
今回は前回の続きで、現在オープンソースで開発中の、 アプリケーション組み込み用の小型スクリプトエンジン「 Vnano 」のアーキテクチャを解説します。
この解説は数回の連載を予定しています。 第1回となる前回では、まずVnanoそのものの概要を紹介した上で、 スクリプトエンジン全体のアーキテクチャを俯瞰的に眺めながら、入力されたスクリプトコードが最終的に実行されるまでの過程を大まかに解説しました。 詳細は前回の記事(以下)をご参照ください:
第2回となる今回は、スクリプトを中間コードへと変換する、コンパイラ部分の内部をクローズアップして解説します。
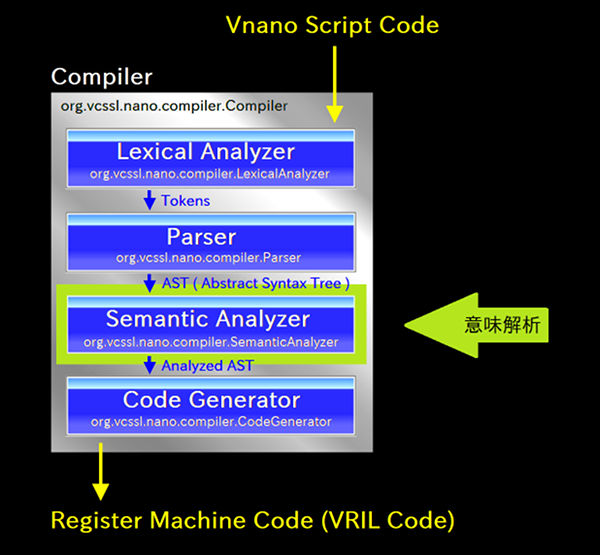
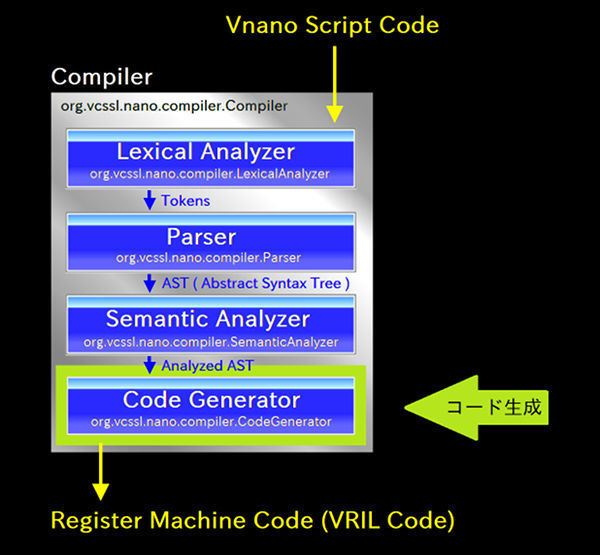
まずは、スクリプトエンジン内でのコンパイラ部分の役割を簡単におさらいするため、 前回図示した、スクリプトエンジン全体のアーキテクチャを表すブロック図を再び見てみましょう:
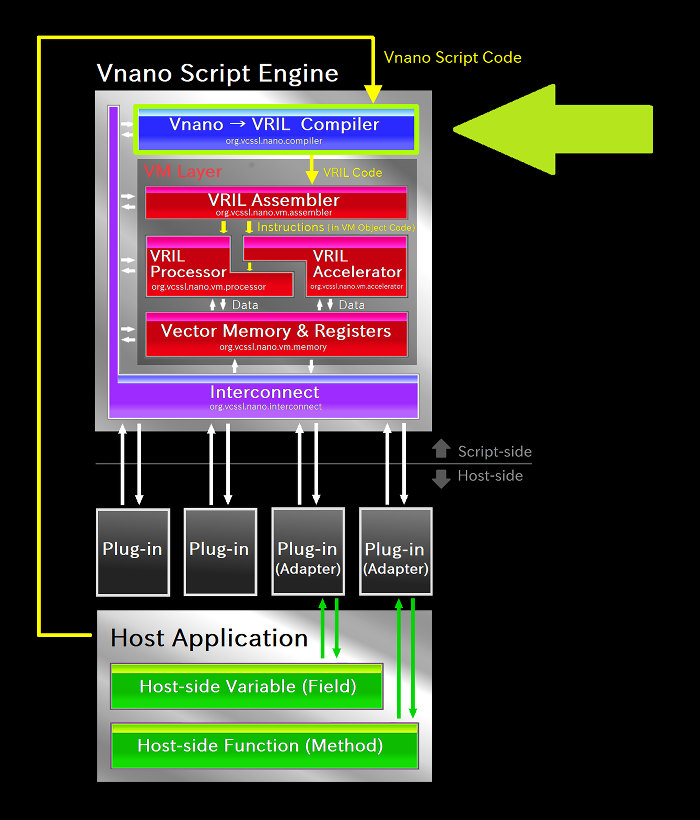
上図において、上側にある銀色の四角いのパネルがVnanoのスクリプトエンジン(Vnano Script Engine)、 下側にある銀色の四角いパネルがホストアプリケーション(Host Application, スクリプトエンジンを搭載して使用するアプリケーション)です。 スクリプトエンジンのパネルに注目すると、その中にさらにカラフルなブロックがいくつも描かれていますが、 これがスクリプトエンジン内の内部構造を大まかに表しています。 最上部には青色で「 Vnano → VRIL Compiler 」と書かれたブロック(緑色の大きな矢印で指されています)があり、 これが今回の注目対称であるコンパイラを表しています。
図に黄色い矢印で描かれている通り、ホストアプリケーションからスクリプトエンジンへと渡された Vnano のスクリプトコードは、 エンジン内ではまずコンパイラに入力されます。 そしてそこで「 VRIL(Vector Register Intermediate Language, ベクトルレジスタ中間言語) コード 」という、 レジスタマシン用の一種の中間コードへと変換されます。
具体例を見てみましょう。以下の内容のスクリプトコードが入力されたとします:
- 入力スクリプトコード -このスクリプトコードがコンパイラを通ると、以下の内容のVRILコードへと変換されます:
- VRILコード(コンパイラの出力) -このように、全く違う雰囲気のコードになりましたね。 Vnano のスクリプトエンジンは、スクリプトコードをそのまま解釈・実行するのではなく、 コンパイラで一旦このような中間言語のコード(VRILコード)に変換してから、それをレジスタマシン型のVM(プロセス仮想マシン)上で解釈・実行します。 このあたりの全体的な流れについては、前回の記事をご参照ください。
ここで、「 何故わざわざコンパイラで別の中間言語に変換してから実行するのか? 」という疑問が湧くかもしれません。 このような「 コンパイラ+VM 」方式(中間コード方式など、呼び方は色々)の構成は、 言語処理系として特に珍しく無いオーソドックスな形の一つで、 採用される理由は恐らくケースバイケースで数多く挙げられると思います。 その中で具体的に、Vnano でこの方式を採用した大きな理由となっているのは、 処理速度上で優位性が見込める事と、処理手順を細かく砕いた中間コードを介する事でデバッグを容易にしたかったため です。 他にもいくつかメリットがありますが、メインはこの2点です。 処理速度については、単純にコンパイラ+VM方式を採用すれば伸びるというものではなく、 逆にVMを高速化しやすいように中間コード言語の仕様を決める事が恐らく大切なのですが、それについてはまた後の回で解説します。
余談ですが、スクリプト言語処理系のアーキテクチャとしては、コンパイラ+VM方式の他にもよく採用される、 「 ASTインタープリタ(構文木インタープリタ) 」という方式があります。 これは、入力されたコード内容を抽象構文木(AST)という木構造で表してから、それをそのまま実行するものです。 この方式にも色々な利点があるのですが、それは置いておいても、 概念上の構造が比較的シンプルであるため、簡易スクリプト言語を自作する際に採用される事も多いと思います。
コード内容を抽象構文木(AST)という木構造で表す 」という処理は、 実はコンパイラでも行う処理で、むしろ結構な割合を占めます(すぐ後で詳しく見ていきます)。 従って今回の内容は、「 ASTインタープリタ方式でスクリプト言語を自作してみたい 」といった方にも、もしかすると参考になるかもしれません。
それでは、コンパイラの内部構造を詳しく見ていきましょう。 まずは、先ほどのブロック図から、コンパイラ部の内容をさらにクローズアップした図を見てみましょう:
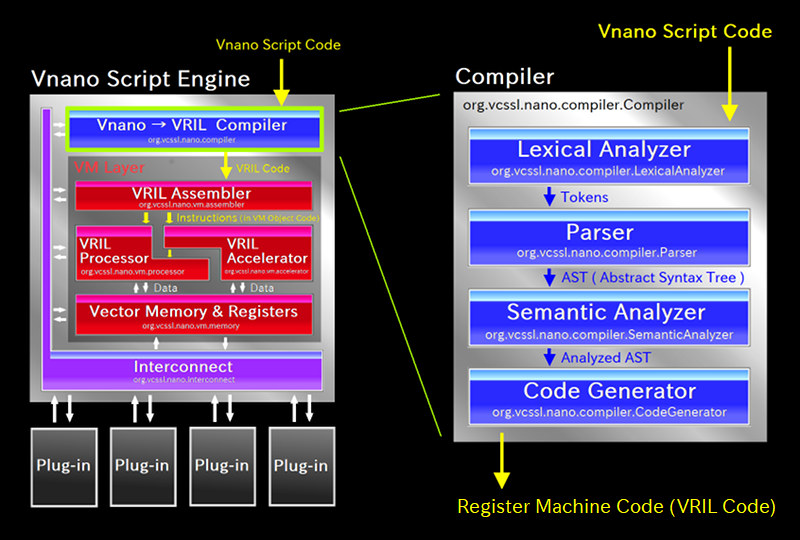
上図の左半分は、先ほども見たVnanoのスクリプトエンジン全体のブロック図そのままです(ホストアプリケーション部は削っています)。 そして右半分が、そこからコンパイラ部をクローズアップし、内部をさらに細かく描いたブロック図になっています。
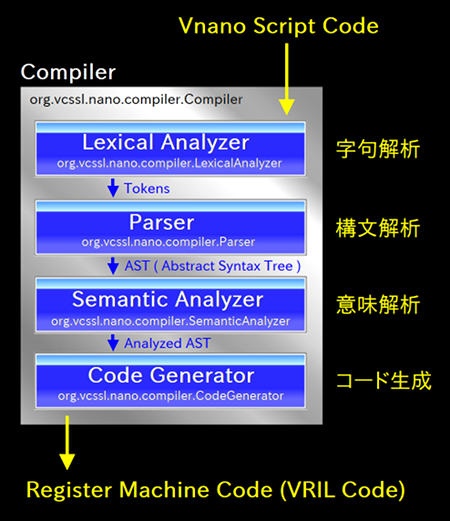
図の通り、コンパイラ内は大まかに見て、4つの主要なコンポーネントで構成されています。 これらはそれぞれ1個ずつクラスとして実装されています。 各コンポーネントの概要については以下の通りです:
ここで挙げた主要コンポーネントの名前と処理内容などは、Vnano に特有のものではなく、 一般的なコンパイラにおいてもある程度共通している概念です。 もちろん、コンパイラの実装の仕方においては、パーサがレキシカルアナライザを兼ねていたりなど、コンポーネントの区切り方が少し違う場合もあります。 しかし、コンパイラが行う処理を必要最低限なレベルで分解すると、 大まかには上で挙げた通り、「 字句解析 → 構文解析 → 意味解析 → コード生成 」という流れに沿ったものになっています。
よりパフォーマンスを重視した実践的なコンパイラでは、各処理の間に「 最適化 」の処理や、 そのための中間表現などが加わる事も一般的です。 Vnanoでは現時点ではとりあえず安定させる事を重視しているため、デバッグが難しくなるコンパイラ側での最適化は行っていません。 代わりに、VM側である程度局所的な最適化を行っています。
以下では前回と同様に、入力されたスクリプトコードが、 コンパイラ内のそれぞれの主要コンポーネントで、どのように変換されていくかを追いかけながら、 処理内容をより具体的に見ていきます。
コンパイラに入力されるスクリプトコードは、以下のような単純な内容としましょう:
- 入力スクリプトコード -ちなみに実行結果は「 579 」です。
このコードのコンパイル過程を解析するには、Vnanoのスクリプトエンジンに用意されている、 開発/デバッグ用にコマンドラインからスクリプトコードを実行するモードを使用すると便利です。 その際に「 --dump 」オプションを指定する事で、 コンパイル過程や実行用の命令列など、処理系内部での中間的なデータを見る事が可能です (方法については Vnano のリポジトリのREADME をご参照ください)。
ただ、実際やってみるとわかるのですが、上のような短いコードでも、コンパイル途中での中間的なデータは、意外と数十行くらいある長さになってしまいます (実際の内容はこちら / 「Tokens」や「Parsed AST」などのセクション)。 そこで話を簡単にするために、さらにコード内の以下の一行のみに注目して、それがどう変換されていくかを追いかける事にしましょう:
- 入力スクリプトコードの注目行 -なお、仮にこの一行のみを単体で実行しようとしても、変数 foo と bar が宣言されていないためエラーとなってしまいます。 以下ではあくまでも、「 先のコード全体が入力された場合において、その中で、上記の一行に対応する部分の変化を追いかけていく 」 という前提で話を進めていきます。
これ以降は、文中のクラス名などにはソースコードへのリンクが張られていますので、必要に応じてご参照ください。
さて、まずはコンパイラの各コンポーネントをまとめている外枠である、最上階層を見ておきましょう。 Vnanoのスクリプトエンジンにおいて、コンパイラ部を構成するクラス群は org.vcssl.nano.compiler というパッケージにまとめられていますが、 その中に Compiler という、そのものずばりの名前のクラスがあります。これがコンパイラの最上階層です。
「 コンパイラにスクリプトコードが入力される 」というのは、具体的には この Compiler クラスの compile メソッドが呼ばれて、その引数にスクリプトコードが渡される 事に対応します。 コンパイル処理はここを起点として始まります。 この compile メソッド内では、必要に応じて中間表現をダンプしながら、 主要コンポーネントであるレキシカルアナライザやパーサなどのインスタンスを生成し、 先に述べたように「 字句解析 → 構文解析 → 意味解析 → コード生成 」の処理を順に実行しています。
それでは、主要コンポーネントの処理を追いかけていきましょう。 まずは最初の、レキシカルアナライザによる字句解析のステージです。 レキシカルアナライザは LexicalAnalyzer クラスとして実装されていて、その analyze メソッドが呼ばれる事で、字句解析の処理が実行されます。
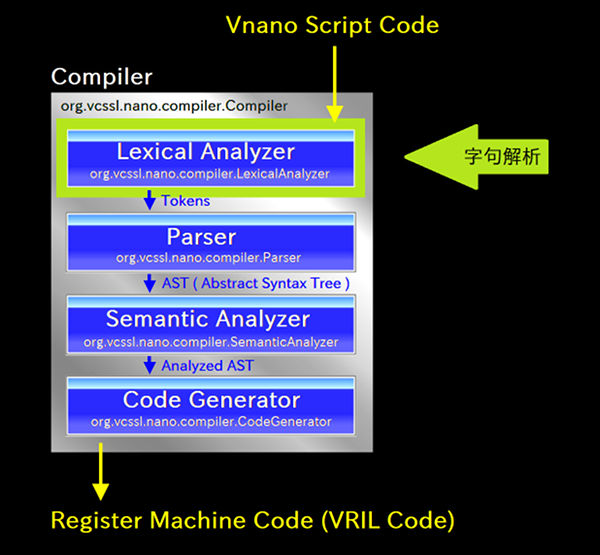
ここで「 そもそも字句解析が何をやる処理なのか 」について軽く触れておきましょう。 コンパイラに入力されるコードは、データ的には一連の長いテキスト、つまり「 文字が大量に並んだ列 」ですね。 一方で、その中の文字は、必ずしも1文字ずつが独立に意味を持っているわけではなく、 「 int 」などのように複数の文字で1つの意味を持っている「 文字のまとまり 」が多々あります。 そこで、このように意味的な単位となる文字のまとまりを「 トークン(Token) 」や「 字句 」と呼びます。 イメージ的には要するに、英文における単語のようなものですね。 もちろん「 + 」演算子のように、1文字で意味を持っているものもありますが、それも文字数が1のトークンと見なします。
コンパイラの内部処理は、要するに「 まずコード内容を読んでプログラムとしての意味を解釈し、そしてそれを別の言語で書き直す 」という事をやるのですが、 字句解析はその最初の段階として、コード内容をトークン単位に分割 します。 具体的に、いまの場合における、コード内の注目行の内容 「 foo = bar + 456; 」 は、以下のようなトークン(Token)の列に分割できます:

実際に LexicalAnalyzer クラスによる字句解析結果を文字列としてダンプした結果は:
- 字句解析結果を文字列としてダンプした内容 -のようになります。実際には字句解析結果は Token クラスのインスタンスの配列なのですが、上記はそれを1行につき1要素(1トークン)の形で、内容を文字列として表したものです。
Tokenクラスは値をいくつも持っているため、内容が横に長くて読むのが嫌になりそうですが、 先頭(左端)付近の「 word=… 」の箇所が、トークンを構成する文字列を表しています。 この箇所を上の行から順に見ていくと、「 foo 」「 = 」「 bar 」「 + 」「 456 」「 ; 」となっています。 ちゃんと元のコードの内容が、トークンに分割されていますね。
他に右の方にずらっと並んでいる値は、後でパーサの構文解析処理を手助けするための情報です。 具体的には、トークンの種類や、演算子の場合は優先度、リテラルの場合はデータ型など、ケースバイケースで色々です。 Vnanoのコンパイラでは、 「 複雑性が深刻化しがちなパーサの負担をなるべく抑えたいため、レキシカルアナライザで分かる範囲の情報は頑張って調べて、トークンに持たせてからパーサに渡す 」 という方針の設計になっています。 そのため、前後や離れたトークンの並びによって決まる、単純な字句解析の範囲を少し超えるような情報も、ある程度はレキシカルアナライザが頑張って調べます。 それにより、パーサはASTの構築に専念します。
次は、パーサによる構文解析のステージです。 パーサは Parser クラスとして実装されていて、その parse メソッドが呼ばれる事で、構文解析の処理が実行されます。
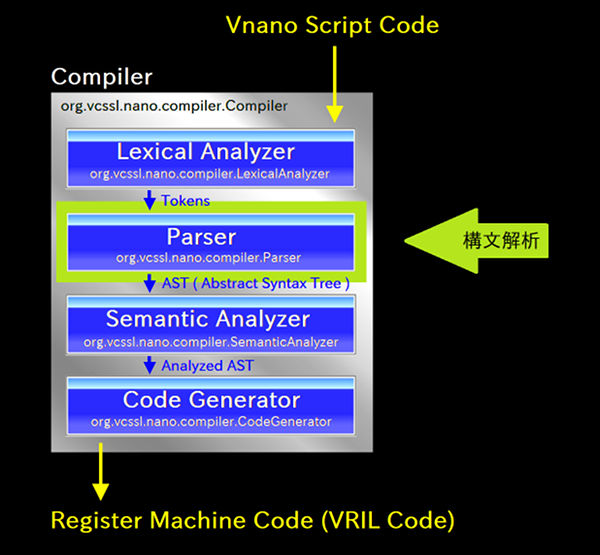
この構文解析のステージでは、 まず字句解析によって得られたトークン列の並びを解析し、 それが文法的に何であるのかを解釈します。 例えば「 int 」「 x 」「 ; 」ならそれは変数宣言文ですし、「 if 」「 ( 」 … と続くなら if 文ですね。 文の粒度で解釈するだけではなく、式の中身なども細かく解釈します。 演算子や末端の数値に至るまで、とにかくすべてを文法的に何であるか解釈します。
式の解釈は結構大変です。 ちょうど、いま追いかけている「 foo 」「 = 」「 bar 」「 + 」「 456 」「 ; 」の例だと、文の内容全体が式ですね( こういうのを式文といいます )。 この例だと、「 + 」演算子は「 bar 」と「 456 」にかかっていて、さらにその結果と「 foo 」に対して「 = 」演算子がかかっていて … などなどを解釈する必要があります。 さて、そのような解釈ができたとして、その結果を果たしてどのようなデータ構造で表せばよいでしょう? こういう、「 どれがどっちにかかって 」だとか、「 その結果がさらにあっちにかかって 」だとかを表すには、 少なくとも単純な配列などでは不都合そうですね。そこで、ツリー構造で表します。そうすると各要素の関係が色々と都合よく表せます。 今の例だと下図のような形になります:
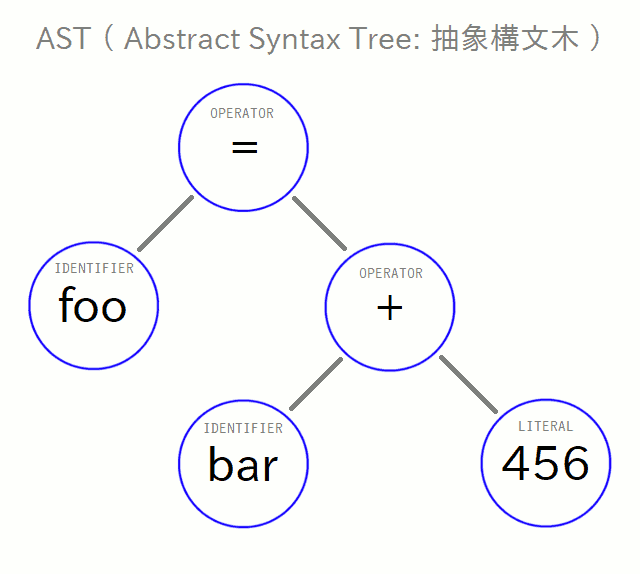
このように、構文解析によって解釈した内容をツリー構造で表したものを「 構文木 」と呼びます。 いまの場合はもう少し狭いカテゴリーの「 抽象構文木、Abstract Syntax Tree 」というもので、 略してASTと呼びます。
つまるところ、入出力のみに注目すれば、トークン列を解釈してASTを構築するのが、ここでのパーサの役割です。 実際に Parser クラスによる構文解析結果を文字列としてダンプした結果は:
- 構文解析結果を文字列としてダンプした内容 ( 属性値は少し並びかえてあります ) -のようになります。実際には構文解析結果は AstNode クラスのインスタンスをノードとする、ツリー状に結合されたオブジェクトなのですが、 上記はそれを、ダンプ用にXML風の形で文字列として表したものです。 OPERATORタグは各種演算子のノードを表しています。LEAFタグはリテラル( LEAF_TYPE 属性が "literal" )や変数識別子( 同じく "variableIdentifier" )などが属する種類のノードです。
上のダンプ内容は、各行において最初の属性(OPERATOR_SYMBOL や IDENTIFIER_VALUE など)にトークン内容に対応するものが来るように、 属性の順序を少し(手で)並びかえてあるので、そこに注目すると、図の通りのツリー構造が構築されている事が見て取れると思います。
続いて、セマンティックアナライザによる意味解析のステージです。 セマンティックアナライザは SemanticAnalyzer クラスとして実装されていて、その analyze メソッドが呼ばれる事で、意味解析の処理が実行されます。
このステージで行う処理は、他のステージと比べるとメリハリが弱いため、掴みどころが薄い印象になってしまうかもしれません。
具体的には、構文解析で構築されたASTを辿って、より深いレベルで内容(意味)を解釈し、 それによって分かった情報を補完したり、おかしい事を行っている箇所はエラーにしたりします。 ただ、実際にここでどの程度の事を行う必要があるのかは、恐らく言語仕様や実装の方針によってだいぶ異なると思います。 どちらかというと、後の工程(コンパイラなら中間コード生成、ASTインタプリタなら実行など) において必要になる情報を色々と求める処理といったイメージの方が、実際に実装する時の感覚に(個人的には)近いかもしれません。
という事で、概念的な説明よりも、実際にVnanoのコンパイラにおいてこのステージで行っている事の例を見てみましょう。 まず入力として、先ほど構文解析によって構築された「だけ」の状態のASTが入ってきます。 先ほどの図では省略しましたが、今度はデータ型についても意識したいので、入力時点で分かっているデータ型を赤色で追記してみます:
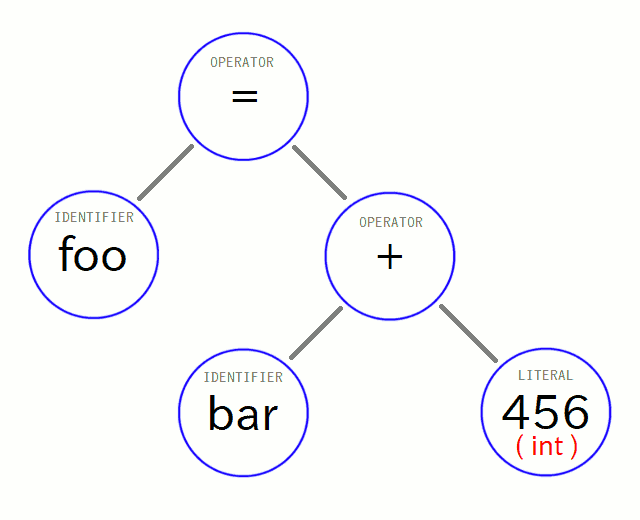
この通り、「 456 」が int 型である事は最初から分かっています。 これはもうトークンの内容から整数である事が自明なので、だいぶ前の字句解析の段階から既知です。 ただ、他のノードに関してはこの段階ではまだ未知です。 一歩手前の構文解析のステージが行うのは、文法に基づいてASTのツリー 「 構造 」 を構築するまでで、(少なくともVnanoでは)それより深い事は行わないからです。 つまり、「 式の中で参照している変数がどの型で宣言されているか 」などを調べてきて、 参照しているノードに補完したりといった事は、まだ行われていないのです。よって「 foo 」や「 bar 」の型は未知です。
さて、仮にこの段階だけの情報で、次のコード生成のステージに処理を渡そうとると、まず「 + 」ノードの箇所の加算について、情報が足りずに困ります。 というのもVnanoでは、 整数同士の加算は普通に整数演算で、整数と浮動小数点数の加算は(整数のオペランドを浮動小数点数に変換した上で)浮動小数点演算として行う必要 があります。 従って「 bar + 456 」に対応する処理のコード生成時において、 変数「 bar 」が int 型か float 型かによって、生成する命令列が違ってくるのです。
そこで意味解析の処理(の一つ)として、コード内で宣言されている変数をリストアップした上で、 参照しているノードにデータ型の情報を(属性値として持たせて)補完します:
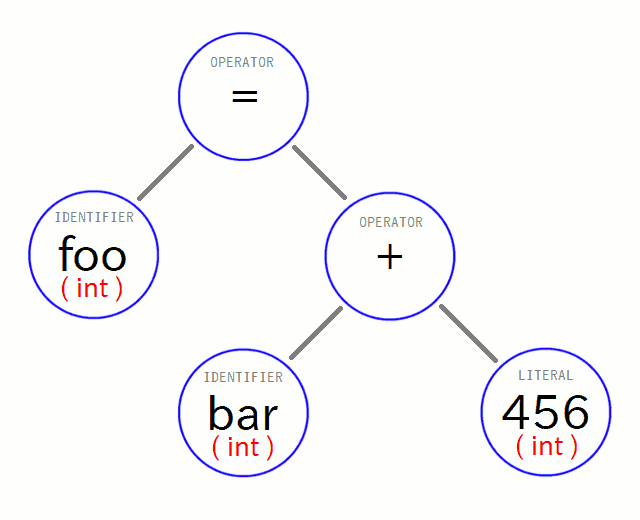
これでも、コード生成のためにはまだ少し情報が足りません。 というのも「 = 」ノードの箇所の代入処理について、両辺のデータ型の組み合わせによっては、 暗黙の型変換を行う必要があったり( = 生成すべき命令列が違ってくる )、 代入不能な組み合わせだったりするかもしれない( = コード生成に渡さずに型エラーにすべき )からです。 従って結局は、演算子ノードや、それにぶら下がっているほとんど全てのノードに、データ型情報を補完していきます。 その際の規則は、「 int 同士の加算結果は int 型 」といった具合で言語仕様で決まっているので、実際にそれに基づいて補完すると:
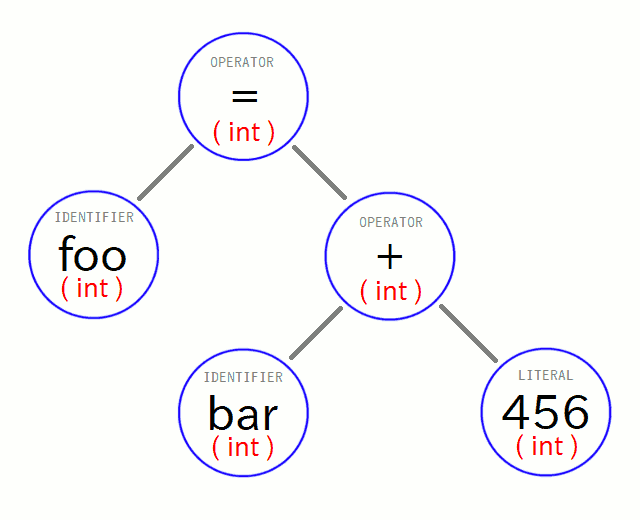
このように、いまの場合は結果的に全てのノードの値が int 型である事がわかりました ( ※ 代入演算子の値は代入結果の値で、例えば「 foo = (bar = 123); 」などとすると、まず bar に 123 が代入された上で、さらに foo にもその代入演算の値である 123 が入ります )。
以上のような具合で、このステージではASTを辿りながら色々な情報を補完していきます。 実際に意味解析済みのASTをダンプした内容は以下の通りです:
- 意味解析結果を文字列としてダンプした内容 ( 属性値は少し並びかえてあります ) -この通り、情報が補完された結果として、全てのノードが DATA_TYPE 属性( 値は "int" )を持つようになっていますね。 他にもいくつか属性が追加されています。 もし、データ型的におかしい処理を行っていたり、宣言していない変数や関数を参照していたり、 または関数呼び出しの引数の型が一致しなかったりした場合などには、この段階でエラー扱いになります。
※ コンパイル時のあらゆるエラーをこの段階でまとめて検出するわけではありません。意味まで解析しなくても構文的に明らかなエラー、 例えばオペランドが無かったり代入の左辺が無かったりする場合などは、先の構文解析の段階で検出されます。より初期の、字句解析の段階で検出されるエラーもあります。 ただ、この意味解析の段階まで済めば、入力されたスクリプトコードの「 形 」が(静的な記述構造の範囲で)正しいか間違っているかは、特殊なもの以外は概ね決まると思います。
従って、後のコード生成やVMの処理などで想定外のクラッシュを発生させずに、「 正しくエラーを吐いて処理系を停止させる 」には、 この意味解析のステージで関所のように、「 異常な状態を後工程に通さない 」という気持ちで、 様々なパターンを想定してひたすら検査しまくる事が一つの有効な方針だと思います。 もしくは逆に、ここでの検査はそう堅くせずに、VMなどでの実行時に検査するという方針も考えられます。
静的型付けで色々な面で堅い言語にしたい場合は、実行時のオーバーヘッドを減らす事や最適化の事などを考えても、この意味解析の段階で重点的に検査を行うのが有利だと思います。 一方で動的型付けで色々とダイナミックな雰囲気の言語にしたい場合は、ここでの検査や型解決などはいくらか「 保留 」して、実行時に行うのが現実的(というよりも必然的にそうなる) というケースもあると思います。その場合はこの意味解析のステージであまり仕事をしないというよりも、 意味解析が(まとまったステージではなく細切れな形で)実行処理の中にめり込んでいるというイメージになるのかもしれません。
Vnanoは静的型付けを採用している事もあり、基本的にはやや堅めの味付けで、コンパイラ側で分かるものは概ねコンパイラ側で検査する方針です。 一方で、一応はスクリプト言語の処理系であるため、ほどほどの融通を効かせるために、やはりVM側でも実行時に検査の一部を担います。
さて、いよいよ最後に、コードジェネレータによるコード生成のステージの処理を見てみましょう。 コードジェネレータは CodeGenerator クラスとして実装されていて、その generate メソッドが呼ばれる事で、コード生成の処理が実行されます。
コンパイラを要する言語には、もう一つよくある方式として、「 (ネイティブ)コンパイラ+実在CPU 」 の組み合わせがあります。 それとの対比でコンパイラ+VM方式の言語処理系を見ると、 実在のCPUの代わりに 「 仮想的なCPUをソフトウェア実装したもの = (プロセス仮想マシンとしての)VM 」 で置き換えたような形、 とも見れます。 両者において、このコード生成部で行う事は、実在であれ仮想的であれ、とにかく下層の CPU / VM が実行できる形のコードを生成する事です。
ネイティブコンパイラの場合は、ここで直接バイナリコードを生成するパターンもあれば、 まず中間言語やアセンブリ言語のコードを生成して、その後にさらにバイナリコードに変換するパターンなどもあります。 そして Vnano の場合は後者のパターンに近い形です。 Vnano のコンパイラの最終出力となるもの、つまりこのコード生成部で生成するものは、 アセンブリ言語のように、人間にとって(なんとか)可読なレベルのテキストコードです。 そしてVM側が、それを内部でよりオーバーヘッドの少ない形にアセンブルしてから実行します。
アセンブル処理がVM側の仕事なのは若干意外に思えるかもしれませんが、 もともと Vnano はスクリプトをエンジン内部で実行直前にコンパイルするため、 「 スクリプト入力 → コンパイル → VMで実行 」は手続き的には一連の処理としてまとめて行われます。 なので、アセンブル処理をコンパイラとVMのどちら側に組み込むかは、 スクリプトエンジン内の構造分割において、どこでコンパイラとVMの境界を切るかという話に過ぎません。 入出力がテキストの所で切ったほうが、開発やデバッグの効率がよさそうなのと、 どちらかを改修/置き換える際に両者間の互換性の点で楽そうなので、そうなっています。
さて、実在のCPUは普通レジスタマシンですが、Vnano の VM も一種のレジスタマシンのモデルを採用しています。 そのため、何らかのアセンブリ言語に触れた事のある方は、ここでのコード生成結果も、なんとなく雰囲気で読めるものになっているかもしれません。
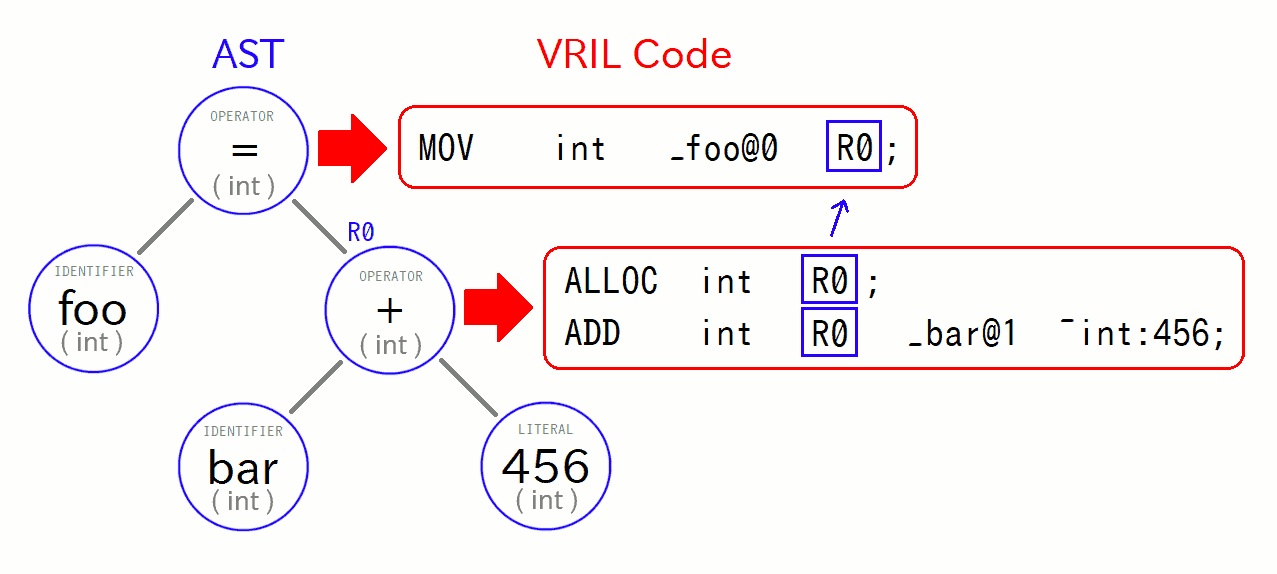
実際に、いま追いかけている、スクリプトコード内の注目行の内容 「 foo = bar + 456; 」 に対応する生成コードは:
- コード生成結果 ( VRILコード ) -
このような内容になります。どことなくアセンブリっぽいですね。 冒頭でも少し触れましたが、このように Vnano のコンパイラ(コード生成部)が出力したテキストコードの記述言語、つまるところ仮想的なアセンブリ言語は、 無名だとドキュメント等で困るため、 VRIL(Vector Register Intermediate Language, ベクトルレジスタ中間言語) という名前が付いています。 言語仕様はまだまとまっていませんが、命令一覧とその軽い説明などは org.vcssl.nano.spec.OperationCode 列挙子のコード内コメントに書かれています。
上の内容を解釈してみましょう。まず最初の行の「 ALLOC int R0; 」は、R0レジスタを int 型でメモリ確保する処理です。 Vnano のVMでは、レジスタを使用する前に、このようにデータ型を指定して確保しておく必要があります。その代わり、使いたい数だけ何本でもレジスタを使えます。
続く行の「 ADD int R0 _bar@1 ~int:456; 」は、変数「 bar 」とリテラル「 456 」の値を整数加算して、結果をR0レジスタに格納する処理です。 オペランドの先頭に付いているプリフィックス「 _ 」は識別子を表し、「 ~int: 」はint型の即値(リテラル)を表します。 これらはアセンブル時に仮想メモリー内のアドレスに置き換えられます。 識別子 bar の後に付いている「 @1 」は、同名の変数がスクリプト内に複数あった際に混同しないように付けている「ダブり避け」の整理番号です。
最後の行の「 MOV int _foo@0 R0; 」は、 R0レジスタの値を、変数「 foo 」に転送(コピー)する処理です。 これで、先の bar + 456 の加算結果を foo を代入できたので、無事「 foo = bar + 456; 」に対応する処理は完了です。
ここで「 最初から ADD 命令の出力先に変数 foo を指定すれば、最後の MOV は不要なのでは? 」と思われるかもしれません。 これは実際その通りです。しかし、コード生成処理の都合で、上のようにレジスタを介してワンクッション置いたほが実装が楽になるため、そうしています。 具体的には、入力されたASTのノードを辿りながら、その場その場でVRILコードを生成していっているため、 「 + 」ノードの時点では、上層の「 = 」ノードの存在などを考慮しないほうが楽なのです。 なので、各種の演算子のノードではとりあえずレジスタを確保して演算結果をそこに置くようにして、 上層のノードはそのレジスタの値を使って処理を行うように実装しています。 そうすると、各演算子ノードで生成するコードは、ある程度決まりきったパターンにできます。
ただし、このままだと実行時に無駄が多いので、VM側でアセンブル後に命令列やオペランドを並び替えたり、 不要な命令を削ったりする最適化が行われます。 実際に、上で見たVRILコードも、その段階で冗長なMOV命令が削られて、ADD命令が直接 foo に結果を格納するようになります。
だいぶ長い道のりでしたが、これで最初に入力されたスクリプトコードを、 最終的にVMでの実行用コードであるVRILコードへと変換できました。 以上が、Vnanoのコンパイラの内部処理です。
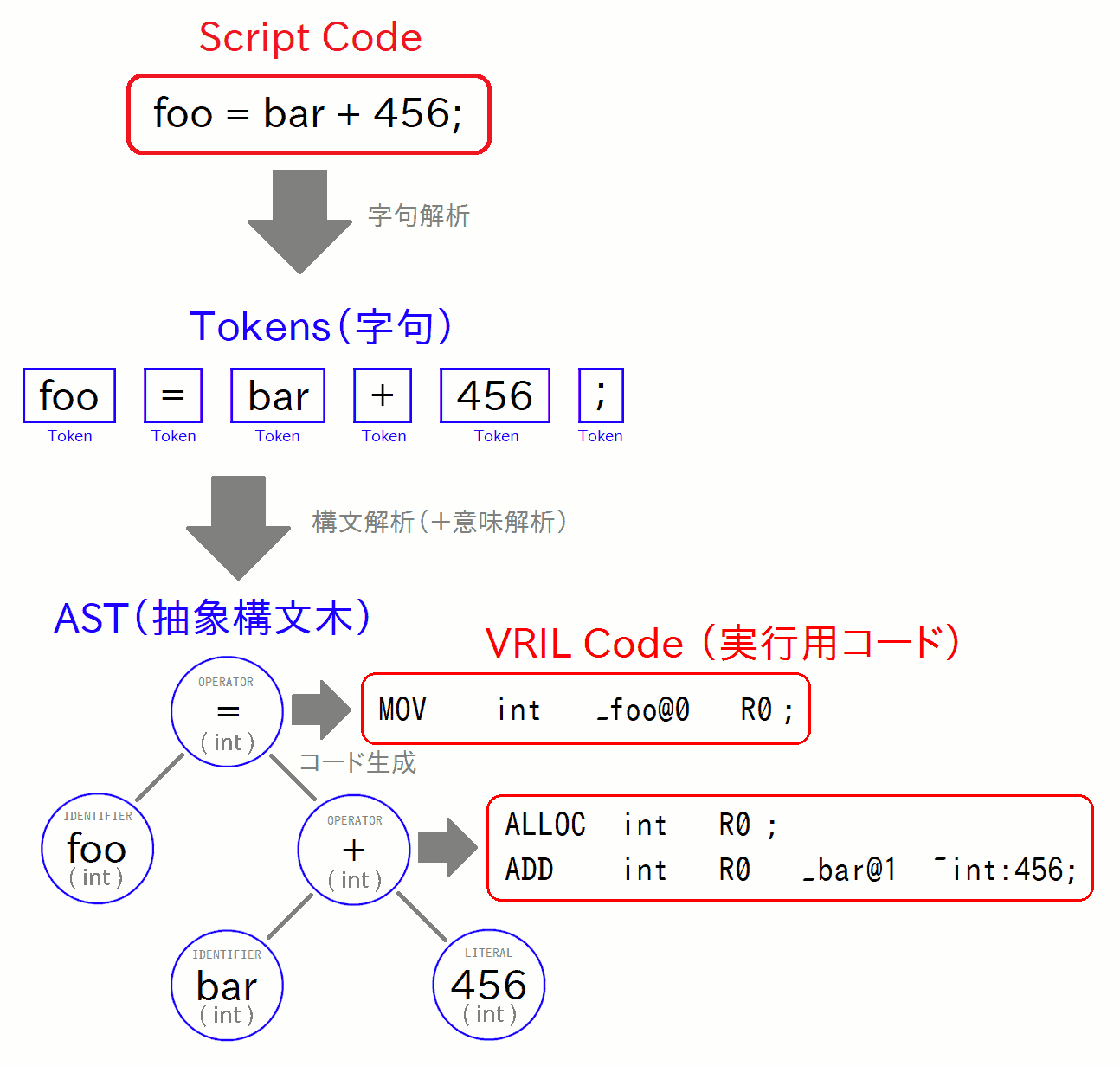
今回はなかなか複雑な内容が多かったため、最後に概要を簡単に図で振り返ってみましょう。 まず、Vnanoのコンパイラ内部は、 「レキシカルアナライザ」 「パーサ」 「セマンティックアナライザ」 「コードジェネレータ」 の4つの主要コンポーネントで構成されています。 各部ではそれぞれ「字句解析」→「構文解析」→「意味解析」→「コード生成」の処理を行っています:
そして入力されたスクリプトコードは、「トークン」→「AST」→「意味解析済みのAST」「実行用コード(VRILコード)」の順で変換されていきます:
以上です。 次回のアーキテクチャ解説では、今度は VM をクローズアップして見ていきます。
