クラスの executeScript(String) メソッドに渡されたとしましょう。 するとスクリプトエンジン内部で何が起こるでしょうか? 以下で見ていきます。
入力されたスクリプトコードはまずコンパイラを通り、そこで中間コードの一種である「 VRILコード 」に変換されます。 VRILは「 Vector Register Intermediate Language 」の略で、Vnano のVMへの動作指示に用いる中間言語です。すぐ後で実際の内容を掲載します。
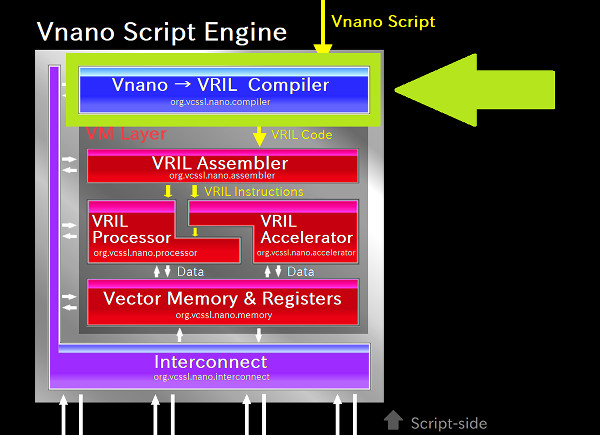
コンパイラを構成するのは org.vcssl.nano.compiler パッケージ内のクラス群ですが、 上層から直接呼ばれるのは Compiler クラスの compile メソッドです。 このメソッドは、引数として文字列のスクリプトコードを受け取って(※他にも引数はあります)、 それをコンパイルした結果のVRILコードを文字列として返します。
いまの例の場合における、具体的にコンパイルされたVRILコードは:
- VRILコード(コンパイラの出力) -といった具合の内容です。
先にも少し触れましたが、このVRILコードは、後のステージのVM(プロセス仮想マシン)への動作を指示する命令列が記述されたものです。 ただし、この段階ではまだ、人間に対して可読なテキスト形式で表現されています。デバッグ時などに、その気になれば手書きで編集する事も可能です。 つまりVMに対するVRILコードは、現実のCPUに対するアセンブリコードと同じような関係です。 実際、開発初期にはVRILという名称は決まっていなかったため、いくつかのコード内コメントなどでは、VRILコードの事を「 中間アセンブリコード 」と呼んでいる箇所も残っています。
なお、テキスト形式の中間コードは、そのまま直接的にVMを動作させるには無駄が大きいので、最終的にはよりVMにとって効率的なオブジェクトに変換されます。 間にこのようなテキスト形式の中間表現を挟んでいる理由は、スクリプトエンジンの開発およびデバッグ時の利便性のためです。
VnanoのVMはレジスタマシンの一種なので、VRILコードの「雰囲気」は、現実のCPUに対するアセンブリコードに結構似ています。 ただしもちろん、現実のアセンブリほどCPUやバイナリに直結した記述ではなく、例えるなら「 ある程度の厚さの抽象化レイヤーを挟んだアセンブリ 」といった雰囲気です。 しかし基本的な感覚はそこそこ共通しています。 「 # 」で始まる行を除けば、1行が1命令に対応していて、「 ADD 」命令は加算を行う、「 MOV 」命令はデータのコピー(転送)を行う、「JMP」命令は別の命令アドレスの位置に飛ぶ、などです。
ここから先は、VM内の処理に入ります。 少し上で掲載したブロック図の通り、VMはさらに複数のコンポーネントで構成されています。 VMの最上層の VirtualMachine クラスは、それらのコンポーネントの処理をまとめて包んでいるだけの、非常に短い実装コードのクラスです。 VMよりも上の層からは、このVirtualMachineクラスに先ほどのVRILコードを渡すだけで、それを実行してくれます。 つまりその粒度で見ると、もうここでスクリプトの実行フローは終了です。 ただ、それだとあまりにもVMがブラックボックス過ぎるので、以下ではVM内に入って処理を追ってみましょう。
VRILコードはテキスト形式なので、既に少し触れた通り、そのまま逐次的に解釈して実行するには結構な無駄が生じます。 そこでVM内では、まず渡されたVRILコードをアセンブラに通して、より解釈&実行の効率を重視したオブジェクトに変換します。
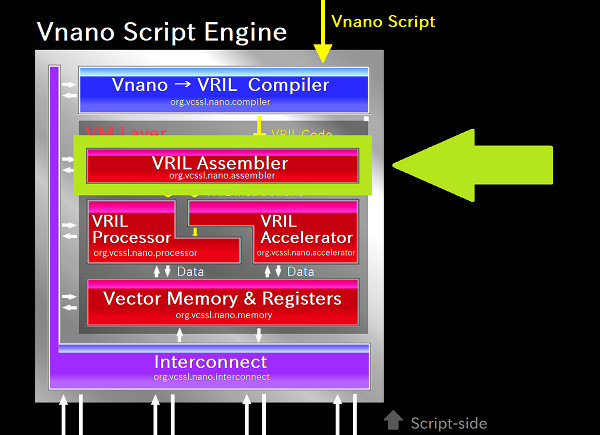
アセンブラを構成するのは org.vcssl.nano.vm.assembler パッケージで、 上層から直接呼ばれるのは Assembler クラスの assemble メソッドです。この引数に、先ほどのVRILコードが渡されます(他にも引数はあります)。
アセンブラの出力は VirtualMachineObjectCode クラスのインスタンスで、これを「 VMオブジェクトコード 」と呼びます。 VMオブジェクトコードはテキスト形式ではありませんが、デバッグのためにテキストとしてダンプする事ができます。 いまの例の場合では、以下のような内容になります:
- VMオブジェクトコード(アセンブラの出力)をテキストとしてダンプした内容 -VMオブジェクトコード内には、ラベルの命令アドレスや、シンボルテーブル、定数定義など、いくつかのセクションがあります。 その中で最も重要なのは、先頭にあって「 #INSTRUCTION 」で始まっている、命令列のセクションの内容です:
- VMオブジェクトコード内の命令列(テキストとしてダンプ) -このセクションは、(ダンプ前の)実際のデータとしては Instruction クラスのインスタンスの配列で、上の内容は、それを1行に要素1個ずつダンプしていったものになっています。 ただし左端に、配列内でのその命令のインデックス = 命令アドレスが記載されています。
Instruction クラスは、VMの単位動作を指示する、命令1個としての役割を担うクラスです。 VM(内の仮想プロセッサ、後述)は、この Instruction クラスの配列を先頭から逐次的に実行するようになっています。 オペコードやオペランドの情報はこの Instruction クラスのインスタンスフィールドとして保持されています。
さて、上の命令列セクションの内容は、先のVRILコードにおいて、「 # 」で始まる行を除いた、つまり命令行のみを抜き出した内容とよく対応しています。 両者を見比べると、VRILコードでは「 _sum@0 」や「 _i@2 」のように、オペランド部に元のスクリプトコード由来の識別子が含まれていたのが、 アセンブル後の命令列セクションでは「 L0 」や「 L2 」のように、完全に機械的な番号コードに置き換わっていますね。 また、VRILコード内での「 ~int:100 」は整数の即値(リテラル)の100を表していますが、これも「 C3 」に置き換わっています。分岐先ラベル「 &LABEL2 」なども同様に「 C6 」になっています。
この「 L0 」や「 C3 」などの機械的な番号は、データ(や分岐先の命令アドレス値など)が、VMの仮想的なメモリー内に格納されている場所のアドレスを表しています。 プレフィックスとして付いている「 L 」や「 C 」は、その仮想メモリー内での領域(パーティション)を表しています。 なお、アセンブルによってオペランドの個数が増えているのはメタ情報(エラー発生時などに参照されます)の分なので、あまり深い意味はありません。
このように、VRILコードの段階では、まだ可読性をいくらか考慮して識別子&ラベルベースだったオペランドが、 アセンブル後は完全にアドレスベースに置き換えられます。 また、ダンプした結果ではわかり辛いですが、オペコードや型指定も、文字列ベースから列挙子ベースに置き換わっています。
さて、いよいよVMの中心的な処理です。VM内で、CPUのように命令を逐次的に解釈して実行する機能を担うコンポーネントを、 Vnano では仮想プロセッサと呼びます。 わざわざVM自体とは異なる呼び方をするのは少し紛らわしいですが、Vnano のVMでは、コンポーネントとしてアセンブラや仮想的なメモリーも含まれているため、 CPUとしての機能部位を担うコンポーネントを明確に指す際に仮想プロセッサという呼称を用います。
仮想プロセッサを構成するのは、基本的には(※詳細後述) org.vcssl.nano.vm.processor パッケージで、 上層から直接呼ばれるのは Processor クラスの process メソッドです。
この process メソッドの引数に、先ほどのVMオブジェクトコード内の命令列( 型は Instruction [ ] )が渡されます。 すると仮想プロセッサは、命令列の先頭から順に、命令を1個ずつ解釈し、相当する処理を行います。 それを命令列の末尾までくりかえします。 ただし、JMP/JMPN命令などの分岐系の命令があった場合には、その次に実行される命令の位置は goto 的に飛んで、 飛び先からまた末尾に向かって1個ずつ命令を処理していきます。 最終的に末尾に達すると終了です。
機能的には、仮想プロセッサが行う事はたったこれだけで、重要そうなイメージとは裏腹に、非常に単純です。
一方で、この「 命令を1個ずつ解釈し、相当する処理を行う 」という単純なサイクルを、どれだけ速く回せるかが、スクリプトの処理速度を大きく左右します。 単純に実装するととても遅く、そして速度を求めると、実装コードがケースバイケースで最適を目指した類似処理の羅列になり、煩雑で肥大化したものになってしまう箇所でもあります。 そのようなトレードオフが存在するため、Vnano のVMは、2種類の仮想プロセッサ実装を持っています。それらは仕様上は同機能ですが、動作の仕組みは全く異なります。
上で述べた org.vcssl.nano.vm.processor パッケージは、速度よりも単純さを優先した仮想プロセッサの実装を提供するものです。 具体的には、while 文で命令列を1個ずつ読んでいき、switch 文で命令のオペレーションコードに応じて分岐して、対応する処理を実行する、という、直球な実装方法を採用しています。 実装がシンプルな反面、処理速度は、倍精度浮動小数点演算のピーク値で数MFLOPS~数十MFLOPS程度までしか出せません。
もう一方の、org.vcssl.nano.vm.accelerator パッケージは、逆に単純さよりも速度を優先した仮想プロセッサの実装を提供します。 こちらは、「命令列内の個々の命令の処理内容に対応するように、機能分化した演算ノードのサブクラス群のインスタンス」を生成し、それを命令列と同順序で結合した上で、 順々に演算実行メソッドを呼び出していく事で処理を行います。これは主に分岐コストを低減するためで、併せて他のオーバーヘッド低減策や、各種の最適化も行われます。 結果として、数百MFLOPS~数GFLOPS程度のパフォーマンスを発揮します。 一方で、実装コードは複雑なものとなっています。
Vnanoのスクリプトエンジンでは、デフォルトでは後者(高速版)が使用されるようになっていますが、オプションで完全に無効化できます。すると、前者が使用されるようになります。
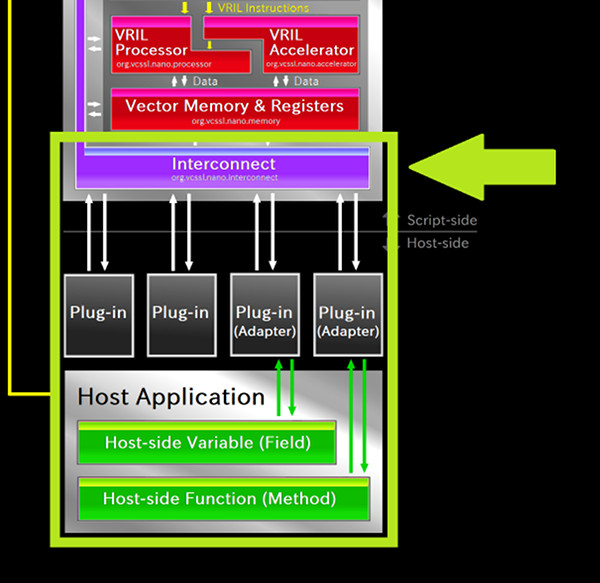
ブロック図的には次は仮想メモリーですが、こちらは単に仮想プロセッサの要求通りにデータを受け渡しするだけなので割愛し、最後に インターコネクト に触れておきましょう。 インターコネクトは、これまでに列挙した各コンポーネント間で共有される、いくつかの情報を管理・提供する機能を担います。
いまのVMの命令列の例では、命令列の末尾を表すEND命令を除けば、実質的な最後の命令は CALLX 命令です。 VRILコードでは:
です。 これは入力スクリプトコード内での最終行「 output(sum); 」の処理に対応していて、 スクリプトエンジンに接続された外部関数 output をコールする内容の命令です。
アセンブル後は、関数シグネチャ「 _output(int) 」の部分は、関数を識別するための整数番号「外部関数インデックス」が格納されている、仮想メモリー内でのアドレス(ややこしいですね) C11 に置き換えられます。 引数の「 _sum@0 」も、既に見たようにアドレス L0 に置き換えられます:
なお、N0 は戻り値が空の箇所をうめるプレースホルダ、C10はメタ情報です。これらは重要ではありません。
さて、仮想プロセッサがこの命令を読むと、まず仮想メモリーにアドレスで問合せて、オペランドの実データを取得します。 いまは関数 output の外部関数インデックスと、変数 sum の値ですね。 そしてそれらを、インターコネクトの最上層クラスである Interconnect のインスタンスの call メソッドに渡します。
すると、インターコネクト内の外部関数テーブルから、対象の関数が検索されて実行されます。 外部関数テーブル内では、関数は AbstractFunction クラスの形で保持されており、実行の際は invoke メソッドが呼ばれます。
この AbstractFunction は、Vnano のスクリプトエンジン内部における関数の抽象クラスです。 外部関数は、スクリプトエンジンに接続される際、この抽象クラスを継承したアダプタでラップされて接続され、外部関数テーブルに格納されます。 そしてアダプタは、継承している AbstractFunction の invoke メソッドが呼ばれると、自身がラップしている外部関数を実行するように実装されています。 それによって、いまの場合はスクリプトエンジンに外部関数として接続された output メソッドが実行されるわけです。 これは、受け取った引数の値にメッセージを付けて標準出力に出す内容のメソッドなので、標準出力に以下の結果が出力されます:
冒頭でもスクリプトの実行結果として見た内容ですね。
以上で、スクリプトエンジンにコードが入力されてから、内部で変換 & 実行されて、処理が最終的にコード末尾に至るまでの流れを、一通り追いかけて見た事になります。 今回は、Vnano のスクリプトエンジンの全体的なアーキテクチャの解説が対象だったため、各コンポーネントにあまり深入りせずに飛ばし気味でしたが、 いかがだったでしょうか。
次回のアーキテクチャ解説では、コンパイラをクローズアップして、より深く掘り下げて見ていきたいと思います。
※1: OracleとJavaは、Oracle Corporation 及びその子会社、関連会社の米国及びその他の国における登録商標です。文中の社名、商品名等は各社の商標または登録商標である場合があります。
