
メリークリスマス! …まであと数日ですね。
RINEARNでは本日、アプリ内組み込み用スクリプトエンジン「Vnano」の最新版、Ver.1.1 を公開しました:
今回の更新は、前回の Ver.1.0.0 から、ソースコード上での変更は比較的小さいものです。実際、バージョンの末尾の番号だけ上げて Ver.1.0.2 として出すか迷ったくらいでした(Ver.1.0.1は開発版)。
しかし、今回は特定ケースの処理速度(同じ計算式やスクリプトの反復実行速度)が大幅に向上した事と、それ関連のオプションも追加したりと、ユーザー目線では少し重要な更新になっています。 そこで最終的には、2桁目の番号を上げて Ver.1.1.0 として出す事にしました。
という事で、この記事では、そんな Ver.1.1 で改良された点を掘り下げて解説します!
はじめに、「そもそも Vnano とは何なのか」という点について簡単にご紹介しましょう。
Vnano(ブイナノ)は、アプリ内に組み込んで、そのアプリ上で計算式やスクリプトを実行するために用いる、小型の処理エンジン(スクリプトエンジン)です。 言語的には、VCSSLという言語のサブセット(省機能版)です。
Vnano を用いた、最もシンプルで分かりやすい例として、昨年リリースした「 RINPn(りんぷん)」という関数電卓ソフトがあります。 この RINPn では、ユーザーが自由に、長い計算式を丸ごと入力して計算できます。

また、RINPn では計算式の中から様々な関数を呼べますが、その関数もユーザーが自由に自作できます。具体的には、以下のようにC言語ライクな記法でスクリプトを書いて、関数(変数も)を定義できます:
そして RINPn の中で、上で見たような計算式の処理や、スクリプトの解釈・実行を担っているのが、Vnano のスクリプトエンジンです。
電卓ソフト以外にも、アプリ内でユーザーが入力した計算式を処理したいとか、ユーザーがスクリプト的なものを書いて自動処理できるようにしたいとか、そういう状況はしばしばあるものです。 そういった処理系をゼロから実装するのは結構大変ですが、Vnano を組み込めば手軽に実現できるというわけです。Java製アプリならですが。
さて、先日のお知らせの通り、3次元グラフソフト「リニアングラフ3D」の次期版となる Ver.6 系においても、内部に Vnano が組み込まれます。
そこで Vnano が担う役割は色々とあるのですが、一番分かりやすいのは数式プロット、つまり数式のグラフを描くための処理です:
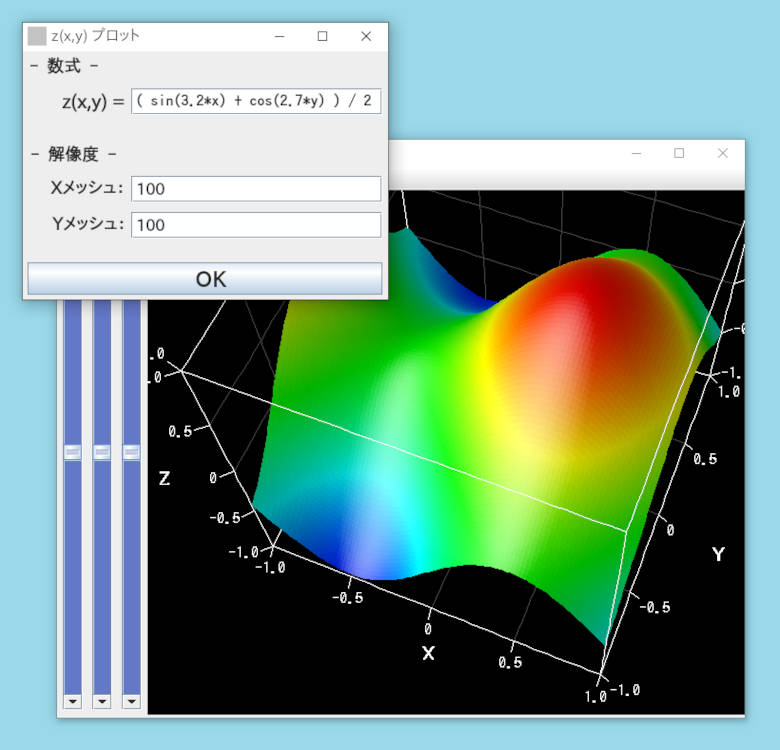
上図は、実際に開発中の次期版リニアングラフ3D上で、以下の数式:
\[ z = \frac{\sin(3.2 x) + \cos(2.7 y)}{2} \]を、xyz空間の3次元曲面としてグラフ化したものです。
さて、このような数式のグラフを描く際の内部処理では、まず x 方向と y 方向に細かくきざんだメッシュ上の各交点(格子点)の位置で、「z の数式がどのような値を取るのか」を計算する必要があります。 ここでメッシュの様子が分かりやすいように、あえて粗いきざみで描いたグラフが下図です:
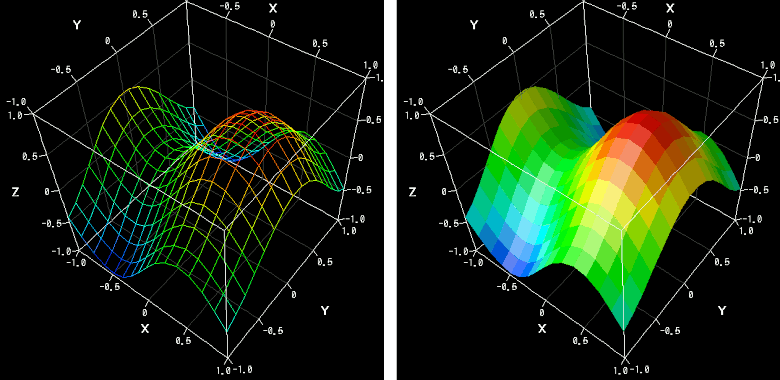
上の左図がメッシュそのもの、右図がそれを面で繋いだものです。このメッシュは、X-Y平面では碁盤の目のようになっています。このメッシュ上のある交点、例えば水平方向で (x,y) = (0.0, 1.0) の位置にある交点に注目しましょう。
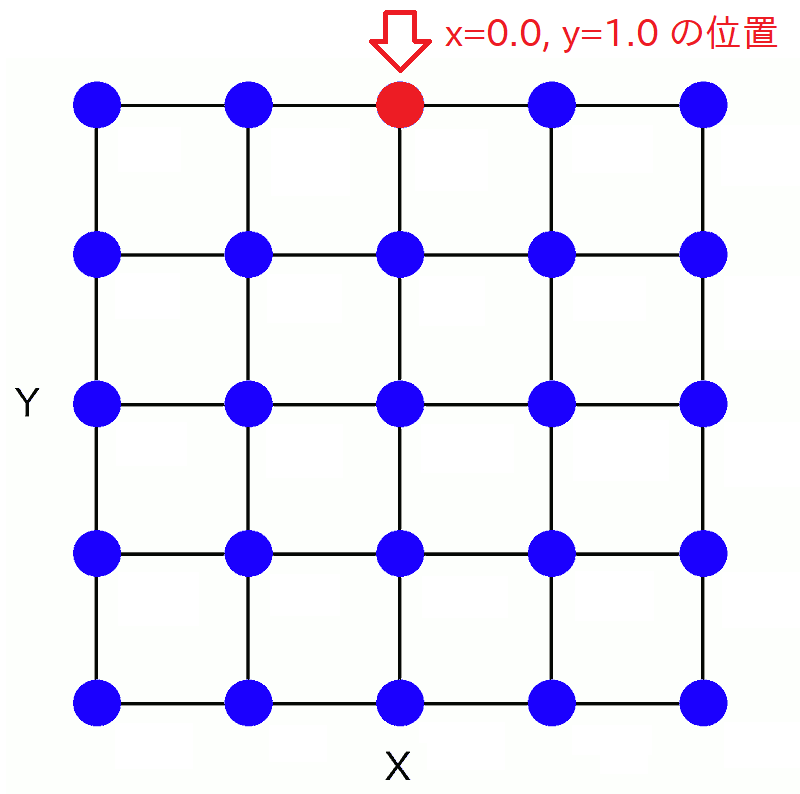
この点の z の値が分かれば、3次元空間におけるこの点の位置が定まります。そのためには、先ほどの数式:
\[ z = \frac{\sin(3.2 x) + \cos(2.7 y)}{2} \]の右辺の値を、x = 0.0 かつ y = 1.0 として計算すればよいわけです。こういうのは関数電卓を使えば計算できますね。実際にいま計算すると、結果は z = -0.4520360... です。 つまりこの点の3D座標は (x,y,z) = (0.0, 1.0, -0.452...) という事になります。
で、関数電卓の代わりに、こういった計算処理をリニアングラフ3D内部で担うのが、ここでの Vnano のスクリプトエンジンの役割です。

このようにして、メッシュ上での他のすべての交点( x と y の値がそれぞれ異なります)についても、ひたすら数式から z の値を計算していきます。するとメッシュ全体の形が3次元的に定まるので、やっとグラフが描けるわけです。
さて、このような用途では、スクリプトエンジンはアプリ側(いまの場合はリニアングラフ3D)から、計算処理のリクエストを、繰り返し大量に受ける事になります。
例えば 100 x 100 のメッシュで数式を描く際は、合計 1万回の計算リクエストを受けるわけです。 仮に、1回の計算リクエストを1ミリ秒(1000分の1秒)でさばいたとしても、合計で10秒もかかってしまいます。 それでは、数式プロットの待ち時間としてはちょっと重すぎますね。

となると、こういう場面では、スクリプトエンジンの "すばやさ" がとにかく非常に重要になってきます。それも、単なる計算処理の速さだけではありません。 「アプリがスクリプトエンジンに処理をリクエストしてから、まずエンジンが準備をして、そして計算を行い、最後に後始末を済ませるまでの、トータルの所要時間の短さ」が重要になります。
なぜなら、いくら計算自体が速くても、リクエストを受けてから計算開始するまでの準備に長~い時間がかかっていたら、体感としては遅くなるわけですからね。特にこのようにリクエストが大量発生する用途では。

さて、ここからは今回の本題に入りましょう。 今回のVnanoのスクリプトエンジンの更新は、次期版リニアングラフ3Dに搭載するにあたり、行った高速化を反映させたものです。
高速化といっても、計算速度の高速化ではありません。Vnano の計算速度は、スクリプト処理系としては既に十分速い水準(倍精度スカラ演算で1GFLOPS付近、配列演算で数十GFLOPSクラス)に達しているため、 グラフソフトの内部処理程度で足を引っ張る事はほぼないためです。
では何を高速化したのか?というと、「計算をリクエストされてから、実際に計算を開始するまでの、準備の所要時間」です。 すぐ上でも話に登場してきましたね。あれを削り込みました。 つまり、連続的に大量の計算リクエストが発生する場合などに、著しく効いてきます。

それも、同じ内容の計算式やスクリプトが、繰り返し入力される場面で効果を発揮するような高速化になっています。まさに上で見てきた、リニアングラフ3Dでの数式プロットなどが該当しますね。
その結果、前バージョンでは 100 x 100 メッシュでの数式計算(リクエスト1万回)に約10秒程度を要していたのが、100分の数秒程度(0.03秒とか)まで大幅に高速化しました。 数百倍くらい速くなったという事になりますね。だいたい数十万リクエスト/秒くらいのペースでさばける速さです。

すぐ後で見る通り、もっと色々と理想化した条件下で最大性能を測ると、潜在的にはもっと速い処理も可能なようです。ただ、あまり実用シーンで出くわさない極端な状況下で発揮される最大性能は、どこまで参考にしてよいかピンとこないですよね。
その点、ここでの「アプリ内で普通に使って、実測でこれくらい出た」という結果は、実用時に普通の目安になると思います。
さて今度は逆に、とにかく最大性能を測る事を目的に、色々と理想化した条件下での結果です。
具体的には、「スクリプトエンジンに単純な計算リクエストを投げ続けるだけの、極力シンプルなベンチマーク専用コード」を書いて、その上で性能を計測しました。 実用アプリ上だと、どうしても色々と複雑なものが絡んでくるため、純粋にスクリプトエンジンの性能だけを測るのが難しいためです。 また、処理リクエストの回数も、最大性能が出る領域を探して色々と変化させました。
その結果ですが、まずは単純に、「各リクエスト回数と、それをさばく所要時間との関係」をグラフにしたものが下図です。 なお、ここでは高速化のメカニズムを発動させるため、最初に一回だけ余分に処理していているのですが、その分は所要時間には含めていません。 つまり高速化がフルで効いた状態での所要時間です。
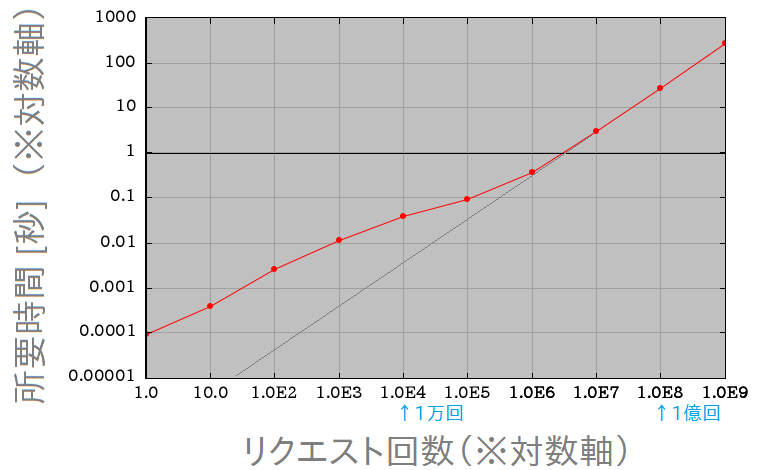
上図の通り、リクエスト回数がだいたい10の6乗 = 百万回よりも多い(右側の)領域では、グラフが直線的に伸びています。 その傾きはほぼ 1 になっていますが、このグラフは両対数軸なので、この事は「所要時間がリクエスト回数にほぼ正比例している」という事を意味しています。これは普通に素直な挙動ですね。
一方、リクエスト回数が少ない左側の領域では、その直線よりもグラフが上側にそれていて、なんか時間が余分にかかり気味である事が見て取れます。
次に、それぞれのリクエスト回数を、それぞれの所要時間で割って、 「単位時間あたりにリクエストをさばいた回数 = さばける速さ」を求めると、下図のグラフになります:
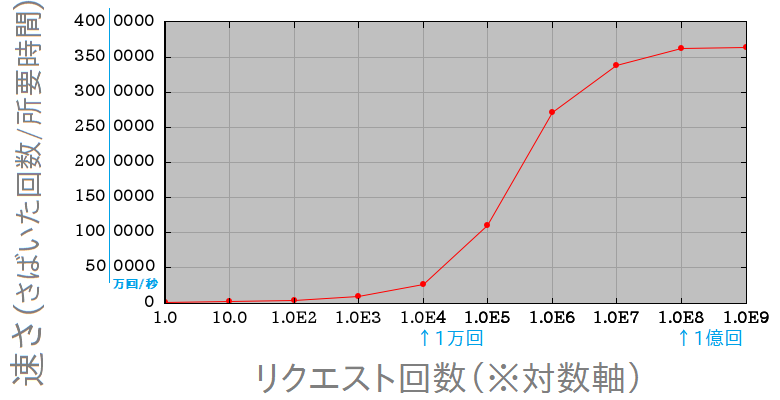
なんか「百万回転から上がパワーバンドです」みたいな感じの性能曲線になりましたね… 逆に低負荷側、1万リクエストとかの常用域はスッカスカで、まだアイドリング中みたいな雰囲気です。 ちょっともったいない特性ですね。
以上が今回の高速化の結果なのですが、上記の結果A、Bを見比べると、「リニアングラフ3D上での常用域では、ベンチマーク上で出した上限値(@1億リクエスト)と比べて、1割くらいの速さしか出ていない」という点がやっぱり気になります。 1割でも普通の用途では十分そうな速度域に達したので、別に深刻な問題ではないんですが、しかし実用シーンでももうちょっと性能を引き出しやすくするのが今後の課題かもですね。
本記事の最後に、またちょっとだけ余談です。現在のRINEARNでは、今回のVnanoも含め、色々な言語処理系を開発したりメンテしたりを結構しています。 その源流を振り返ると、そもそもの発端は、やはり昔のリニアングラフ3Dで数式を描かせるためでした。2010年頃なので、もう十数年前ですね。
今回久々に、「数式のグラフ化のために言語処理系をチューニングする」という作業をやったわけですが、なんかルーツを思い出す的な感じで感慨深かったです。
ちょうど当時の感想文的なものが、関数電卓ソフト(リニアングラフを内蔵してるやつ)を Vectorソフトニュースさんに取り上げていただいた記事の、「ソフト作者からひとこと」コーナーに今も載っていました。 内容もまあ「干支(えと)が一巡りしたのに今も当時も同じような事をやってんなあ」という感じです。
◇
以上、今回はVnano の最新版 Ver.1.1 の公開に合わせて、ユーザー目線にとって重要そうな方向から、高速化の内容と結果をご紹介しました。
実はこの記事は続編を予定していて、次回は開発側の視点から、スクリプトエンジン内部に施した高速化の内容を掘り下げたいと思います!
