
This article is a sequel to the previous one.
In the previous article, we explained the improvements in Vnano's new version, Ver.1.1, from a user's perspective. Specifically, we discussed how the processing speed of "Repetitive Execution," which involves repeatedly executing the same calculation expressions or scripts, has significantly improved by several hundred to several thousand times compared to the old version. We also explained how this improvement is beneficial in various use cases.
In this article, instead of focusing on the user's perspective, we'll delve into the topic from a developer's viewpoint, providing detailed insights into the specific improvements made to the internal structure of the script engine!
Before diving into the specifics of the speed improvements, it's essential to grasp the fundamental structure of the script engine. We have previously covered this topic in the following article, so for more detailed information, please refer to it:
As mentioned in the above article, the structure of Vnano's script engine is primarily composed of two components: the "Compiler" and the "VM (Virtual Machine)." Below, we'll provide a brief overview of these two components.
First, let's talk about the "Compiler." You're probably familiar with this term from compiled languages like C. It transforms code manually written by users into executable code.
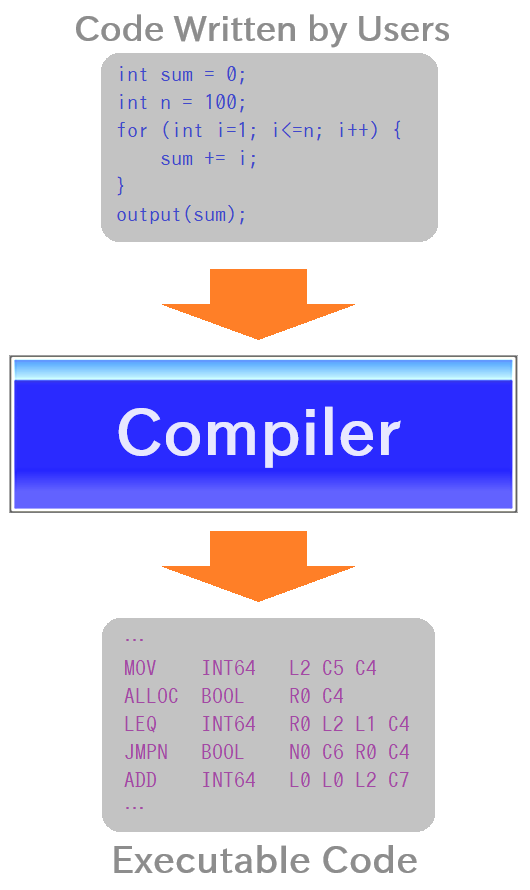
Now, some might wonder, "Huh? aren't code called 'scripts' usually meant to be executed without compilation?" Well, you'd be correct from a user's perspective. It's one of the touted advantages of so-called "interpreted languages."
However, when delving deep into optimizing script processing, even though it might appear as a simple interpreter from the outside, it often involves various compilation-like processes internally.

There are various variations on "when, what scope, and into what kind of code to compile," but the compilation itself is a common strategy for scripting engines for enhancing performance. Even the JavaScript engine in your web browser you're using to read this page compiles scripts internally.
Now, Vnano's script engine is no exception. It has an internal compiler that compiles scripts into a different form of code (explained later) before execution. The reason for this is that it offers advantages when it comes to optimizing performance.
So, what kind of code does this compiler generate? In general, there are two patterns for this.
One approach is to generate "native code" that runs directly on the CPU (+ OS). This sounds fast, right? In the realm of script processing, systems referred to as having "JIT compilation" (or simply "JIT") often do this. Strictly speaking, "JIT(Just-In-Time)" refers to the timing of the compilation as opposed word of "AOT(Ahead-Of-Time)", but typically, JIT implies conversion down to native code.

While Vnano explicitly doesn't perform JIT, the underlying Java Virtual Machine (JVM) does, indirectly benefiting Vnano. For instance, operations between arrays are SIMD-expanded.
The other approach, which Vnano primarily adopts, is to generate code that can be executed on a special software, simulating a virtual hardware (CPU + memory) and API virtualizing some of OS's features. You might say, "Isn't this just processing on an interpreter in the end?" From a certain perspective, yes. However, this approach allows us to raise the speed limit more than interpreting and executing the original script directly. Moreover, it can more easily implement script-friendly, flexible syntax compared to running directly on the CPU. It's a kind of compromise aiming for higher performance while still accommodating script-like grammar. Additionally, it facilitates porting to different CPUs/platforms.
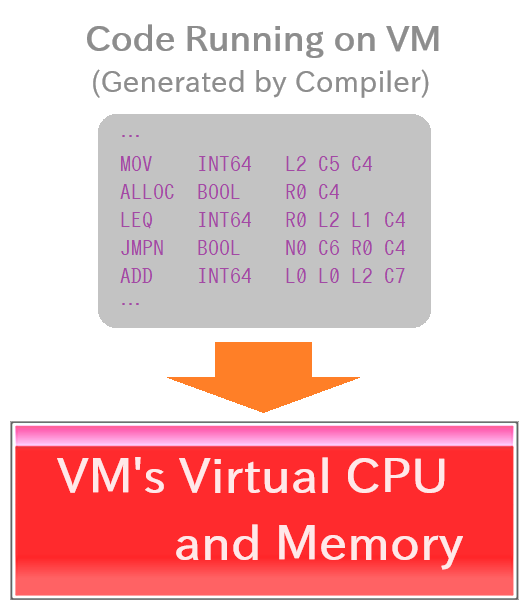
This special software that simulates a virtual CPU/memory and some OS's features is, commonly referred to as "VM (Virtual Machine)" in language processing discussions. By the way, in recent years, "VM" or "virtual machine" often refers to something that virtually reproduces an entire PC environment (referred to as "system virtual machine"), like VirtualBox, which can lead to confusion. To avoid this, some use terms like "process virtual machine."
Furthermore, combining these two approaches, running JIT compilations within a VM, is also common. Furthermore, for instance, in Java, users initially compile to VM code, which runs on the VM and then partially gets JIT-compiled to native code.
Given this reality, it's clear that categorizing the internal implementation of language processing systems into neat divisions like "compiler-based" and "interpreter-based" isn't always straightforward. In fact, languages classified as non-compiler-based (interpreted) often involve substantial amounts of compilation under the hood. Conversely, some modern compilers effectively include an interpreter within them, completing parts of code execution during compilation.
The categorization of compiled or interpreted languages represents only whether users manually use a compiler tool or not. Considering the reality mentioned earlier, is it a meaningless categorization? No. This distinction significantly influences the design of language specifications and the character of the language itself. It's a valuable classification from a certain standpoint, and it's never meaningless. I personally often view things from this perspective.
Such a slightly complicated situation exists in the world of implementations of language processing systems.
After a bit of a preamble, I hope you now have a basic understanding of the two 'main characters' in Vnano's script engine: the compiler and the VM. Once you grasp these two, the rest becomes a straightforward story.
So, how exactly does the Vnano script engine execute scripts and calculations? It's as follows:
Pretty simple, right? When viewed at this level, the overall process flow is quite straightforward.
In fact, here is a block diagram representing the internal structure of Vnano's script engine. While it might look a bit complex visually, the yellow arrows indicate the flow of processing.
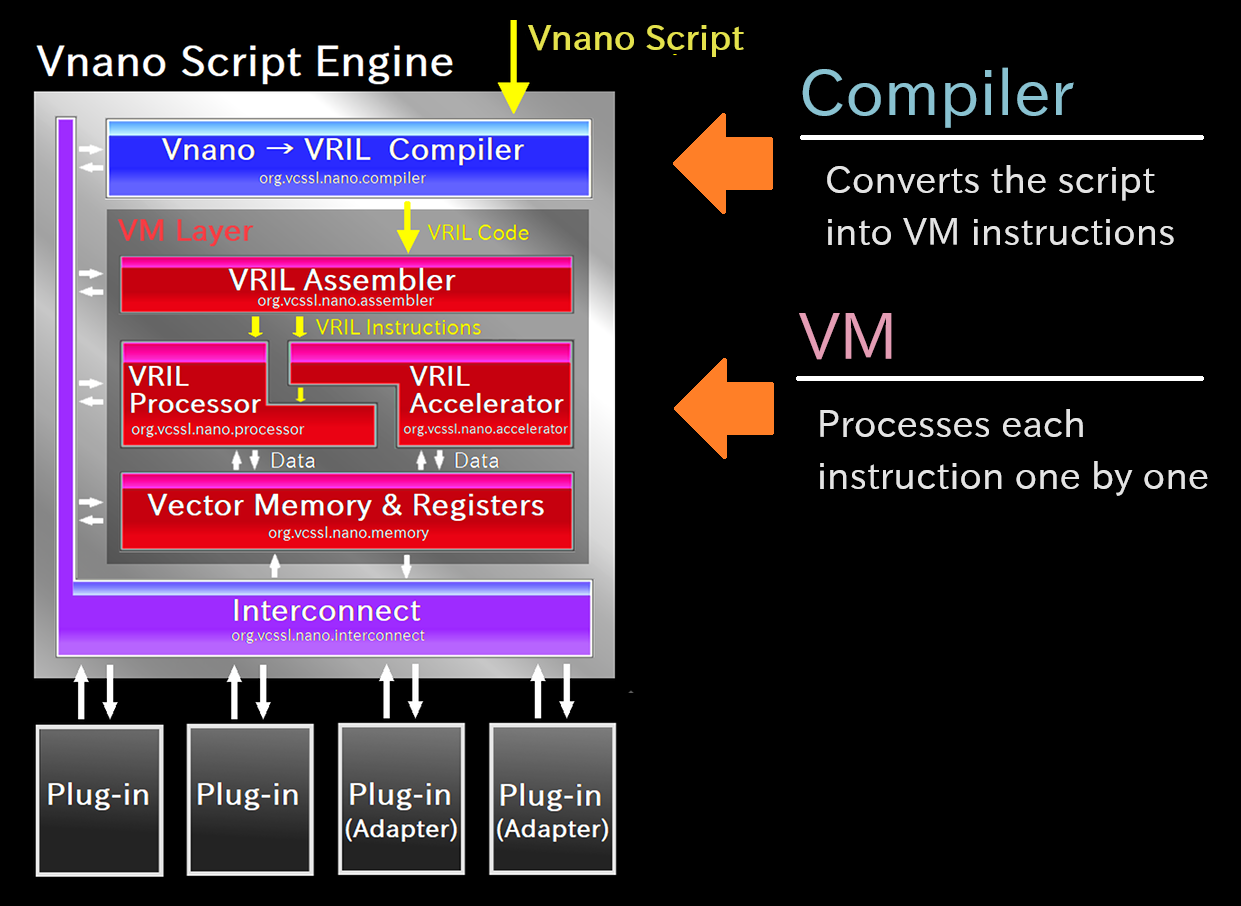
From the top, you can see that "Vnano Script" (i.e., script code) enters, passes through the blue "Compiler" block and gets transformed, then enters the red "VM" area for processing. Inside the red VM area, you'll find components like the virtual CPU (VRIL Processor) and the virtual memory (Vector Memory & Registers).
To understand the speed improvements we've made this time, this high-level overview is sufficient. For those who want to delve deeper, please refer to the previously mentioned article on architecture explanation (Japanese, has not been translated yet).
Now, let's move on to discuss the improvements made in repetitive execution speed in Ver.1.1. In a nutshell, the key approach can be summarized as "extensively caching and reusing the results of heavy computations (transformations, pre-processings, etc.) whenever possible." It's a common approach in various fields, right?
For those wondering, "What exactly is repetitive execution?" we have detailed explanations in our previous article, so please refer to it for more information.
Now, let's delve into the first point of speed improvement. The most crucial thing is to tackle the heaviest part of the process, which in this case, is compiling. Compilers, in general, performs very complex operations internally compared to the usual tasks, which can be quite intensive in terms of processing cost.
We have previously delved into the internal workings of a compiler in the following article. Even a quick skim through it might give you a sense of how hefty the process is:
Since the article above is a bit lengthy, let's just look at a diagram that shows the transformation steps the compiler performs:
At the top, you'll find "Script Code," representing a single-line expression within the script code, and the diagram tracks its transformation process. The "VRIL Code" at the bottom right is the end result of this transformation. While we'll leave out the details (see the above article for it), but hopefully, you can sense that this transformation process seems quite heavy from this diagram.
In reality, "If we can't cut down the time spent here, trimming other parts won't make much difference" - that's how substantial this part is. So, how do we reduce it?
One straightforward approach is, of course, to make the compiler process faster. This is, of course, an effective strategy. However, Vnano is a language and processing system designed for embedding within applications, and we've emphasized compile speed from the moment we defined the language specification (*). During implementation of the script engine, we also continued to emphasize it. Consequently, we've already made efforts in this regard, and there isn't much room left for dramatic improvements.
As a next approach, a common strategy is to "cache the results of previous compilations/parsing, and reuse them if the next input is the same." This approach is employed in languages like Python and in other language processing systems we develop.
This was an area Vnano had not yet tackled. This was due, in part, to Vnano's official release being delayed over one year, leading us to prioritize feature completeness over performance midway through development. Thus, we implemented this in the current update. As a result, we virtually eliminated compilation time during repetitive execution, enabling us to focus on speeding up other parts.
Next, let's delve into the optimization of the VM (Virtual Machine) side.
When we think about VM speed, what often comes to mind is the speed of instruction execution. In contrast, one often overlooked aspect is the time it takes to prepare the (virtual) memory. As you can easily imagine, this affects the startup speed of script execution.
Vnano's VM is a register-based virtual machine, which means it needs to allocate a virtual memory space for executing instruction codes. If the memory area corresponding to the virtual addresses accessed by the instruction code isn't properly allocated and initialized, the system can't read or write values and may crash.
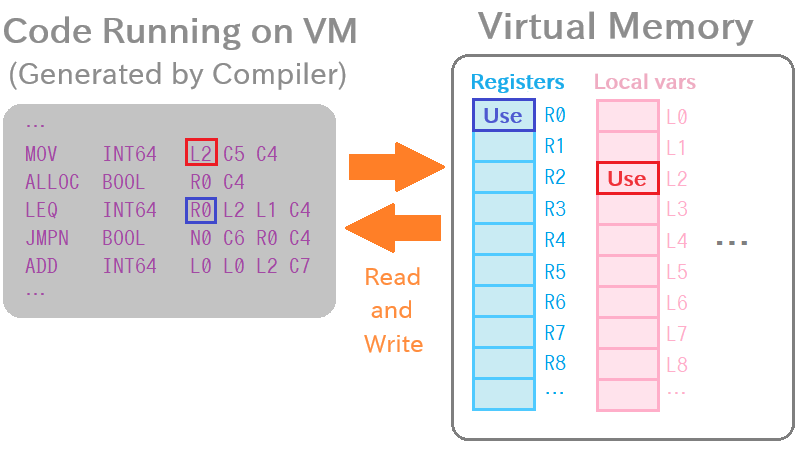
Even though this memory is virtual, in reality, physical memory must be allocated somewhere. We cannot ignore the time required for this step because allocating physical memory is not a lightweight operation in general.
On the other hand, in Vnano's VM, the exactly same code initially requires only the exact same size of virtual memory to start up. This is because Vnano's virtual memory stores references to data containers, not the actual data itself, and these containers can be dynamically resized at runtime.
This means that you can reuse the virtual memory space used in the previous execution without releasing and reallocating it, just by reinitializing it. That's precisely what we've implemented.
Furthermore, we've also implemented an additional optimization for this step. In Vnano, you can bind (connect) host application variables to the script engine and such for access from scripts. Binding associates a variable with a specific address in the virtual memory, and the value is loaded during memory initialization. Then, it's written back at the end of execution. We initially didn't pay much attention to the I/O time required for this process, but we found it to be a cause of the degradation in the speed of "repetitive execution," so we've optimized it as well.
Next, let's talk about code optimization. In Vnano, code optimization is performed on the VM side rather than the compiler side. Optimization itself can be a heavy process, so we've implemented caching results of optimization in this update.
There's not much detailed explanation needed here; it's exactly as it sounds.
Moving on to the execution process of the instruction sequence within the VM.
Vnano's VM not only optimizes the inputted code but also optimizes its internal structure. Explaining this concept with words can be a bit challenging, but to give an analogy, it might be helpful to think of something like an FPGA (Field-Programmable Gate Array) structure.
Vnano's VM generates numerous specialized nodes to perform various operations in high-speed, linking them together with reference links. The processing flow traces over these linked nodes and invokes their operations, sequentially executing the instruction sequence with low overhead. Additionally, each operation node internally caches scalar values used only by nearby nodes, minimizing the need to read from or write to the virtual memory. These structural features allow the VM to reduce the costs of instruction dispatch and virtual memory I/O.
Now, the distribution of types of these operation nodes and their optimal connection patterns vary depending on the code being executed. However, regenerating them means creating a large number of instances of nodes, which requires a certain time. Therefore, we've also implemented caching this linked-nodes structure, reusing them when possible.
With the optimizations achieved through caching, we've managed to significantly reduce the execution overhead of the engine itself. However, when we integrate the optimized engine into an application, surprisingly, it's still sluggish for "repetitive exexution". On investigating why, we found an unexpected source of the slowdown.
In Vnano, you can provide built-in functions, variables, and various features to scripts through Java classes that connect to the engine. We refer to these as "plugins". Of cource you can implement your original plugins.
The interface for implementing these plugins was designed to allow various actions at various stages. This includes methods that can be implemented for processes desired right before or right after script execution, referred to as "initialization" and "finalization". Unfortunately, it was these methods that were directly causing the issue.
For instance, if you implement a plugin that accesses file systems or other system resources, you would typically write preparation and cleanup processes in these methods. However, such operations can be heavy in general. Imagine running tens of thousands of computation requests for drawing a high-density 3D mesh - this would result in system resource preparation and cleanup tasks running tens of thousands of times consecutively. Even if the preparation takes only 1 ms, it would take tens of seconds for tens of thousands of iterations. Moreover, during this time, numerous system resource-related operations would rush into the lower layers. It's a major performance bottleneck, and very annoying for the OS!
However, what plugins do during their initialization/finalization is at their discretion, just as it's up to the application how and how often it throws calculation expressions/scripts at the engine. Considering this, it becomes evident that fundamentally, this isn't an issue that can be resolved by merely speeding up the engine.
Therefore, we decided to slightly expand the engine's specification by this update, while maintaining compatibility. Specifically, we introduced options and methods for enabling control like 'initialize the plugin once, execute scripts tens of thousands of times, then call the plugin's finalization process at the end.' For more details, please refer to this document.
With that, we've covered all the implementation improvements made in this update. Let's conclude with a graph depicting the final acceleration results, which was also presented in the previous article:
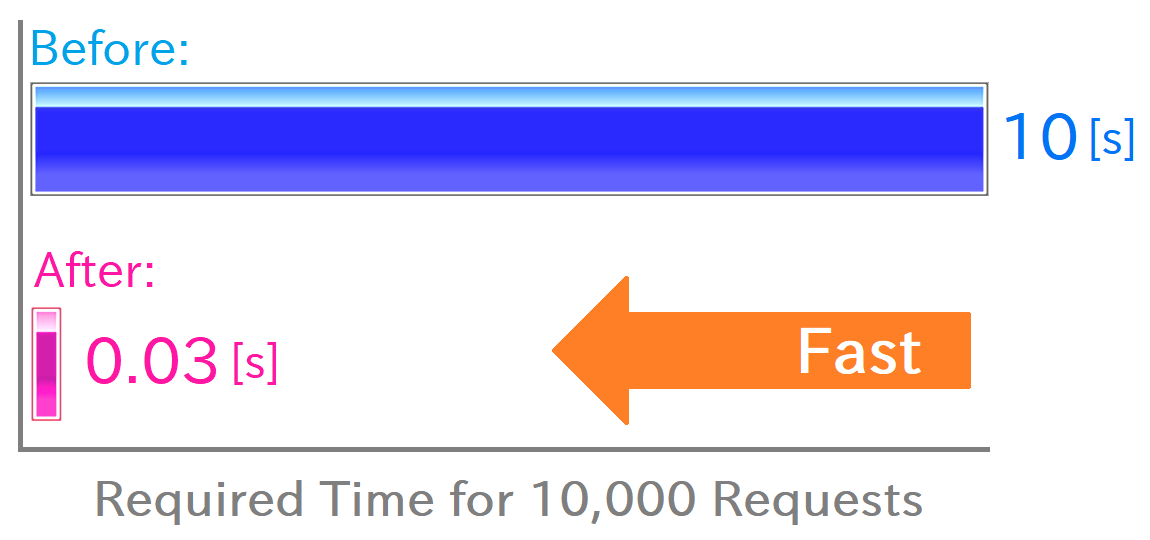
This bar graph represents the time required to process 10,000 requests for mesh calculations on RINEARN Graph 3D. The processing time has been reduced from around 10 seconds to about 0.03 seconds.
Among the time reduction achieved, undoubtedly, over half of it is attributed to the caching effect of the compiled results. Surprisingly, the most significant improvement after that came from optimizing the timing of plugin initialization/finalization processes. The remaining portion (around 10% or so of the total) is shared by other optimizations.
----
Now, this concludes our article for today. Given that the topic was somewhat specialized, making for a more challenging read than usual. If it was a bit tough to read, I apologize. Nevertheless, I hope this article can serve as a reference, even if just a little, for someone somewhere. Until next time!

