
崱夞偺婰帠偼丄慜夞偺懕曇偱偡丅
慜夞偺婰帠偱偼丄Vnano 偺怴僶乕僕儑儞 Ver.1.1 偵偍偗傞夵椙揰偵偮偄偰丄儐乕僓乕栚慄偐傜偍揱偊偟傑偟偨丅 嬶懱揑偵偼丄摨偠寁嶼幃傗僗僋儕僾僩傪孞傝曉偟幚峴偡傞乽斀暅幚峴乿偺張棟懍搙偑丄 媽僶乕僕儑儞斾偱悢昐乣悢枩攞偲戝暆偵岦忋偟偨帠傗丄偦傟偑偳偺傛偆側梡搑偵偍偄偰栶棫偮偺偐丄摍乆傪偛愢柧偟傑偟偨丅
崱夞偼丄媡偵儐乕僓乕栚慄偱偼側偔奐敪懁偺栚慄偐傜丄 乽僗僋儕僾僩僄儞僕儞偺撪晹峔憿偵丄嬶懱揑偵偳偺傛偆側夵椙傪峴偭偨偺偐乿 偲偄偆揰偵偮偄偰夝愢偟偰偄偒偨偄偲巚偄傑偡両
杮戣偵擖傞慜偵丄崱夞偺婰帠偼彮偟摿庩側偺偱丄嵟弶偵乽埵抲偯偗乿偵娭偡傞曗懌愢柧傪偟偰偍偒偨偄偲巚偄傑偡丅 偙傟偼杮婰帠傪慜夞仌崱夞偺2夞偵暘偗偨棟桼偱傕偁傞偺偱偡偑丄 崱夞偺婰帠偼丄晛捠偵儐乕僓乕偲偟偰僗僋儕僾僩僄儞僕儞傪巊偆偨傔偵偍偄偰偼丄傎傏壗偺栶偵傕棫偨側偄忣曬偱偡丅
側偺偱丄Vnano傪巊偭偰偔偩偝偭偰偄傞曽偱傕丄崱夞偺忣曬偵娭偟偰偼丄摿暿偵嫽枴偑暒偔偲偐偱側偗傟偽丄 偙偙偱婰帠傪棧扙偟偰偄偨偩偄偰傕慡偔壗偺巟忈傕惗偠傑偣傫丅 椺偊傞側傜丄偙偺婰帠1夞暘偑傑傞偛偲梋択丄傒偨偄側姶偠偱偡丅
偲偄偆帠偱丄偙偙偱棧扙偣偢偵愭傑偱撉傒恑傔偰偔偩偝傞曽偼丄偁傞掱搙偼尵岅張棟宯偺幚憰偺榖偵丄摿暿側嫽枴傪帩偨傟偰偄傞曽偩偲巚偄傑偡丅 偙傟偐傜愭偺撪梕偼丄偦偆偄偆憐掕偱懡彮怺杧傝偟側偑傜彂偄偰偄偔偨傔丄 偄偮傕傛傝彮偟忕挿偱傗傗偙偟偄撪梕偵側傞偐傕偟傟傑偣傫偑丄偛梕幫偔偩偝偄丅
偦傟偱偼丄堦弿偵尵岅張棟宯偺撪懁偺悽奅偵旘傃崬傒傑偟傚偆両
偝偰丄崅懍壔偺榖偵擖傞偵偼丄傑偢偼慜採偲側傞僗僋儕僾僩僄儞僕儞偺峔憿傪梷偊偰偍偔昁梫偑偁傝傑偡偹丅 偙傟偵偮偄偰偼夁嫀偵丄壓婰偺婰帠偱傑偲傔偨帠偑偁傝傑偡偺偱丄徻偟偔偼偦偪傜傪偛嶲徠偔偩偝偄丗
忋偺婰帠偱傕弎傋偰偄傞捠傝丄Vnano 偺僗僋儕僾僩僄儞僕儞偺峔憿偼丄 乽僐儞僷僀儔乿偲乽VM乮壖憐儅僔儞乯乿偲偄偆2偮偺梫慺傪庡栶偲偟偰惉傝棫偭偰偄傑偡丗
傑偢乽僐儞僷僀儔乿偵偮偄偰偱偡偑丄偙傟偼C尵岅偲偐偺僐儞僷僀儔宆尵岅偱傛偔搊応偡傞丄偁偺乽僐儞僷僀儔乿偱偡丅 儐乕僓乕偑庤偱彂偄偨僐乕僪傪丄摿庩側幚峴梡僐乕僪偵曄姺偟傑偡丅
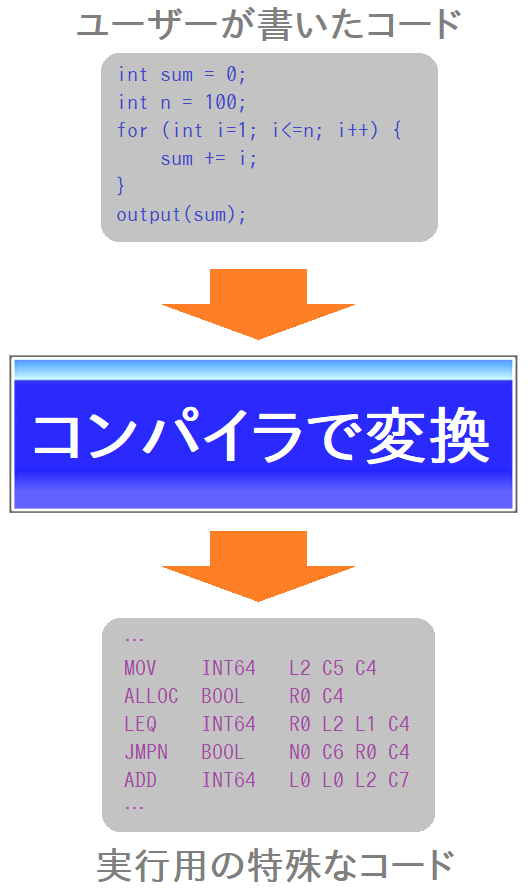
偙偙偱丄 乽偊丠 亀僗僋儕僾僩亁偲屇偽傟傞椶偺僐乕僪偭偰丄晛捠偼僐儞僷僀儖偲偐偣偢偵幚峴偱偒傞傕偺偠傖側偄偺丠乿 偲巚傢傟偨曽丄偦傟偼儐乕僓乕栚慄偱偼惓夝偱偡丅乽僀儞僞乕僾儕僞宆尵岅偺棙揰偺堦偮乿偲偐偱徯夘偝傟傞傗偮偱偡偹丅
偟偐偟丄僗僋儕僾僩張棟偺崅懍壔傪撍偒媗傔偰偄偔偲丄昞偐傜尒偨嫇摦偼偛偔扨弮側僀儞僞乕僾儕僞偺傛偆偵尒偊偰傕丄 寢嬊偼撪晹偱怓乆偲僐儞僷僀儖揑側帠傪傗偭偰偟傑偆偺偑掕愇乮傛偔偁傞庤乯偺堦偮側傫偱偡偹丅
乽偳偺僞僀儈儞僌偱丄偳偺斖埻傪丄偳偆偄偆僐乕僪偵僐儞僷僀儖偡傞偺偐乿偲偄偆偺偼條乆側僶儕僄乕僔儑儞偑偁傝傑偡偑丄 側偵偼偲傕偁傟丄 乽僗僋儕僾僩張棟宯偑丄幚偼撪晹偱僐儞僷僀儖揑側帠傪僈儞僈儞傗偭偰偄傞乿偲偄偆帠偼丄晛捠偵偁傞偁傞偱偡丅 偄傑偙偺儁乕僕傪撉傫偱偄傞Web僽儔僂僓偺 JavaScript 張棟宯傕偦偆偱偡丅
偝偰丄Vnano 偺僗僋儕僾僩僄儞僕儞傕椺偵楻傟偢丄撪晹偵僐儞僷僀儔傪帩偭偰偄偰丄僗僋儕僾僩傪暿庬偺僐乕僪乮屻弎乯偵僐儞僷僀儖偟偰偐傜幚峴偟傑偡丅 棟桼偼丄偦偺曽偑崅懍壔傪媗傔傞忋偱桳棙偩偐傜偱偡丅
偱偼丄偦偺僐儞僷僀儔偼堦懱偳偆偄偆僐乕僪傪揻偔偺偱偟傚偆偐丠 堦斒榑偲偟偰偼丄偙傟偵偼2偮偺僷僞乕儞偑偁傝傑偡丅
堦偮偼丄乽CPU乮亄OS乯忋偱僟僀儗僋僩偵憱傞僐乕僪丄偄傢備傞僱僀僥傿僽僐乕僪乿傪揻偔応崌丅懍偦偆偱偡偹丅 僗僋儕僾僩偺張棟宯偱傕丄乽JIT乮僕僢僩乯僐儞僷僀儖乿偲偐乽JIT乿偑偳偆偙偆偲偐尵傢傟偰傞張棟宯偼偙傟傪傗偭偰偄傞帠偑懡偄偱偡丅 堦墳丄乽JIT乿偲偄偆偺偼丄揻偔僐乕僪偺庬椶偱偼側偔僞僀儈儞僌傪昞偡乮AOT偺懳媊岅乯偺偱偡偑丄偟偐偟傆偮偆JIT偲尵偊偽僱僀僥傿僽僐乕僪傑偱棊偲偡働乕僗偑戝敿偩偲巚偄傑偡丅
偝偰偙偺JIT丄Vnano偱偼柧帵揑偵偼傗傜側偄偺偱偡偑丄壓憌偺Java壖憐儅僔儞偑僶儕僶儕傗偭偰偄偰丄偦偺壎宐偑娫愙揑偵Vnano偵岠偄偨傝偼偟傑偡丅攝楍墘嶼偑SIMD揥奐偝傟偨傝偲偐丅
傕偆堦偮偺僷僞乕儞偼丄Vnano偼庡偵偙偭偪懁側偺偱偡偑丄乽壖憐揑側CPU亄儊儌儕傪柾偟偨丄堦庬偺僀儞僞乕僾儕僞傒偨偄側傗偮偺忋偱幚峴偱偒傞僐乕僪乿傪揻偔応崌丅 乽寢嬊僀儞僞乕僾儕僞傒偨偄側傗偮偱張棟偡傞傫偐偄両乿偲尵傢傟偦偆偱偡偑丄 偟偐偟尦偺僗僋儕僾僩傪偦偺傑傑夝庍丒幚峴偡傞傛傝偐偼丄懍搙偺忋尷傪堷偒忋偘傗偡偔側傝傑偡丅 側偍偐偮丄CPU忋偱捈愙憱傜偣傞応崌偲斾傋偰丄偁傞掱搙偼僗僋儕僾僩岦偒偺廮傜偐偄暥朄傕幚憰偟傗偡偄偱偡丅 傑偁側傫偲偄偆偐丄崅傔偺懨嫤揰傪慱偭偨曽幃傒偨偄側姶偠偱偡偐偹丅 偁偲暿庬偺CPU/僾儔僢僩僼僅乕儉岦偗偵堏怉偟傗偡偔側傞偲偐傕偁傝傑偡乮偲偄偆偐妛弍揑偵偼堦斣偺堄媊偑偨傇傫偦傟乯丅
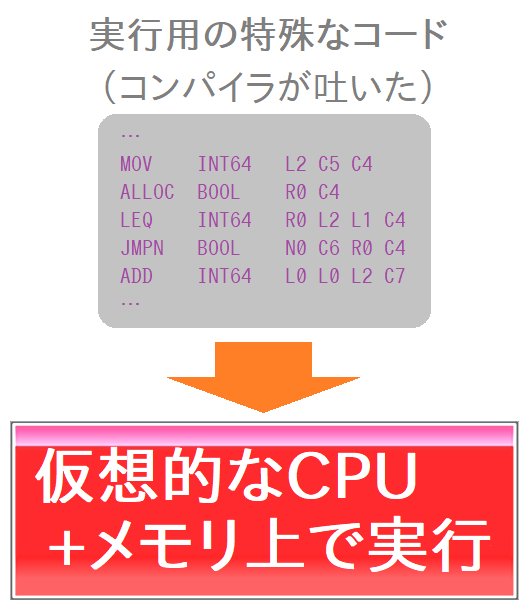
偱丄偙偺乽壖憐揑側CPU亄儊儌儕傪柾偟偨丄堦庬偺僀儞僞乕僾儕僞傒偨偄側傗偮乮堦墳OS娗妽偺張棟傕昁梫嵟彫尷偩偗僇僶乕偟偰傞乯乿偺帠傪丄尵岅張棟宯偺榖偱偼乽VM乮僽僀僄儉乯乿偲偐乽壖憐儅僔儞乿偲偐屇傫偩傝偟傑偡丅 偨偩偟VM傗壖憐儅僔儞偲偄偆尵梩偼懳徾斖埻偑峀偔丄摿偵嬤擭偼丄傕偭傁傜 VirtualBox 偲偐偺乽PC娐嫬慡懱傪壖憐揑偵嵞尰偡傞傗偮乮僔僗僥儉壖憐儅僔儞乯乿傪巜偡帠偑懡偄偱偡傛偹丅 偦傟偲偺崿摨傪旔偗偨偄応崌偵丄堦墳偼乽僾儘僙僗壖憐儅僔儞乿偲偐偺屇傃曽傕偁偭偰丄屄恖揑偵偼偨傑偵巊偄傑偡偑丄偟偐偟偁傑傝堦斒偱偼側偄婥傕偟傑偡丅 傑偨丄彮偟挿偄偱偡偑乽僶僀僩僐乕僪乮傑偨偼拞娫僐乕僪乯僀儞僞乕僾儕僞乿偲偄偆屇傃曽傕偁傝傑偡丅
偦偟偰丄忋偱弎傋偨2偮偺曽幃偺暪偣媄偱丄乽VM偺拞偱JIT傪偐傑偡乿偲偄偆僷僞乕儞傕晛捠偵偁傝傑偡丅 壛偊偰丄乽儐乕僓乕偑嵟弶偵僐儞僷僀儔傪庤偱扏偄偰VM梡僐乕僪傪嶌偭偰丄偦傟偑VM忋偱憱傝偮偮JIT偝傟傞乿揑側傗偮傕偁傝傑偡丅Java偲偐丅僐儞僷僀儖嵳傝忬懺偱偡偹丅
偲偙傠偱丄偙偆偄偆幚忣傪摜傑偊傞偲丄尵岅張棟宯偺撪晹幚憰偵偮偄偰偼丄偄傢備傞乽僐儞僷僀儔宆乿偲乽僀儞僞乕僾儕僞宆乿傒偨偄偵忢偵婏楉偵暘偗傜傟傞榖偱偼側偄帠偑傢偐傝傑偡丅 傓偟傠僐儞僷僀儔宆偠傖側偄乮偲暘椶偝傟傞乯尵岅偺曽偑丄晳戜棤偱偼僐儞僷僀儖偟傑偔偭偰偄傞応崌傕偁傞偁傞側傢偗偱偡丅 媡偵丄嵟嬤偼僐儞僷僀儔偺拞偵幚幙僀儞僞乕僾儕僞偑擖偭偰偄偰丄僐儞僷僀儖帪偵僐乕僪偺堦晹偺幚峴傪嵪傑偣偰偟傑偊傞傕偺傕偁傝傑偡丅
側偺偱丄僐儞僷僀儔宆偲僀儞僞乕僾儕僞宆偲偄偆暘椶偼丄偁偔傑偱傕乽儐乕僓乕偑僣乕儖偲偟偰庤偱僐儞僷僀儔傪扏偔偐偳偆偐乿傒偨偄側帇揰偱偺暘椶側姶偠偱偡偹丅 堦曽偱丄偦偺堘偄偼尵岅巇條偺僨僓僀儞偲偄偆偐丄尵岅偺僉儍儔僋僞乕揑側傕偺偵寢峔塭嬁傪梌偊傞偺偱丄偦偆偄偭偨暘椶偵傕棙揰偼妋幚偵偁傞偲巚偄傑偡丅 彮側偔偲傕丄柍堄枴側暘椶傗帇揰偲偄偆傢偗偱偼慡慠側偔丄屄恖揑偵傕傛偔偦偆偄偆帇揰偐傜尒傑偡丅
偦偆偄偆丄偪傚偭偲愢柧傗暘椶偑傗傗偙偟偄忬嫷偑丄偙偺庬偺尵岅張棟宯偺榖偵偼偁傞丄偲偄偆榖偱偟偨丅
娬榖媥戣丅
偝偰丄慜抲偒偑挿偔側傝傑偟偨偑丄Vnano 偺僗僋儕僾僩僄儞僕儞偵偍偗傞2偮偺乽庡栶乿偑壗偲側偔揱傢偭偨偱偟傚偆偐丅 偙偺2偮偝偊梷偊偰偟傑偊偽丄偁偲偼嬌傔偰娙扨側榖偱偡丅
嬶懱揑偵丄Vnano 偺僗僋儕僾僩僄儞僕儞偑丄偳偆傗偭偰僗僋儕僾僩傗寁嶼幃傪幚峴偡傞偐丠 偲偄偆偲丗
偳偆偱偟傚偆丄傔偪傖偔偪傖娙扨偱偡傛偹丠 偙傟偔傜偄偺棻搙偱挱傔傞偲丄慡懱偺張棟偺棳傟偼偐側傝扨弮側傕偺偱偡丅
幚嵺偵丄埲壓偑 Vnano 偺僗僋儕僾僩僄儞僕儞偺撪晹峔憿傪昞偟偨僽儘僢僋恾偱偡丅奊揑偵偼彮偟偛偪傖偛偪傖偟偰偄傑偡偑丄墿怓偄栴報偑張棟偺棳傟偱偡丅
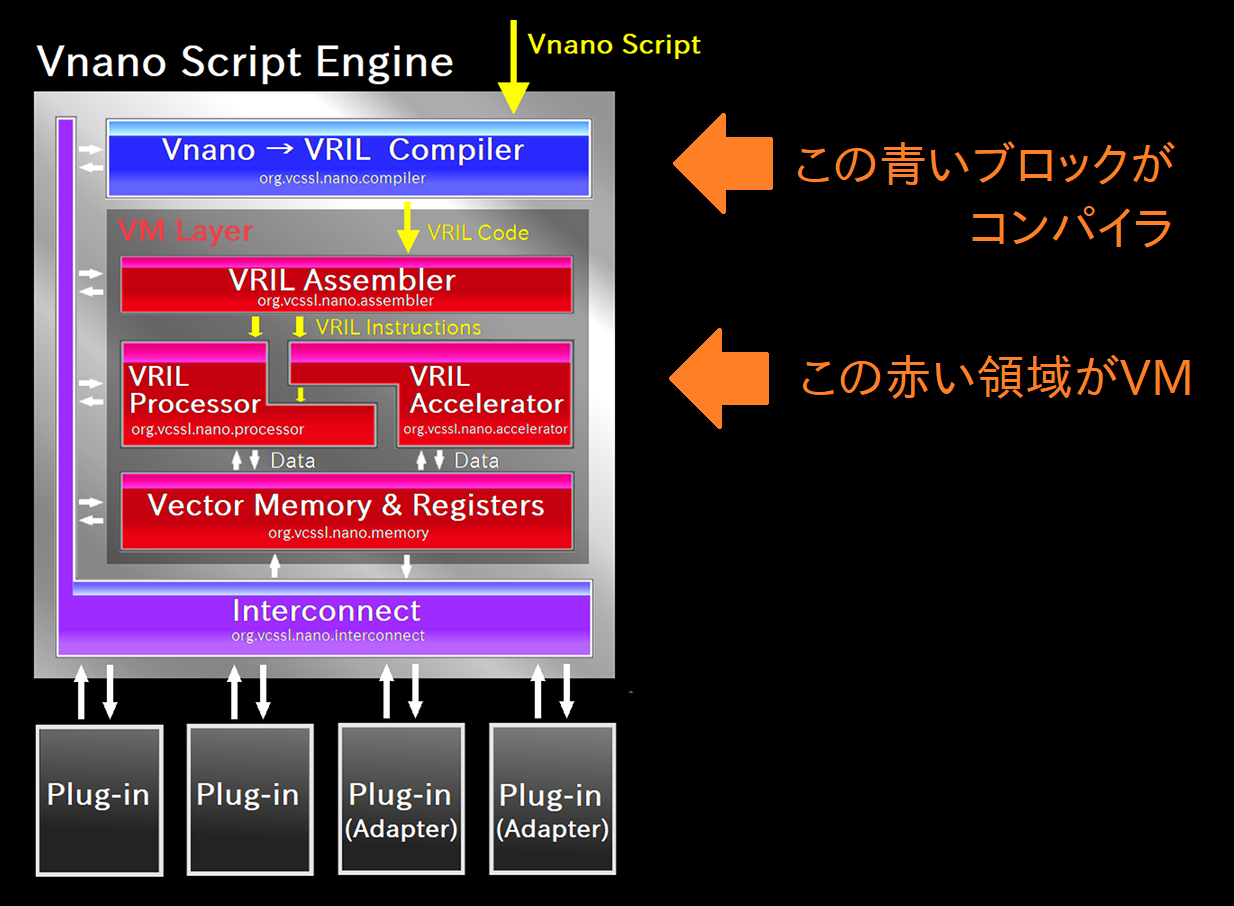
堦斣忋偐傜乽Vnano Script乮偮傑傝僗僋儕僾僩僐乕僪乯乿偑擖偭偰偒偰丄惵偄僐儞僷僀儔傪捠偭偰曄姺偝傟偨屻偵丄愒偄VM椞堟偵擖偭偰張棟偝傟傞偺偑暘偐傝傑偡偹丅 偱丄愒偄VM椞堟偺拞偵偼丄壖憐揑側CPU乮VRIL Processor乯傗儊儌儕乕乮Vector Memory & Registers乯偲偐偑媗傑偭偰偄傑偡丅
崱夞偺崅懍壔偺撪梕傪捛偆偵偼丄偙傟偔傜偄偺偍偍偞偭傁側帇揰偱廫暘偱偡丅 傕偆徻偟偔孈傝壓偘偨偄曽偼丄愭弎偺 傾乕僉僥僋僠儍夝愢偺婰帠 偺曽傪偛嶲徠偔偩偝偄丅
偝偰偙偙偐傜偼丄Ver.1.1 偱幚巤偟偨丄斀暅幚峴偺崅懍壔偺撪梕偵偮偄偰偱偡丅 梫揰傪愭偵傑偲傔偰偟傑偆偲丄乽偲偵偐偔廳偄張棟偺寢壥傪僉儍僢僔儏偟偰嵞棙梡偟傑偔傞乿偲偄偆姶偠偵側傝傑偡丅傛偔偁傞榖偱偡傛偹丅
側偍丄乽 偦傕偦傕斀暅幚峴偲偼丠 乿偲偄偆揰偵偮偄偰偼丄慜夞偺婰帠偱徻偟偔愢柧偟偰偄傑偡偺偱丄偦偪傜傪偛嶲徠偔偩偝偄丅
偦傟偱偼崅懍壔偺嵟弶偺揰偱偡丅傑偢偼堦斣廳偄晹暘傪嶍傞偺偑媫柋偱偡傛偹丅偦傟偼僐儞僷僀儖偺張棟偱偡丅 僐儞僷僀儔偲偄偆偺偼丄捠忢偺応柺偱傛偔彂偔僾儘僌儔儉偲斾傋傞偲丄傗偭傁傝偩偄傇暋嶨側帠傪傗偭偰偄偰丄傑偁側傫偲偄偆偐怓乆偲僄僌偄偱偡丅張棟僐僗僩傕丅
堦墳偼夁嫀偵丄壓婰偺婰帠偱丄僐儞僷僀儔偺撪晹張棟傕孈傝壓偘偰傒偨帠偑偁傝傑偡丅偞乕偭偲棳偟撉傒偟偰偄偨偩偗傞偲丄暤埻婥揑偑揱傢傞偐傕偟傟傑偣傫丗
忋偺婰帠偼偪傚偭偲挿偄偺偱丄峴偆張棟偩偗傪恾偵偟偨傕偺傪敳偒弌偡偲丄壓恾偺傛偆側曄姺張棟傪偟傑偡丗
堦斣忋偵乽Script Code乿偲偁傞偺偑丄僗僋儕僾僩僐乕僪撪偵娷傑傟傞堦峴偺幃偱丄偦偺曄姺夁掱傪捛偄偐偗偨恾偵側偭偰偄傑偡丅 塃壓偺乽VRIL Code乿偲偄偆偺偑曄姺寢壥偱偡丅 徻嵶偼忋婰偺婰帠偵忳偭偰妱垽偟傑偡偑丄偆傢偭丄側傫偐廳偦偆側曄姺張棟偩側偀乧 偲偄偆偺偑揱傢傞偲婐偟偄偱偡丅
幚嵺偵丄乽偙偙偺強梫帪娫傪嶍傟側偄偲丄懠偺偳偙傪嶍偭偰傕從愇偵悈偩傛乿偭偰偔傜偄偵偼廳偄偱偡丅偠傖偁偳偆傗偭偰嶍傞偐丄偲偄偆榖偱偡偹丅
捈媴偺傾僾儘乕僠偲偟偰偼丄傑偢僐儞僷僀儔偺張棟懍搙傪懍偔偡傞帠丅偙傟偼傕偪傠傫桳岠側庤偱偡丅 偟偐偟丄Vnano 偼偦傕偦傕丄傾僾儕撪慻傒崬傒梡偵嶌偭偨尵岅仌張棟宯側偺偱丄嵟弶偵尵岅巇條傪寛傔傞帪揰偐傜僐儞僷僀儖懍搙傪寢峔廳帇偟偰偄偰仸丄幚憰帪偵傕傕偪傠傫廳帇偟偰偄傑偟偨丅 側偺偱丄偙傟偼傕偆夁嫀偵婛偵傗偭偰偄偰丄偦偙偐傜寑揑偵嶍傟偦偆側梋抧偼偁傑傝巆偭偰偄傑偣傫偱偟偨丅
偲偡傞偲丄師偺庤偲偟偰偼乽慜夞偺僐儞僷僀儖/僷乕僗寢壥傪僉儍僢僔儏偟偰偍偄偰丄師偺擖椡偑摨偠側傜丄僉儍僢僔儏偝傟偨寢壥傪棳梡偡傞乿偲偄偆偺偑掕斣偱偡傛偹丅 Python 偲偐偱傕傗偭偰偄傑偡偟丄偆偪偱奐敪偟偰偄傞懠偺尵岅張棟宯乮VCSSL偲偐Exevalator偲偐乯偱傕傗偭偰偄傑偡丅
偙傟偼 Vnano 偱偼傑偩枹拝庤偱偟偨丅偲偄偆偺傕丄Vnano 偼惓幃儕儕乕僗偑擭扨埵偱抶傟偰偟傑偭偨帠傕偁傝丄搑拞偐傜惈擻柺傛傝傕婡擻柺傪屌傔傞帠傪桪愭偟偨偨傔偱偡丅 側偺偱崱夞幚憰偟傑偟偨丅寢壥偲偟偰丄斀暅幚峴帪偺僐儞僷僀儖帪娫傪傎傏僛儘偵偱偒偨偺偱丄偙傟偱懠偺晹暘偺崅懍壔偵恑傔傞傛偆偵側傝傑偟偨丅
懕偄偰VM懁偱偡丅VM偺懍搙偲偄偆偲柦椷幚峴偺懍搙偑僀儊乕僕偵晜偐傃傑偡偑丄堄奜偲栍揰側偺偑丄壖憐揑側儊儌儕乕偺弨旛偵偐偐傞帪娫偱偡丅
Vnano 偺 VM 偼儗僕僗僞儅僔儞宆側偺偱丄柦椷僐乕僪傪幚峴偡傞偵偼丄幚峴帪偵巊偆壖憐揑側儊儌儕乕椞堟傪妋曐偟側偄偲偄偗傑偣傫丅 柦椷僐乕僪偑傾僋僙僗偡傞斣抧偑偪傖傫偲妋曐偝傟偰偄側偄偲丄抣傪撉傒彂偒偱偒偢偵棊偪偰偟傑偄傑偡丅
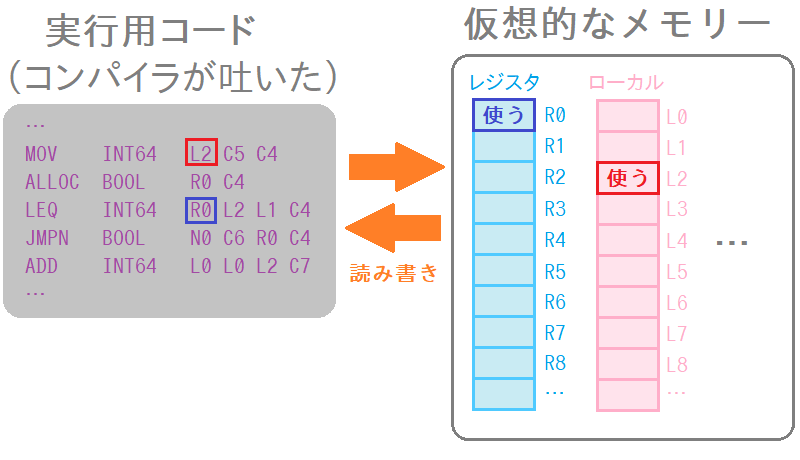
偱丄偙偺儊儌儕乕偼壖憐揑側傕偺偲偼尵偭偰傕丄幚懱偼偳偙偐偵幚儊儌儕乕偑妋曐偝傟傞帠偵懠側傝傑偣傫丅側偺偱妋曐張棟偼偦偙偦偙廳偄偱偡丅
堦曽丄慡偔摨偠柦椷僐乕僪傪幚峴偡傞側傜丄弶婜忬懺偱偼慡偔摨偠挿偝偺椞堟偑梡堄偝傟偰偄傟偽昁偢懌傝傞帠偑丄乮堦斒榑偲偟偰偼尵偊側偄偺偱偡偑乯Vnano 偺VM偱偼曐徹偱偒傑偡丅 偙傟偼丄Vnano 偺壖憐儊儌儕乗偑丄僨乕僞偺幚懱偱偼側偔丄僨乕僞偺僐儞僥僫傊偺嶲徠傪奿擺偡傞偨傔偱偡丅偦偟偰僐儞僥僫偼儕僒僀僘偑壜擻偱偡丅
偲偡傞偲丄慜夞幚峴偵巊偭偨壖憐儊儌儕乕椞堟傪丄夝曻仌嵞妋曐偣偢偵丄嵞弶婜壔偩偗偟偰巊偄傑傢偡帠偑壜擻偱偡丅 偲偄偆帠偱丄偦傟傪庢傝擖傟傑偟偨丅
傑偨丄Vnano 偱偼丄儂僗僩傾僾儕働乕僔儑儞懁偺曄悢側偳傪丄僗僋儕僾僩懁偐傜傕傾僋僙僗偱偒傞傛偆偵僶僀儞僨傿儞僌乮佮愙懕乯偱偒傞偺偱偡偑丄偦傟傕偙偙偵彮偟娭學偟傑偡丅 偲偄偆偺傕丄僶僀儞僨傿儞僌偟偨曄悢偼丄壖憐儊儌儕乗偺摿掕傾僪儗僗偲昍偯偗傜傟丄壖憐儊儌儕乗弶婜壔帪偵抣偑儘乕僪偝傟傑偡丅偦偟偰丄幚峴廔椆帪偵儔僀僩僶僢僋偝傟傑偡丅 偦偺偁偨傝偺I/O強梫帪娫傕丄摉弶偁傑傝婥偵偟偰偄側偐偭偨傫偱偡偑丄斀暅幚峴偱偼堄奜偲岠偄偰偒偨偺偱崅懍壔偟傑偟偨丅
懕偄偰丄僐乕僪偺嵟揔壔偱偡丅Vnano 偱偼丄僐儞僷僀儔懁偱偼側偔VM懁偱僐乕僪嵟揔壔傪峴偆偺偱偡偑丄 嵟揔壔傕側偐側偐廳偄張棟偩偭偨傝偟傑偡丅偙傟傕慺捈偵崱夞偐傜僉儍僢僔儏偟偰偄傑偡丅
偙傟偵偮偄偰偼丄摿偵徻偟偔愢柧偑昁梫側撪梕偼側偔丄杮摉偦偺傑傑偱偡丅
師偵丄VM偺拞偱丄柦椷楍傪幚峴偡傞張棟偵偮偄偰偱偡丅
偙傟偼偪傚偭偲尵梩偱愢柧偟恏偄偺偱偡偑丄Vnano 偺VM偼丄擖椡偝傟偨僐乕僪偺嵟揔壔偩偗偱側偔丄暪偣偰VM帺恎偺撪晹峔憿傕嵟揔壔偟傑偡丅
椺偊傞側傜 FPGA 偺巇慻傒偲偐傪僀儊乕僕偟偰傕傜偊傞偲妱偲僺儞偲偔傞偐傕偟傟側偄偺偱偡偑丄Vnano 偺VM偼丄奺庬偺墘嶼傪愱梡偱峴偆僲乕僪傪戝検偵惗惉偟丄偦傟傜偺娫傪嶲徠偺儕儞僋偱楢寢偟傑偡丅 偦偟偰丄偦偺楢寢峔憿偺忋傪僼儘乕偑憱傞帠偱丄柦椷楍傪掅僆乕僶乕僿僢僪偱拃師幚峴偟偰偄傑偡丅 傑偨丄奺墘嶼僲乕僪偼丄嬤朤僲乕僪偱偟偐巊梡偝傟側偄僗僇儔抣傪撪晹偱僉儍僢僔儏偟偰偄偰丄偦偺偨傔昁梫嵟彫尷偺僞僀儈儞僌偱偟偐壖憐儊儌儕乗傪撉傒彂偒偟偵峴偒傑偣傫丅 偙傟傜偺峔憿偵傛偭偰丄Vnano 偱偼丄柦椷僨傿僗僷僢僠偲壖憐儊儌儕乗I/O偺僐僗僩傪嶍傝崬傫偱偄傑偡丅
偱丄偙偺墘嶼僲乕僪孮偺庬椶偺暘攝嬶崌傗丄嵟揔側宷偑傝嬶崌偲偄偆偺偑丄幚峴懳徾偺僐乕僪偵傛偭偰堎側傝傑偡丅 偟偐偟丄嵞惗惉偡傞偲戝検偺僀儞僗僞儞僗傪惗惉偟傑偔傞帠偵側傞偺偱寢峔廳偄傫偱偡偹丅側偺偱丄偙傟傕僉儍僢僔儏偟偰丄棳梡壜擻側応崌偼棳梡偡傞傛偆偵偟傑偟偨丅
乧偲丄偙偙傑偱偺僉儍僢僔儏嵳傝偱丄僄儞僕儞扨懱偱偺幚峴僆乕僶乕僿僢僪偼廫暘偵嶍傟偰懍偔側傝傑偟偨丅偟偐偟丄偦傟傪傾僾儕偵愊傫偱傒傞偲傒傞偲壗屘偐傑偩廳偄傫偱偡偹丅 側偤偩丄偲巚偭偰扵偡偲丄堄奜側強偑懌傪堷偭挘偭偰偄傑偟偨丅
Vnano 偱偼丄慻傒崬傒娭悢傗曄悢傪僗僋儕僾僩偵採嫙偟偨傝丄偦偺懠怓乆側婡擻傪採嫙偡傞偨傔偺僋儔僗傪 Java 偱幚憰偟偰丄僄儞僕儞偵愙懕偱偒傞傛偆偵側偭偰偄傑偡丅偦傟傪僾儔僌僀儞偲屇傃傑偡丅
偱丄偦偺僾儔僌僀儞傪幚憰偡傞偨傔偺僀儞僞乕僼僃乕僗偼丄屻乆偺帠傪峫偊偰丄寢峔怓乆側僞僀儈儞僌偱怓乆側帠傪偱偒傞傛偆偵僨僓僀儞偟偰偄傑偡丅 偦偺拞偵丄乽僗僋儕僾僩偺幚峴捈慜偵峴偄偨偄張棟乿偲偐乽幚峴捈屻偵峴偄偨偄張棟乿偲偐偑偁傟偽幚憰偱偒傞儊僜僢僪傕愰尵偟偰偄偨傫偱偡偑丄偦傟偑捈愙尨場偱偟偨丅
椺偊偽丄僼傽僀儖側偳偺僔僗僥儉儕僜乕僗偵傾僋僙僗偡傞僾儔僌僀儞傪幚憰偡傞応崌丄忋婰偺儊僜僢僪偵偼丄偦偺偨傔偺弨旛偲屻巒枛傪婰弎偡傞帠偵側傝傑偡丅偟偐偟丄偦傟偼偦偙偦偙廳偄張棟偱偡傛偹丅 偦偙偵丄崅枾搙儊僢僔儏偺3D僌儔僼傪昤偔偨傔偵丄悢枩夞偺寁嶼儕僋僄僗僩偑搳偘傜傟傞偲丄僔僗僥儉儕僜乕僗偺弨旛偲屻巒枛偑悢枩夞偲偐楢懕偱憱偭偰偟傑偄傑偡丅 壖偵弶婜壔1夞偑1ms偱廔傢偭偰傕丄悢枩夞偵偼悢廫昩偐偐偭偰偟傑偄傑偡丅偟偐傕偦偺娫丄僔僗僥儉儕僜乕僗娭楢偺偁傟偙傟偑僿價乕偵憱傝傑偔傞丅壓憌儗僀儎乕僽僠僊儗埬審偱偡偹丅偦傟偼傑偢偄丅
偐偲尵偭偰丄僾儔僌僀儞偑偳傫側弶婜壔/廔椆帪張棟傪偡傞偐偼僾儔僌僀儞偺帺桼偩偟丄傾僾儕懁偑偳傫側寁嶼幃/僗僋儕僾僩傪偳傫側昿搙偱搳偘傞偐傕傾僾儕懁偺帺桼偩偟乧 偲峫偊傞偲丄偙傟偼杮幙揑偵丄僄儞僕儞偺崅懍壔偱偳偆偙偆偱偒傞栤戣偱偼側偄傢偗偱偡丅
偲偄偆帠偱丄嵟廔揑偵偼僄儞僕儞偺巇條傪彮偟奼挘偟傑偟偨乮屳姺偼曐偪偮偮乯丅 嬶懱揑偵偼丄椺偊偽乽嵟弶偵堦夞僾儔僌僀儞傪弶婜壔偟偰丄偦偺屻悢枩夞偲偐僗僋儕僾僩傪幚峴偟丄嵟屻偵僾儔僌僀儞偺廔椆帪張棟傪屇傇乿偲偄偭偨惂屼傪壜擻偵偡傞僆僾僔儑儞偲儊僜僢僪傪擖傟傑偟偨丅 徻嵶偼偙偪傜嶲徠偱偡丅
偲丄埲忋偱丄崱夞巤偟偨幚憰忋偺夵慞揰偼偡傋偰尒廔傢傝傑偟偨丅嵟廔揑側崅懍壔偺寢壥偼丄慜夞傕宖嵹偟傑偟偨偑丄崱夞傕乊偺恾偲偟偰揬偭偰偍偒傑偟傚偆丗

偙偺朹僌儔僼偼丄儕僯傾儞僌儔僼3D忋偱偺儊僢僔儏寁嶼偺偨傔偵1枩儕僋僄僗僩傪搳偘偨張棟偺強梫帪娫偱丄10昩偑0.03昩偔傜偄偵側偭偨丄偲偄偆寢壥偱偡丅
偙偺強梫帪娫偺抁弅暘偺偆偪丄娫堘偄側偔敿暘埲忋偑僐儞僷僀儖寢壥偺僉儍僢僔儏偺岠壥偱偡丅巆傝偺拞偱堦斣戝偒偐偭偨偺偑丄堄奜偵傕僾儔僌僀儞偺弶婜壔/廔椆帪張棟偺僞僀儈儞僌嵟揔壔偵傛傞傕偺偱偡丅 偝傜偵巆傝偺暘乮慡懱偺1妱偁傞偐側偄偐偔傜偄乯傪丄懠偺夵慞偺岠壥偑怘偄崌偆姶偠偱偡偹丅
仦
偝偰丄偙傟偱崱夞偺婰帠偼埲忋偱偡偑丄傗偭傁傝旕忢偵儅僯傾僢僋側暤埻婥偵側偭偰偟傑偄傑偟偨偹丅扤偵壗傪揱偊偨偄偺偐撲偺婰帠偱偡丅傗偭傁傝2夞偵暘偗偰惓夝偱偟偨丅 偲偼偄偊丄偳偙偐偱扤偐偺壗偐偺嶲峫偵丄1儈儕偱傕側偭偰偔傟傞偲婐偟偄偱偡丅傕偆寢傃偺暥傪岺晇偟偰傕從愇偵悈側偺偱搨撍偵廔傢傝傑偡偹丅偦傟偱偼両
