
前回の記事 でもお伝えした通り、RINEARNでは最近、ソフトの使用をサポートしてくれるアシスタントAIさん達を提供開始しました。
さて、今回の記事と次回の記事は、前回の続編です。今回からは、上記のAIアシスタントをどのように作ったのかという、舞台裏のあれこれを公開していきたいと思います!
ただ、実際にアシスタントAIを作って、運用しながら改良していくには、まずAIそのものや、周辺のシステムをよく知っておく事が大切ですよね。いきなり作り方だけ説明しても、全く同じものは作れても、自分の用途に応じたカスタマイズで壁にぶつかってしまうかもしれません。

そこでこの内容は2回(または複数回)に分けて、今回はまず、前提として押さえておきたい基礎知識を解説します。そして次回、実際に ChatGPT 上でアシスタントAIを作ってみましょう。逆に、「もうそのあたりの知識は十分知っている」という方は、今回は飛ばして次回の記事をお読みください。
それでは、一緒に基本を掘り下げていきましょう!
まず、一番重要なのは、なんといっても扱うAIそのものに関する理解ですよね。そこから入りましょう。
ChatGPTをはじめ、最近爆発的に普及してきている対話式のAIは、多くが 大規模言語モデル(LLM) という方式を採用しています。最近のAIがものすごく自然に会話して、質疑応答でも翻訳でもバリバリこなせるのは、このLLM型のAIというものが彗星のごとく爆誕したおかげです。
で、我々も ChatGPT のサービスを通して、このLLM型のAIにアシスタント役をやってもらうわけですが、そのためにはまず、LLMの背景や特徴をよく知っておく事が重要です。まずそのあたりを掘り下げましょう。
さてこのLLM、いきなりちゃぶ台をひっくり返すようですが、実は「何故こんな動作を実現できているのか」が未知な部分も多く、なので「こうだからこうなんです」と理屈立てて説明するのは難しいです。

もちろん、「いつかこういうものが誕生する日」を目指し、多くの研究者が地道に一歩一歩、研究を積み重ねてきた結果として、今に至っているのは事実です。無から突然発生したわけではありません。「会話するAI」や「自然に読み書きできるAI」の研究自体は、かなり昔から地道に行われてきました。
しかし、数年前に大きな技術的躍進があり、そこからものすごいペースで進化して、本当に「あっという間」に現在のレベルまで到達してしまいました。
で、なぜその方法がここまで上手くいっているのか? 一体ニューラルネットワーク(脳の神経ネットワークを模した構造で、いわばAIの思考回路のようなもの)の中でどういう "革命" が起こっているのか? という点は、まだ理解が追いついていない状況です。
つまり、現物の進化の方が先行してしまって、そのあと世界中のみんなで「なんでなの?」という理屈を必死で研究してる感じですかね。で、そのあたりの歴史的経緯は結構おもしろいので、概要を追いかけてみましょう。歴史を追いかけると、とりあえず現状どういう状況なのかは少し掴めます。
それではタイムマシーンで過去に戻ります。いまから7年前、2017年頃がいいでしょうかね。この頃はまだ、いまほどのレベルで自然な会話や文章理解・生成ができるAIは居ませんでした。
人間の文章(自然言語)を正しく理解するには、いわゆる「 文脈を読む 」みたいな事がいかにも重要そうですよね。実際それをうまくやるのが課題だったようです。で、ニューラルネットワークで自然言語処理を行う上で、そういった文脈を読むための色々な試行錯誤がありました。
その一つが「 Attention(アテンション、注意) 」という仕組み。ラフなイメージ的には、たぶん「あっちの文脈の内容がこっちのこの語に『かかっている』」みたいな、離れた強化/弱化の関係性を表して繋ぐ機構、といった感じですかね?(素人解釈ですが)。
この Attention 自体は、もう少し前の頃から、他の色々な工夫と組み合わせて使われていたようです。が、どうもそれらの中で、「 この Attention こそが本質的にかなり重要で、それをうまく使えば、他のいくつかの工夫は大胆に削っても、(学習量や規模といったパワーでゴリ押しすれば)いい線いくっぽいよ? 」という事がわかってきます。
特に、「 文脈を読むためには、文章を頭から尻尾に向けた方向に、順々に処理しながら後方に作用させていくべき(RNN的に)」という視点に立った工夫が、どうも無くしてしまえるらしい、と。これがそれまで効率化を妨げていたようで、それを解消できて、うまいこと並列処理もできるようになったわけです。 並列処理ができると、GPUやTPU(をさらに大量に持つサーバー群)の能力をフル活用してより速く学習/訓練ができるし、今までは計算時間的に非現実的だったような大きな規模にもできる。
この事の発表論文のタイトルは「 Attention Is All You Need 」で、意訳すると「 本当に必要なものはアテンションだった 」みたいな感じですかね。ちなみに Google の発表です。 で、この論文では、実際にそういうコンセプトに基づく Transformer(トランスフォーマー) というニューラルネットワークのモデルが発表されました。
で、この Transformer を用いた応用モデルによって、学習や訓練の効率が上がり、自然言語の扱いがかなり進歩しました。つまり今のAIの躍進は Transformer が支えている面がかなり大きいわけです。というかもう基礎、土台です。

実際に Google 自身もこの Transformer を応用して、2018年に BERT という、強力な実用モデルを生み出しました。この BERT は、「人間の文章というものを形成する概念」を、たくさんの文章の穴埋め問題のような形で学習した結果、高い文章の理解力を獲得しました。また、質問応答の訓練をした結果、それも可能になっているようで、実際にチャットボット用途でも結構使われたりしているようです。
この BERT は今も自然言語処理でバリバリ使われています。上記のように、あたかも ChatGPT のルーツっぽい事が色々できるのに、なぜ当時 ChatGPT ほど一般層に爆発的な話題にならなかったのかは知らないのですが、やはり用途がちょっと特化方向である事と、内在している知識量・規模の違いなんですかね?
BERTは「幅広くなんでも質問に答えます」っていうようなものではなく、用途に応じて学習やチューニングしなきゃいけない。が、文章を正しく理解したり質疑応答したりの能力は BERT でも発生しているので、それ自体は ChatGPT が突然やった革命というわけではないはずです(時系列的に)。
※ 後日追記: ChatGPTさんにこの点について聞いてみたところ、「ChatGPT(GPTシリーズ)は『生成型(Generative)』のモデルとして、次に来る単語を予測して新しい文章を生成するのに長けてるのに対して、BERTは『双方向型(Bidirectional)』であり、文全体を見ながら文の一部を補完する能力に優れてる。つまり生成よりもむしろ理解を重視している。」という違いが結構大きそうです。つまりアーキテクチャとして重視している方向がちょっと違う。で、ChatGPT はすぐ後で述べていく通り、生成重視の方向性が、一般層の用途によくマッチしてヒットしたっぽいですね。
なお、後述の GPT 系モデルよりも規模が小さい、この BERT であっても、「何故この訓練でこんな能力をうまく獲得できるのか?」という理由はまだよく分かっていない状況です。なのでここから先は、「こうやったら、こういうものができた」という結果論・現象論のような話になっていきます。 人間の脳が、何をどうやって考えているのかが未解明なように、大規模なニューラルネットワークが何をどうやって判断して動いているのかを理解するのは、一般に極めて難しいとされています。一応、部分部分で探るような研究はされているようですが、まだ謎だらけです。まさに脳の研究みたいな。
さて、いよいよ GPT が登場します。これも2018年ですが、Google ではなく OpenAI 社の成果です。 このGPTも、「Generative Pretrained Transformer(事前学習済みの生成的 Transformer)」という名前の通り、構造的には Transformer を組み合わせた応用モデルです。 ただ、Pretrained(事前学習済み)の通り、学習手法にもブレイクスルーがあり、大量の文書の内容を学習しています。結果、自然言語処理モデル自体が、ある程度の幅広い知識を持っている、というものができるわけです。 で、その知識に基づく「文章の生成が得意(Generative)」なモデルとして開発されました。
いろんな文章を学びまくったら、いろんな文章を自然に書けるでしょ、みたいなノリだったんでしょうかね? 当初は。

さてこのGPTは、GPT-1、GPT-2、… とバージョンが上がって進化していきます。規模(パラメータ数)が増えて、さらに学習する文書の量も増えていきます。それに伴い、内在している豊富な知識をもって、様々なテーマの自然な文章を、(過去の時代と比べれば)かなり自然なレベルで生成できるようになりました。
確か「GPT-2」の頃に、「 生成される文章があまりに自然で、人間の文章と区別が難しいレベルに達しつつあり、危険だ 」みたいなニュースが出て話題になった記憶があります(※)。僕がGPTという語を始めて目にしたのはこの頃でしょう。ただ、当時はまだ、あくまでも「自然な文章生成ツール」みたいな扱いでした。GPTの当初のコンセプトの範囲内での進化だったわけですね。
その次は「GPT-3」なんですが、ホットなのはむしろその派生版の「InstructGPT」です。 これには 人間のフィードバックを混ぜ込んだ強化学習(RLHF) という手法が取り入れられて、これによって、モデルの出力を人間の判断によって効率的に矯正できるようになりました。 これは精度や品質を一気に上げられるという事で、ChatGPT 登場初期にかなり話題になっていた記憶があります。具体的にどう効くのか個人的にはよく知らないんですが、これがあったから実用レベルに到達できたという点は恐らく大きいのでしょう(当時の話題はそんな感じでした)。
そしていよいよ、InstructGPT からさらに派生して、「入力を人間の質問と見なし、それの返答として相応しい文章を生成する」という方向に訓練されたモデルが誕生します。これが非常に上手くいって(※)、人間とAIがものすごく自然に、しかも豊富な知識を交えつつ、自由に会話できるようになりました。ChatGPT の誕生です。

このようにして、
というピースが全て揃ったわけです。
これが揃えば、AI界隈の開発者だけでなく、一般層のユーザーにとっても非常に便利そう。 で、実際にこれを実用サービスレベルまで高めたものが、あの ChatGPT のWebサービスとして一般向けに公開されました。 2022年の事です。
そこから先はよく知られている通り、世界的に大ヒットしつつ、さらにモデルも進化していって、できる事もさらに増えていきました。
と、時系列的には以上のような具合です。「Transformer による効率化のブレイクスルーの後、規模を増やしつつ、いろいろ工夫を試して重ねていったら、結果的にできていった」、という雰囲気は伝わったでしょうか。
が、やっぱり「 なぜ? 一体なぜこんな事がAIにできているの? 」っていうのはどうしても気になりますよね。
既にちょっと述べた通り、「大規模なニューラルネットワークの言語モデル(LLM)が、中で何をどうやって判断して動いているのか」は、もう複雑すぎて謎 なのですが(脳みそみたいなもん)、結果論・現象論として分かってきた重要な性質が 2 つあります。

まあなんか、RPGとかでの「 レベルが上がったら突然新しい魔法を覚えた! 」みたいな雰囲気があるんですかね? LLMの進歩って。なんかもう生物の進化に近い感じがしますね。
こういう性質があるためか、LLMは「コスパを度外視して性能という一点を追求する」なら、たぶんデカい方が本質的に有利で、しかしデカいLLMは重くて学習も大変になります。 最先端のどデカいモデルは、大企業のデータセンターのサーバー群とかでかなりの期間をかけて学習・訓練されます。
だからいま巨大テック企業はとにかくGPUを集めまくって、どデカいパラメータ数のLLMをトレーニングしまくるという競争時代に突入している わけですね。この種のトレーニング用GPUのハイエンドはもう品薄でなかなか買えないらしいです。全世界的に。 ちなみに日本もいまスパコンの富岳とか使って色々やってるらしいです。
結果、当初は自然言語の解釈や生成+αくらいしかできなかったLLMも、異様なペースで進歩し、今では色々な事が(一見関係なさそうな事まで)できるようになりました。
質問応答はもちろん、あたかも「深く考えている(諸説あります)」かのような回答や、要求に応じたプログラムのコードを書いてくれたり、データの分析を手伝ってくれたり、画像を見て理解したり(マルチモーダル)。多分これからもどんどん増えていくんでしょう。
で、そんな汎用的な能力が伸びてきた LLM に、我々はアシスタントAI役をやってもらおう、というわけですね。具体的には、
という事をやってもらうわけです。上記は、実際にうちのアシスタントAIが行っている事です。
そう、今の LLM はもうこんな事ができてしまうんですよ! びっくりですよね。でもなんで可能かは分からん。OpenAI の人がめっちゃ努力して訓練したら結果的にできるようになったんでしょ、くらいしか。

いくらトレーニングしたといっても、中に何かしらの「知性」が居ないとコレ絶対できないんじゃないの?っていう気もしてしまいますよね。なんというか、「何かが生まれてしまった感」 がすごい。
つまりそういう、人類にとってまだ全然よく分かっていない『 もはや新種の知性と呼ぶべきかもしれない何か 』に、アシスタントAI役をお願いして、演じてもらうんだという感覚を持つ事は大事だと思います。うまく機能しなくて「バグだ」と言っても何も始まりません。そもそも何故それができるのか自体、誰にも分からないのですから。もう従来の普通のソフトウェアとは根本的に違うんです。色々やって、「うまく付き合っていけそうな経験」を蓄積するしかないのです。
一応、LLMの末端のメカニズムだけは「確率分布に基づいて次の単語を生成する」という形で決まっているんですが、その確率分布を決める巨大なニューラルネットワークが、何をもってその単語を「選んだ」のかはもはや全く分からないわけです。
最初は単に、「大量の文章で学習した統計から、いかにも次に来そうな、もっともらしい単語を選んでくれてるのでは? それを繰り返せばもっともらしい文章が生成されるのでは?」程度の試みだったはずが、なんかその予想の範囲を超越して、色々な事ができてしまっている現実があるわけで。
とするとやはりLLMは人間のように「 考えている 」のか? と思えるわけですが、しかし逆に「 考えるとはそもそも何なのか?」、「 人間の思考も、一見考えているように見えて、実は次元の数が多いだけの確率的にシンプルな振る舞いだけで説明できてしまうのか?」…などなど、根本的な謎も湧いてきます。もはや「知性とは何か」という根源的な問いを投げかけられる事態に人類が直面しているわけです。
結局は巨大なニューラルネットワークと、知識を組織化する作用のある訓練が揃えば、「知性と呼べる何か」が生まれるものであって、言語モデルという形はその糸口のインターフェースに過ぎなかったのかもしれない。実際、最近の画像生成AIには「知性っぽさ」を感じる面が多々ありますし。
もしくは逆に、「言語というもの」こそが重要で、従来はコミュニケーションや思考補助のツール(サピア=ウォーフ仮説レベルの)だと思っていた「言語」には、実はそれ自体が知性を生む作用があるのかもしれない。というか言語と知性は実は分割できるものではなく、高次元で一つに繋がったものの射影なのかもしれない。
どちらも人間の知性のルーツにも影響しそうで、AIの話だけでなく、我々にとっても非常に興味深いテーマの問いですよね。
さて、記事前半の時点で既に異様に長くなりましたが、私の今日のAI熱はまだ発散できていません。 ここからは後半に入りましょう。もう一つの重要なシステム、RAGについてです。
前半でも述べたように、GPT系のLLMモデルは、世界中の様々な知識を事前学習(Pretrain、GPTの「P」はこれ)しているため、その知識に基づいてユーザーの質問に答えてくれます。
一方、カスタムAIを作るために、そのモデルがまだ知らない情報を、追加で覚えてほしいという場面もありますよね。あと、挙動をもうちょっと用途に適した形に調整したいので、振る舞いを学習させたいとか。
実際にそういう追加学習は「ファインチューニング」と呼ばれていて、自前でオープンソースの小規模LLMを運用している人とかは試しやすいかもしれません(高性能マシンが必要でしょうが)。OpenAI でも、API契約をしていれば、OpenAI 側の環境で GPT 系モデルのファインチューニングをやってもらえるサービスがあります。
が、このファインチューニング、私はやった事が無いんですが(なので完全に素人感覚ですが)、ぱっと想像するよりかはだいぶ難しいみたいです。そもそも一般に、ニューラルネットワーク系のモデルに何かを学習させるって、だいぶノウハウが要って難しくて、良いデータセットを揃える時点でかなり専門的でビジネスになる領域だったりします。

用途に応じた挙動の調整/矯正とかはファインチューニングの出番になるようですが(そうするしかない)、一方で「 ちょっとした文書があるから、その内容を踏まえて質問に答えて 」くらいの用途でファインチューニングをするというのは、どうもあまり向いていないみたいです。ウチでも一回試してみたいですがね。やっぱりだいぶ苦戦するんでしょうね。
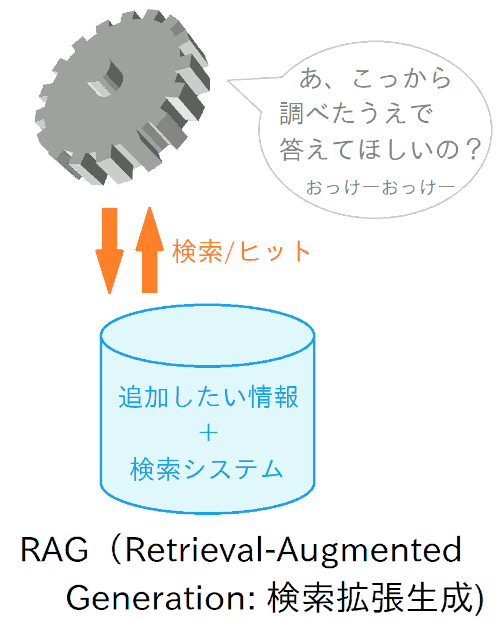
で、じゃあ「アシスタントAIにちょっと知識を補充したい」くらいの場合に、現実的にどうするか、という話です。その定番になっている手段が RAG(Retrieval-Augmented Generation、検索拡張生成) です。
これは、モデル自体に知識を覚えてもらうのではなく、「 AI用の知識検索システム 」のようなものを作って、AIにそれを使ってもらおう、というものです。
つまり、「 あらかじめ登録しておいた情報群の中から、回答に必要な情報を検索して、結果を読んで理解した上で、ユーザーの質問に答えてもらう 」わけです。イメージとしては、ちょうど「人間がググって(Google検索して)から回答する」のに近い感じですかね。
さてこのRAG、企業だと自前で構築している例も増えてきていると思いますが、実は ChatGPT でも、有料の Plus 会員ならWebブラウザ上で簡単に構築して使えるんですよ。
具体的には、「 Knowledge 」っていう機能で知識を登録できて、そうするとGPTモデルが自動でそれを検索/参照しつつ答えてくれるようになります。つまり簡易的なRAGになるというわけ。GPTモデルそのものをファインチューニングで学習/訓練させて精度を出すより(仮にできたとしても)、だいぶお手軽です。
実際に、今回のプロジェクトで作成した「リニアングラフ3D アシスタント」は、一言で言うと「 リニアングラフ3Dの取扱説明書や関連資料を、ぜんぶ Knowledge に詰めて検索可能にしてある、RAG 化された GPT さん 」に他なりません。そこから必要な情報を参照しつつ、ユーザーの質問に答えてくているわけです。
という事で、アシスタントAIのようなものを作る場合、RAGみたいなシステムを使う事はとても有用です。
しかし、何も考えずに適当にRAGにデータを登録しても、とんちんかんな答えしか返ってこず、ぜんぜん使いものにならないとガッカリするかもしれません。が、そこで失望するのはまだ早いです!
実用レベルの精度を出すには、実際にあれこれ試行錯誤して、チューニングしてみる段階がどうしても必要です。そのための基礎知識として、まずRAGという仕組みの背景にある、色々な課題や手法をある程度把握しておきましょう。
まず一番重要な課題です。そもそも LLM 型のAIは、「 認識可能なコンテキスト長 」に上限があります。
ここでいう「認識可能なコンテキスト長」というのは、要するに回答を生成する上で読み込んで、「意識の上に載せて」いられるテキストの長さの事です。
例えば ChatGPT は、ふつうのチャットの場だと、質問文だけでなく、過去の会話の履歴も踏まえた上で会話してくれていますよね。これは、それらを読み込んで、「意識の上に載せて」回答してくれているからです。
しかし、会話がかなり長くなってくると、過去の話を忘れてしまっている場面もありません? あれは、会話が長すぎて、認識可能なコンテキスト長の範囲に収まらなくなってしまい、切り捨てられたからです(遠方だと Attention が弱くなってくる効果もありそうですが)。
で、仮に数百ページほどある文書の全文を、何も工夫せずにそのまま、AI用の参考資料として与えたとしましょう。するとAIがそれを読み進めている最中に、認識可能な長さを超えて、意識の外にあふれてしまうでしょう。

そうなると、全体を俯瞰して「どこで何を言ってるか」なんて把握できないし、必要な部分を要約しようにもそれすら意識に収まらなかったりするでしょう。さらに、一緒に意識に載せる必要があるプロンプトも相対的に圧迫されてしまう懸念もあります。
つまりこれは、「プロンプトに資料の全文を一緒にベタ書きして渡す」のとほぼ同じで、巨大な文書の場合は明らかに無理があります(小さい文書なら有効ですが)。
ここで 「え? でも ChatGPT の Knowledge 機能とか、かなり長いファイルを登録しても、AIが認識できるけど…?」 と思われたかもしれません。実際その通りです。
これは、Knowledge のシステムの裏側で、すぐ下で説明するチャンク分割などの工夫が行われているからです(詳細仕様は非公開なので、推測ですが、挙動の感触から十中八九そう)。
そしてまさに、このチャンク分割のされ方こそが、回答の精度にかなり関わっているという感触があります。なので、仮に明示的にチャンク分割しない場合でも、それが行われる事と、その影響は知っておく必要があるのです。
で、それなら「文書を細切れの区間( チャンク / Chunk と呼びます)に分割しておいて、検索によって合うものをピックアップする」というアプローチが素直(というかそうするしかない?)ですよね。 もしくは、検索結果をさらにチャンクに切って、関連性が強い部分に絞るとか。
で、文書をチャンクに分割すると、確かにAIの認識可能なコンテキスト上限を圧迫せず、先述の課題は回避できます。しかし、それと引き換えに、別の課題が生じてしまいます。それは、「チャンク間を繋ぐ文脈が切れてしまう」という事です。
例えば X(Twitter)で、連投ツイートをする人がよく居ますよね。で、その連投の真ん中あたりのツイートが流れてきた時、「ん?なんの話してんの?」って理解不能になる事があるはずです。で、ツイートの列を辿って、全体を読んで初めて、正しい意味が分かったり。 最初思ってた解釈と全然違ってたわー っていう誤解に気づいたり。そういう事ってありません?

一般の文書も同様で、普段はあまり意識しないのですが、実はこういう部分部分の間の繋がり関係があるわけですよ。というか、まさにそういう「文脈」を読めるのが、いまのAIの凄い所、という話を前半でしましたよね。
でもチャンク分割は、この文脈という非常に大切なものをブチ切ってしまうわけです。チャンク同士は互いの話の繋がりや補完関係を失い、それぞれ独立な文書になってしまう。
つまり、チャンクの切り方がまずいと、その中の特定チャンクだけを読んでも、意味がよく分からなかったり、もしくは全く別の意味として読めてしまったりする。そういうまずさがあるんですね。
とはいえ、巨大なテキストをチャンクに分割する/されるのはほぼ不可避なので、「どこでどう切られるか」というのがとても気になるポイントになります。特に ChatGPT の Knowledge のように、サービス提供者の側で自動的に切られる場合は。
さて次の課題です。文書をチャンクに分割するという事は、「AIが知りたい情報が含まれているチャンク」を検索できるようにする必要がありますよね。
当然そこも重要です。ただ、ChatGPT や巨大テック企業のAIサービスは、この検索処理自体をいじる事は当然できなくて、システムで用意された仕組みをそのまま利用する事になります。が、それでも、 「中でどういった検索をやっていそうなのか?」というのを、ある程度見当をつけて、それに合わせて登録する情報を工夫/加工する、といった事は有効です。 私自身も、今回のアシスタントAIを作る上で、そのあたりをかなり試行錯誤しました。
で、そのために、「どういった検索が一般にあるのか」という事を抑えおきましょう。
さて、最初にいきなり難しい概念が登場します。上記の見出しの時点で「???何言ってんの???」って感じですよね。実際にここは内容も難しいです。すみません。
唐突ですが、3次元空間における、ある点の位置って、(x, y, z) という3つの値で指定できますよね:
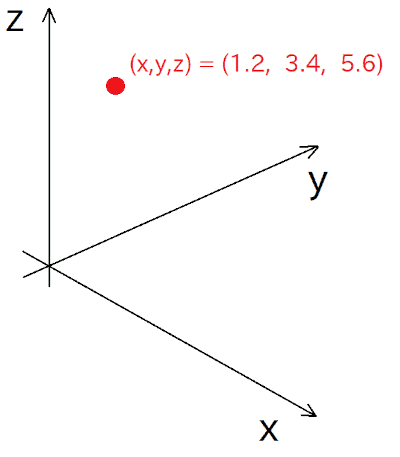
それと同じように、もっと次元が多い、n 次元の空間を考えます。すると、その空間における、ある点の位置は、n 個の値で指定できます:
つまりN次元のベクトル「みたいなもの」ですね。
で、「 この n 次元空間上の位置を指すベクトルが、我々の現実世界での『意味』を表すようにできないか? 」という事を考えます。
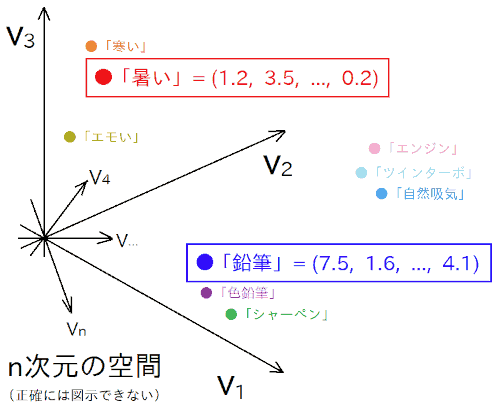
例えば位置 (1.2, 3.5, ..., 0.2) は「暑い」という意味、位置 (7.5, 1.6, ..., 4.1) は「鉛筆」という意味、みたいな感じです。この空間で近い位置は似た意味を表す。離れた位置は全然別の意味を表す。という具合にです。
こんな都合がいい空間を実際どうやって構成するかというと、まず色々な単語とか文章とかをたくさん用意して、それらが正しい位置関係(近い位置は近い意味、遠い位置は遠い意味)を満たすように、n 次元空間に並べていきます。 この処理の事を「 埋め込み 」とか「Embedding」とか呼びます(本来は数学用語)。
これは人力でやるのはほぼ無理ゲーなので、色々な方法が結構昔から探られていたようです。 そして2013年に Word2vec という技術が開発され(by Google)、効率的かつ高精度に求められるようになりました。Word2vec では、単語同士の位置関係は、ニューラルネットワークが大量の文章(コーパス)を解析して自動で把握して決定されます。この技術は、LLM をはじめ最近の自然言語処理を支えています。
さて長い前置きでしたが、チャンクの検索にこの意味空間を活用する事を考えましょう。あらかじめ、チャンクに分割された文書を、それぞれ意味空間に埋め込んで、それぞれに対応する埋め込みベクトル(意味空間上での位置)を求めておきます。
で、何か情報を探したい時、その「意味」を意味空間のベクトルに変換します。そして、チャンクの埋め込みベクトルの中から、それに近いベクトルを探します。そのベクトルに対応するチャンクの文書が、探しているものと「意味的」に最も近いので、検索結果になるというわけです。
こんな奇妙な事をやって何がうれしいかというと、「テキストとしての表現が違っても、意味が近い」という情報を探せる点です。極端な例だと、「犬のエサ」と「ドッグフード」は意味的にほぼ同じですが、テキストとしての表現は全然違いますよね。なので、犬のエサについて非常に詳しく述べた情報があっても、「ドッグフード」というキーワードで単純に一致検索しても、ヒットしないかもしれない。でも、意味で検索すればヒットするわけです。
さて次です。これは簡単で、昔からある検索方法ですよね。
検索システムにキーワードを入力すると、「 そのキーワードと単純に(テキスト的に)一致する箇所がある情報 」がヒットする、という方式です。
仕組みとしては、まず各チャンクの登録時に、その内容からキーワードを色々とリストアップして、キーワードとチャンク内容とを紐づけるインデックスが作成されます。で、検索時には、探したい情報に関連していそうなキーワードをいくつか投げると、マッチ率が高いチャンクの内容が返ってくる、というわけです。

シンプルな方式ですが、それだけに、これはこれで結構有用なはずです。これは単なる個人的な予想ですが、 ChatGPT の Knowledge の検索とかは、たぶんベクトル検索だけでなく、こういうキーワードの一致検索も併用してるんじゃないでしょうかね? 互いに補強する長所を持ってそうですし。
というのも、今回 ChatGPT に登録する Knowledge をチューニングする際、実際にそれを参照するAIさん自身と相談&テストしながら検証を進めてたんですよ。すると、どうもキーワードで検索してそうな場面が節々であって。 というか、出力に「いかにもキーワード方式のクエリっぽい内容」がうっかり混じってしまってる場合もありました(こういうミスはかわいい)。でもそれだけだど、そのクエリをベクトル変換して意味検索してるとも見れる。
それなら、と、実際に「RAGに登録した知識に登場する語句」と、「同じような意味だけど知識には含まれていない語句」を使って質問をしてみたところ、やっぱり前者の場合の方がビシっと合った回答が返ってきやすい感じがしたんですよね。なので、「ChatGPT の Knowledge はキーワードでのテキスト検索が結構効いてそうだな?」って感じたわけです。もちろん色々併用してるでしょうが、その中でも。
さて次です。これは既知の情報ではなく、単なる個人的な勘です。「こういう事やってるかも?」みたいな。
今回のアシスタントAI作成の際、ChatGPT の Knowledge のチャンクの切り方をJSON形式で色々変えて、よさそうな長さとか切り所を探ってたんですよ。当初は、切ったチャンクが先述の検索で抽出されて、それをそのままアシスタントAIさんが読んでるんだろうなと思って。「これくらいの長さが読みやすいかな?」くらいの感覚で。
すると、「 思ったよりだいぶ長いチャンクの方が精度がいい 」という感触があってですね。さらに、認識可能なコンテキスト長を超えるのでは? くらいに長く切ってみても、混乱する事なく、的確な場所を見つけてくる。「チャンクを、さらに細かいチャンクに自動分割しているのでは?」とも思い浮かびましたが、しかしそれにしては「文脈の切れ」によるトンチンカンさを感じない。細かく切ると、もっとトンチンカンになるはずなんですよ。
そこでふと、「 もしかして各チャンクの中を、別の軽量な LLM か何かを使って、関連部を抽出&要約した上で、質疑応答AIに返したりしているのでは? 」みたいな可能性を感じました。実情は定かではないんですが。どうなんでしょうね?
もしこういう事をやっているなら、ChatGPT 上では、チャンクはあまり細かく切りすぎる必要はないかもしれません(コンテキストの繋がりが切れてしまうし)。実際今回のアシスタントAIでも、かなり長めの水準に収束しています。
最後に、これは情報検索そのものとは少し外れますが、使う上で重要な点です。それは、「検索によって複数のチャンクが、同程度の重要度でヒットした場合、どれが優先されるのか」という点です。
大量の情報をRAGに登録すると、その中で、意味やキーワードが部分的にカブってる(が、違う事も言っている)チャンクも結構出てきます。すると質問の回答で、「あーそっちを読んでしまったかあ、この質問だと別の所を読んでほしいのに…」みたいなもどかしい事が発生します。
これは、自前でRAGシステムを構築している企業ならルール自体を調整できるかもしれないですが、ChatGPTや大手テック企業のシステムを利用している場合は、ルールはいじれません。なので、ルールを推測しつつ、RAGに登録する情報を工夫して対処する必要があります。
ChatGPT の Knowledge だと、現状では「 どうも先頭に近い側のチャンクの方が優先度が高くなってるっぽいな? 」と感じています。もちろん仕様は公開されていないので、あくまでも個人的な体感ですが、ググったら他にも同様の見解をちらほら見かけました。
この事を強く感じたのが、ハルシネーションを防ぐために「よくある誤回答リスト」みたいなものを作って、フィルタ的に効く事を期待して Knowledge に入れ込んだ時です。最初は Knowledge 内の末尾のあたりに付録的に入れたのですが、全然効きませんでした。が、Knowledge 内で一番頭のあたりにもってきたら、バリバリ効きました。チューニング時にそういう差が出てくるので、やっぱり使うRAGシステムでの優先順位解決の挙動は知っておく必要があるな、と感じた出来事でした。
またまた異様に長い記事になってしまいましたが、基礎知識編の内容はここまでです。
当初、アシスタントAIを作りながら基礎知識を説明していく記事スタイルにしようかと思ったのですが、それだと長くなりすぎるかなと思って、今回(基礎知識編)と次回(作成編)の記事に分割しました。結果的に、今回だけでこの長さなので、正解でした。
次回は実際に ChatGPT Plus の機能を使って、アシスタントAI(GPTs)を作ってみます。その際は、本記事を辞書的に参照しながら書くので、なるべくすっきり淡々とした内容にしたいと思っています。お楽しみに!
