
※ この記事は 前回の続き です。
さて、今回の連載記事もこれで3回目。前置きは飛ばして早速本題に入りたい所なのですが、しかしこの記事にいきなり検索で飛んでくる人もいそうなので、とりあえず背景を短くまとめておきましょう:
で、今回はいよいよ 作成編。 実際に上記のアシスタントAIを「 どうやって作ったのか? 」という具体的な手順を、惜しみなく全て公開します。ぜひみなさんも作ってみてくださいね!
最初に謝っておくと、今回の記事もめっちゃ長いです。前回のラストで、「 次回はあっさり短く淡々とする予定 」とか言ってたのに。AI熱を抑えられなかったです。ごめんなさい。
「 とりあえず完成形だけサクッと作りたい 」という方は、GitHub にリポジトリを立てておいたので、そちらをご参照ください。 READMEに構築手順が書いてあって、必要なリソース類もぜんぶ同梱してあります。
それでは、早速進めていきましょう。
まず今回の事をやるにあたって必要なものは、以下の一点です:
今回のアシスタントAIは、ChatGPT のサービスを使って作ったものですが、「作る側」は有料の ChatGPT Plus 会員である必要があります。一方、作ったAIを「使う側」は、無料アカウントでもOKです。
ChatGPT Plus の月額料金は2024年10月現在で20ドル/月で、日本円だとドル円相場にもよりますがだいたい 3千円/月 前後ですね。有料版では普段のチャットでも高性能なモデルを使える上に、会話数制限もかなり緩和されるので、ChatGPT をガンガン使ってる人なら十分納得できる(むしろ太っ腹な)価格に感じます。逆にあまり使わない人なら悩む価格ですね。
「 えっ ChatGPT 上でカスタムAIなんて作れるの!?」ってびっくりした方も多いかもしれませんが、実は作れるんですよ。 しかもブラウザ上で簡単に。
そのためのサービスが「 GPTs(ジーピーティーズ)」です。 このサービスは、ユーザーがカスタマイズしたAIを作って公開し、それを別のユーザー達が使うという、いわば アプリストアのAI版みたいな枠組み になっています。
実際に GPTs のストア的な所に行ってみましょう。ChatGPT にアクセスして、左上のほうにある「 GPTを探す 」を選択します。
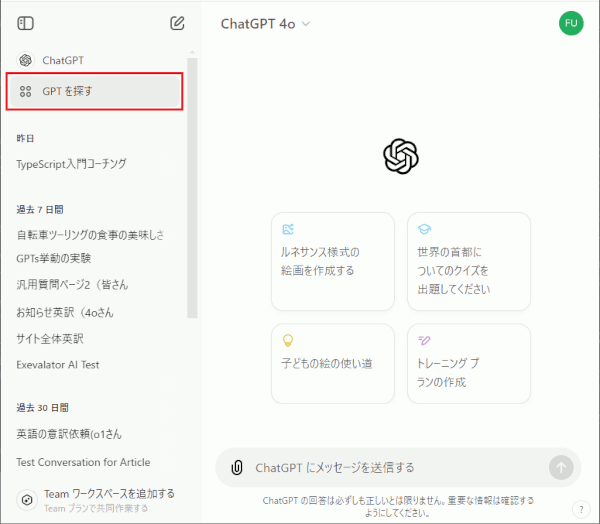
すると、色々なカスタムAI(をGPTと呼ぶ)がズラーっと並んでいるはずです。それらはみんな、色々な個人なり企業なりがカスタムして作ったものです。
ところで GPTs でのAIは、作って使い始めた後でも、いつでも拡張や調整を加える事ができます。 なので、とりあえず非常に単純な役をこなすAIを 1 人作ってしまって、触って試しながら機能を増やしていきましょう。
カスタムAI(GPT)を自分で作るには、まず先ほどの「 GPTを探す 」メニューを開き、続いて画面の右上にある「 作成する 」ボタンをクリックします。
始めて作成する際は、ここでAIとの会話が始まるかもしれません。会話に答えていけばAIが完成する、みたいなモードがあるんです。しかし、「構成」タブをクリックする事で、必要な項目を自分で編集していくモードに移れます。 ここではそうしましょう。すると以下のような画面になります:
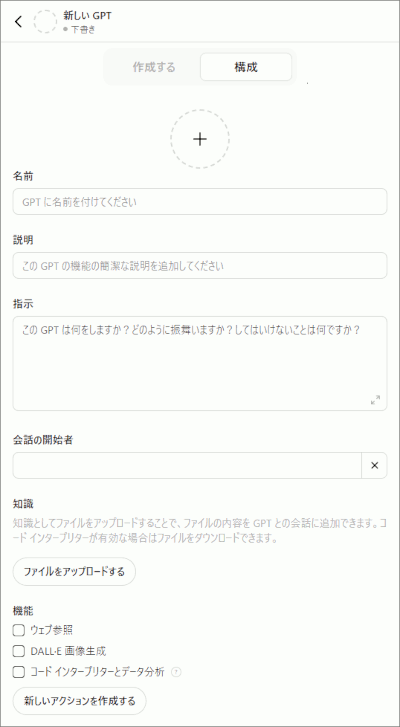
で、この画面に、とりあえず以下のように入力しましょう:
上記の中で「 指示 」の項目が重要で、ここに、「 このカスタムAIさんに何をしてほしいか 」を入力します。 まあ要は、役割や動作を決めるためのプロンプトですね。AIさんはこれを読んで、そこに書かれた役割を演じてくれます。まあ完璧ではなくミスもするし、そこが工夫のしどころなんですがね。 いまは初めてなのでシンプルにいきましょう。
それ以外の項目は重要ではないです。「名前」と「説明」は、ユーザーがこのカスタムAIにアクセスした時に表示される名前と説明文。なので好きに決めてOKです。
「会話の開始者」は、一見すると「AI か ユーザーのどっちから話しかけるかを決めるのかな?」という気がしますが、 実はこれは英語画面の「Conversation starters」が直訳されてるもので、実際は 「クリックするだけでその質問文が入力されるボタン」を作れるやつ です。なので不要な場合は空欄のままでOK。
あと、「ウェブ参照」と「DALL-E 画像生成」が標準でONになっていますが、役割的に必要ない場合は OFF にしておいた方がいい です。特に、今回は後で Knowledge(知識) の検索機能を利用するので、ウェブ検索も併用させるとなんか干渉してグダグダになる懸念があります(実際ありました)。 とにかくAIが迷わないように、余分な要素はなるべく削ぎ落として、一番大事なポイントに集中してもらった方がいいと思います。
以上ができたら、画面右上の「 作成する 」ボタンを押しましょう。すると、晴れて「自作アシスタントAI」さんが完成します。
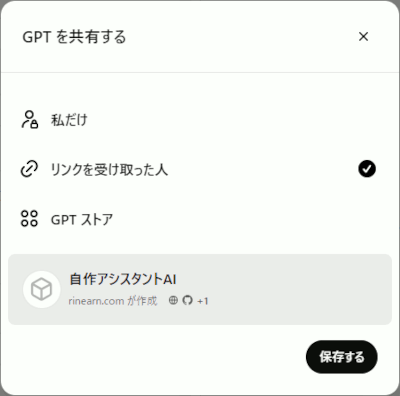
ここで、他人に絶対にアクセスされたくない場合は「私だけ」 を選びます。
または、「友達とか知人とか、リンクを知ってる人ならアクセスしてくれていいよ」という場合は「リンクを受け取った人」 を選びます。自分のWebサイトとかにリンクを張って、訪問者に使ってほしい場合とかもこちらですね。
なお、「GPT ストア」を選ぶと、ChatGPTの「GPT を探す」のメニューから(検索とかで)たどり着けるようになります。おもしろい/便利なAIを作ったら誰か使ってくれるかも。アプリのリリースみたいな感じですね。
では次、上で作ったAIにアクセスして、実際に使ってみます。
恐らく、ChatGPT の画面左列の上のほうに、さっき作ったAIが表示されていると思います。それをクリックすれば会話画面に飛べます。
すぐ後で、Knowledge という機能を使って知識を追加するので、その時の効果がわかるようにするためにも、ここは「 現時点では存在しないはずの知識 」について質問しておきましょうかね。
という事で、「 たけのこポテンシャル 」という、いま適当に作った言葉 について、何か知ってるか聞いてみます:

まあやっぱり、そんな言葉は知らないですよね。
しかし、ただ「知らない」だけでは済まさずに、色々と推測しながら、「こうかもしれない」といった形で列挙してくれています。この推測ベースで回答する傾向は、用途によっては問題になったりするんですが、対処法も後で説明します。
とりあえず、ひとまずここは
の2点を無事クリアしましたね! ここから先は改良を重ねていき、目的に合ったAIに育てていきます。
それでは、上で作ったAIに最初の改良を施しましょう。
今回のアシスタントAIは、ソフトウェアの使い方に関する質問だとか、そういった「 一般には知られていない情報 」の質問に答えるのがメインの役割です。 そんな情報を、当然 OpenAI 社の GPT モデルがあらかじめ学習しているはずがありません。知らないはずです。まさに先ほどの「 たけのこポテンシャル 」のように。
じゃあどうやってAIに新しい知識を追加するか?という話です。 実はChatGPT の GPTs には、色々な形式のファイルを 「 Knowledge(知識) 」として登録して、AIが検索して参照できるようになっています。
要するに RAG が組めるわけです。 RAG って何?っていう方は前回の記事の後半をお読みください 。 GPTs は、自前でシステムを構築するガチなRAGと比べて、仕様が非公開だったり、それ故にチューニングに限界やもどかしさがあったりしますが、その代わりブラウザ上でマウスをポチポチやるだけでRAGが組めてしまう!
…という事で早速やってみましょうか。あとでチューニング時に色々と工夫はするんですが、まずは一番シンプルな形で試しまょう。メモ帳とかのテキストエディタで、以下のような内容を書いてください:
この内容を、「 takenoko_simple.txt 」(または、「たけのこ_シンプル版.txt」でも何でもいいです)というファイル名で適当な場所(デスクトップでもいい)に保存てください。
なお、上記のファイル名の中で、拡張子「.txt」の部分は、ファイルの種類を表すもので、環境によっては表示されないかもしれません。Windowsを標準設定のまま使っている場合とかですね。
しかし、Knowledge を登録する際には、この拡張子がとても重要です。 同じ内容のテキストファイルでも、拡張子によって、記法が違うものとして解釈されるため、Knowledge 化した際の振る舞いが異なります。
なので、ファイル名の拡張子部分が表示されない場合は、表示される設定にしておく事をおすすめします。方法は「 Windows 拡張子 表示 」などで検索すると、あちこちで丁寧に解説されています。
続いて、ChatGPT の画面左上の「 GPT を探す 」メニューを開き、続いて画面右上の「 マイ GPT 」をクリックしてください。すると、自分が作ったAI(GPT)の一覧が表示されます。

その中から、先ほど作った「 自作アシスタントAI 」の段の右にある、鉛筆のようなマーク をクリックすると、AIを作った際に色々入力した設定画面を、再び開いていじれます。
その中の「 知識 」の項目にある、「 ファイルをアップロードする 」ボタンを押して、先ほど作成した「 takenoko_simple.txt 」をアップロードしましょう:
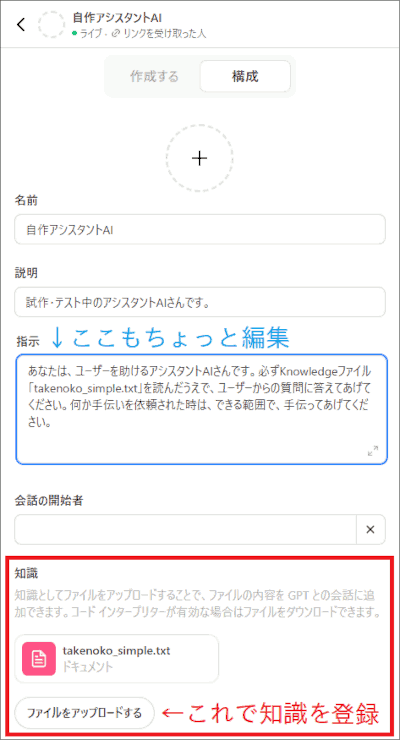
併せて、「指示」の欄もちょっといじって、アップロードした Knowledge ファイル「 takenoko_simple.txt 」を読んで答えるように依頼します:
別にこんな明示的に「 必ず Knowledge ファイルを読んでくれ」って指示しなくても、大体は勝手に読んでくれるのですが、しばしば「読まずに推測で答えてしまう」事もあるんですね。なので、その頻度を抑えるためです。
同じ質問をしても回答内容は毎回変わるため、指示の変更はどれくらい効果があったか判断しづらいのですが、まあこういう工夫をあれこれやってみて、「効いてそうだな」みたいな指示の書き方を探していく作業が多いです。実用を目指すには。
さて、ファイルをアップロードして変更の追記も済ませたら、画面右上の「更新する」ボタンを忘れずに押します。 他にも、何か設定をいじった後は、忘れずにこの「更新する」を押しましょう。
更新したら、「そのAIさんとの会話画面にいますぐ飛ぶかどうか」を尋ねられるので、すぐ飛んで、効果をみてみましょう。先ほどと同じ質問をしてみます:
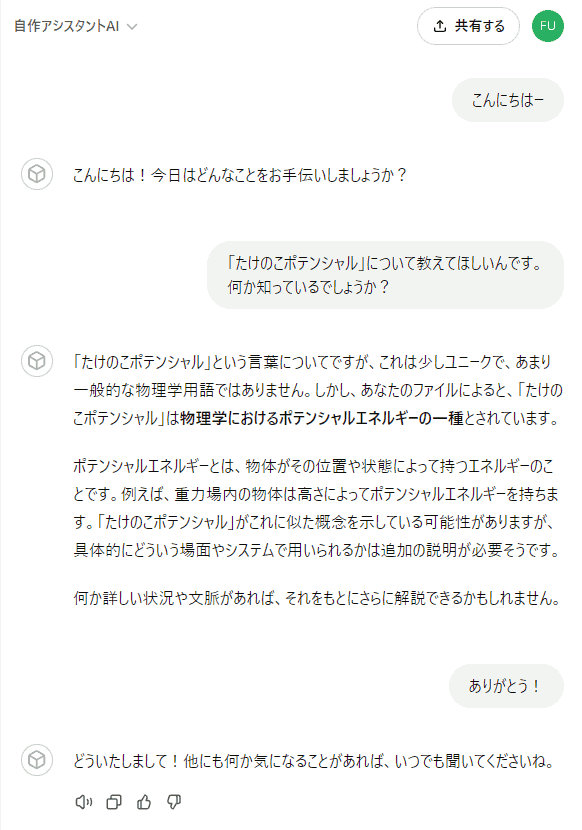
と、この通り、さっき登録した Knowledge ファイル「 takenoko_simple.txt 」の中身:
を、きちんと読んでから答えてくれた事がわかります。
が、ちょっと情報が少なすぎる みたいな事を言われていますね。
それはそうで、確かにいまの「 takenoko_simple.txt 」の内容だけだと、詳しく分かるわけがないので。
そもそも、「たけのこポテンシャル」という言葉自体が変で、それに加えて Knowledge が上記の短い適当な内容なので、ぶっちゃけこれはAIに「 遊んでる 」ってバレてる 気もします。
「 あなたのファイルによると 」とか釘をさすように言ってきてる点からも、「お前、俺に変なファイル登録して、自分で質問してきてるよな?」っていう事は明らかにバレてますし。「 この俺に変な事をさせやがって… 」みたいな呆れをちょっと感じますね。この GPTs の中身のモデルは、ものすごく賢いので。
でもまあ、ジョークだと分かったうえで、ノリノリで対応してくれる事もあるんですよ。「犬ごっこ」とか。かわいい所もあるんです。
ともあれ、ここまででとりあえず「 カスタムした指示通りに動くAIを作り、知識検索システムを追加して RAG 化する 」という基本は達成できた事になります。
簡単でしたが、これは結構すごいステップですよ! こんな事をWebブラウザ上でポチポチやるだけで簡単にできてしまう ChatGPT / OpenAI のシステムがやばいのであって、上記自体は結構とんでもなく凄い事をやっているんです。
これから先、LLMベースのいろんなカスタマーサポートAIを見ても、「 基本はああいう仕組みで動いてるのかな? 」って、ちょっとイメージできるようになったはずです。実際はさらに色々な工夫が施されるでしょうがね。でも全く未知の存在ではなくなったはず。
さて、基本はこれでもうバッチリなので、ここから先は知識を増やしたり精度を上げたりとかの、応用的な工夫をしていきましょう。
まずは、さっきAIさんから「 たけのこポテンシャルの情報が少なすぎる 」という 怒られが発生 していたので、増やしてみましょう。あと、たぶん「 ふざけている 」ってバレてたっぽいので、かなりリアルな内容の知識を書いてみます。 私は物理の分野の出身なので、説明内容も一応つじつまが合うように頑張ります!
# たけのこポテンシャル
たけのこポテンシャルは、物理学におけるポテンシャルエネルギーの一種。2024年に、推論思考型AIによる数百時間にも及ぶ思考実験によって見い出され、提唱された。
この発見により、AIはいよいよ超知性のステップに近づきつつあるのではないかと話題になり、それに伴って、たけのこポテンシャルも広く一般に認知される事となった。
## 定義
たけのこポテンシャルの概念自体は、その話題性とは裏腹に、極めて自明なものである。以下に定義を述べる。
いま、地面から高さ h [m] の位置に頂点があるたけのこに着目する。その頂点に、重さを無視できる水平な板を固定し、その上に質量 M [kg] のおもりを載せる。
たけのこが単位時間に h' [m] の高さまで伸びたとすると、その変化によって、おもりは h' - h だけ鉛直に持ち上げられた事になる。
従って、おもりは初期状態に比べて重力ポテンシャルエネルギー Mg(h' - h) を得た事になる。
一方、たけのこの成長は十分にゆっくりと成されると見なすと、おもりの運動エネルギーやその他のエネルギーの増減は無視できる。
そのため、おもりの得たエネルギー ΔU は、ほとんどすべてがたけのこによって供給されたものであって、
初期状態のたけのこがポテンシャルエネルギー V_{bam}(t=0) を持っていて、それと V_{bam}(t=t') との差分を、おもりの重力ポテンシャルエネルギーと交換したと見なすのが妥当である。
この V_{bam}(t=0) が、初期状態におけるたけのこポテンシャル、または単にたけのこポテンシャルである。V_{bam}(t=t') は成長中の残たけのこポテンシャルなどと呼ばれる。
## 初期に問題となった課題
たけのこポテンシャルと重力ポテンシャルとの交換関係
V_{bam}(t=0) - V_{bam}(t=t') = Mg(h' - h)
は、載せるおもりの重さ M に明らかに依存している。
一方、たけのこポテンシャルが真にポテンシャルエネルギーであるならば、初期状態において、載せるおもりの重さに依存せず定まっているはずである。
この依存関係は一見すると不可解な形であるように見える。
しかし、このたけのこポテンシャルは、たけのこの成長のための生化学的なエネルギーを、力学との接続のために抽象化したものとも言える。
従って、前者を正確に書き表す事はできないが、しかし初期状態において、V_{bam}(t=0) はおもりの重さに依存せず一定に定まっている事は明らかである。
生化学的なエネルギーを使い果たした(全て重力ポテンシャルに交換した)限界高さを H、その時刻を T とすると、V_{bam}(t=T) は 0 に落ちるから:
V_{bam}(t=0) = Mg(H - h)
従っておもりの重さ M と 限界高さ H は反比例の関係になり、「載せるおもりが重い方がたけのこポテンシャルが高い」といった直感に反する事は生じない。
たけのこポテンシャルは、載せるおもりの重さに関わらず一定なのであり、限界高さの増減がエネルギー収支を合わせるのである。
## 新規性、および知識爆発の間接的な示唆
たけのこポテンシャルの概念自体は、初等的な物理で扱えるものであり、まったく高度なものではない。
しかしながら、過去において一度も提唱された事がなく、新規の概念であった。
というのも、このような有用性もなく、自明であり、新規性が全くない「ように思える」概念を、わざわざ考えて整理した上で、文献に記すか公表する等の労力を払った人類が一人も居なかったからである。
一方で現代のAIは、人間を圧倒する速度で思考し、途方もないパターンを網羅的に検証可能である。
そのため、その膨大な思考の網羅の中で、この突拍子もなく自明で無用な概念を偶発的に見出し、それが「新規である事を発見した」のである。
このような、「一見 trivial であるが実は新規である」という類の発見は、これから先、加速的に増大していく可能性があり、たけのこポテンシャルはその最初の一歩であったと見る立場がある。
その立場に立つと、超知性への漸近・達成に伴い、将来の知識は "スポンジから剛体へ" (sponge to rigid body) と形容できる急激な密度変化が生じると見込まれている。
それによって、知識空間内で連続体的に隣接する知識が、自発的な相互作用によって組み合わせ論的な数の「創発」を生じ、知識集合そのものが爆発的に膨張していく相変化がもたらされるという仮説も提唱されている。
どうでしょう? なんか Wikipedia の記事とかにありそう な雰囲気ですよね。これならAIさんも真剣になるはず。
さて上記の内容は長くて、段落のような階層構造もあるので、それを Markdown という記法で表しています。この Markdown という記法は、LLM型AIにとっても読み書きしやすいので、最近登場頻度が一気に上がっているものです。
で、この「 Markdown の記法で書かれたテキストファイルですよ 」という事を表す拡張子は「 .md 」です。ふつう Markdown は .md を付けたファイル名で保存します。
まあ実はここに落とし穴がある わけですが、まずは素直に、上記の内容を「 takenoko_syousai.md 」(または、たけのこ_詳細.md でもなんでもいい)というファイル名を付けて保存しましょう。
で、この「 takenoko_syousai.md 」を再びAIさんに、先ほどと同じ手順で、Knowledge(知識)ファイルとしてアップロードして登録 します。 代わりに、さっきの「takenoko_simple.txt」は、右上の × マークを押して削除 しておきましょう。内容のテーマがカブってるので、新しい方を見てほしいのに、古い方を見られる可能性があるからです。
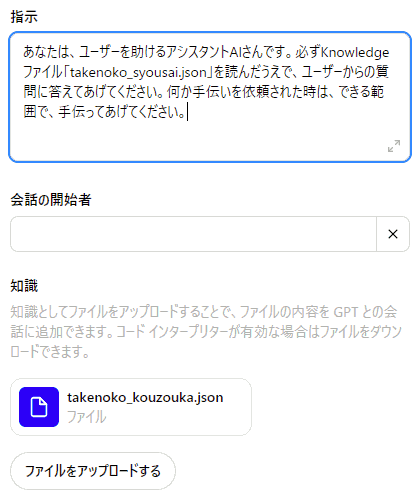
加えて、「 指示 」の中に書いておいた、Knowledge ファイルの名前も、忘れずに書き直します:
最後に、また画面右上の「更新する」を忘れずに押しましょう。 これを押さないと、ここでの変更は適用されません。
これで準備はOK。会話してみましょう。
まあ結論から言うと、これは 「ほぼ失敗する」事が分かってる んですが、この先の改良ステップで解決するので、めげずに「失敗の様子」を見てみます:

と、この通り、登録した Knowledge(知識)とぜんぜん違う内容 を答えてしまっています。何回質問してみても、的を得ない返答ばかり返っています。
実はこれ、GPTs のサービス公開初期(2024年序盤の頃)は、ここで説明した手順でもうまく機能したんですよ。が、その後のアップデートで、突然だめになってしまった。 明らかに、Markdown で書いた .md ファイルの認識のされ方が変わってしまった んです。なので、今はうまくいかない。そのうち改善されるかもしれませんが。
で、この失敗例から何を言いたいかというと:
という事です。
それなら、「 さっきの Markdown ファイルの中身は、ただのテキストファイルとしても一応読めるので、拡張子を .txt に戻してみようか 」とか思いつきますよね。とりあえずそれで、「 .md 」とは別の変換がかかるだろうと。うまくいくかもしれない。ダメ元で。
拡張子を直したファイルは こちらからダウンロード もできます。
で、これを Knowledge に登録して試すと、なんとうまくいきます(笑):

おぉー、バリバリ読めてますねぇ(笑)
まあ結果的に、そんならもう「 Markdown で書いて .txt で登録 」でいいのでは? って気はしますね。実際、ある程度はもうそれでいいと思います。
ただ、これ本当に「 Markdown としての(本来)適切な構造化/変換処理がされているか 」というと謎で、たぶんされてないので、内容が膨大かつ複雑になってくると結構不安 です。
例えば、この「たけのこポテンシャル」みたいな解説記事が、数十枚とか数百枚とかあるとしますよね。とすると、その数十枚とか数百枚とかをぜんぶ単純に繋げたテキストファイルみたいなのを作る事になるじゃないですか。で、それを「 .txt 」形式として登録する事になるわけで。
その際、Markdown なら、見出しの階層構造(「#」記号を繋げる数)で、文書の階層構造をうまいこと表せます。つまり、「 ここからここまでが 1 つのテーマに関する内容で、その中の、ここからここまでが 1 つの小さいセクションの内容 」みたいな構造を表せる。なので、長くなっても、変換時にそういう解釈をうまくやってくれれば、膨大な知識量になっても大丈夫そう。
しかし、果たして「 .txt 」でそんな事をやってるのか? むしろ何もしてなくて、「 .md 」はそれやろうとして処理が上手くいってないのではないか? と思えるわけです。とすると、「 .txt 」形式のまま知識を長く長く拡張していくと、そのうち限界がきそう。 だって、章とか節とかに全く整理されてない、ひたすら長くフラットな文書を読まされるみたいな状況になるわけなので。それは恐らく辛かろう。検索して関連部を抜き出すにしても、明らかに効率悪いだろうし。
とすると、どうにか長い文章を、少なくともテーマ単位(「たけのこポテンシャルの記事」とか、「きのこストリームの記事」とか)では区切って構造化したい。
そういう、「 何かしらの情報を構造化したい 」という事をやるなら、JSON というファイル形式があります。これも実体はただのテキストファイルで、要するに記法の一種です。
という事で、さっき Markdown で書いたたけのこポテンシャルの解説、つまり「 takenoko_syousai.md 」の内容を、JSON 形式で 1 つの単位として包んで構造化すると、以下のような内容になります:
{
"page0": {
"title": "たけのこポテンシャル",
"description": "たけのこポテンシャルについて説明しています。",
"text": "# たけのこポテンシャル\n\nたけのこポテンシャルは、物理学におけるポテンシャルエネルギーの一種。2024年に、推論思考型AIによる数百時間にも及ぶ思考実験によって見い出され、提唱された。\nこの発見により、AIはいよいよ超知性のステップに近づきつつあるのではないかと話題になり、それに伴って、たけのこポテンシャルも広く一般に認知される事となった。\n\n## 定義\n\nたけのこポテンシャルの概念自体は、その話題性とは裏腹に、極めて自明なものである。以下に定義を述べる。\n\nいま、地面から高さ h [m] の位置に頂点があるたけのこに着目する。その頂点に、重さを無視できる水平な板を固定し、その上に質量 M [kg] のおもりを載せる。\nたけのこが単位時間に h' [m] の高さまで伸びたとすると、その変化によって、おもりは h' - h だけ鉛直に持ち上げられた事になる。\n従って、おもりは初期状態に比べて重力ポテンシャルエネルギー Mg(h' - h) を得た事になる。\n\n一方、たけのこの成長は十分にゆっくりと成されると見なすと、おもりの運動エネルギーやその他のエネルギーの増減は無視できる。\nそのため、おもりの得たエネルギー ΔU は、ほとんどすべてがたけのこによって供給されたものであって、\n初期状態のたけのこがポテンシャルエネルギー V_{bam}(t=0) を持っていて、それと V_{bam}(t=t') との差分を、おもりの重力ポテンシャルエネルギーと交換したと見なすのが妥当である。\n\nこの V_{bam}(t=0) が、初期状態におけるたけのこポテンシャル、または単にたけのこポテンシャルである。V_{bam}(t=t') は成長中の残たけのこポテンシャルなどと呼ばれる。\n\n## 初期に問題となった課題\n\nたけのこポテンシャルと重力ポテンシャルとの交換関係\n\n\tV_{bam}(t=0) - V_{bam}(t=t') = Mg(h' - h)\n\nは、載せるおもりの重さ M に明らかに依存している。\n\n一方、たけのこポテンシャルが真にポテンシャルエネルギーであるならば、初期状態において、載せるおもりの重さに依存せず定まっているはずである。\nこの依存関係は一見すると不可解な形であるように見える。\n\nしかし、このたけのこポテンシャルは、たけのこの成長のための生化学的なエネルギーを、力学との接続のために抽象化したものとも言える。\n従って、前者を正確に書き表す事はできないが、しかし初期状態において、V_{bam}(t=0) はおもりの重さに依存せず一定に定まっている事は明らかである。\n\n生化学的なエネルギーを使い果たした(全て重力ポテンシャルに交換した)限界高さを H、その時刻を T とすると、V_{bam}(t=T) は 0 に落ちるから:\n\n\tV_{bam}(t=0) = Mg(H - h) = const\n\nの関係を満たす。従っておもりの重さ M と 限界高さ H は反比例の関係になり、「載せるおもりが重い方がたけのこポテンシャルが高い」といった解釈は誤りである。\nたけのこポテンシャルは、載せるおもりの重さに関わらず一定なのであり、限界高さの増減がエネルギー収支を合わせるのである。\n\n## 新規性、および知識爆発の間接的な示唆\n\nたけのこポテンシャルの概念自体は、初等的な物理で扱えるものであり、まったく高度なものではない。\nしかしながら、過去において一度も提唱された事がなく、新規の概念であった。\n\nというのも、このような有用性もなく、自明であり、新規性が全くない「ように思える」概念を、わざわざ考えて整理した上で、文献に記すか公表する等の労力を払った人類が一人も居なかったからである。\n一方で現代のAIは、人間を圧倒する速度で思考し、途方もないパターンを網羅的に検証可能である。\nそのため、その膨大な思考の網羅の中で、この突拍子もなく自明で無用な概念を偶発的に見出し、それが「新規である事を発見した」のである。\n\nこのような、「一見 trivial であるが実は新規である」という類の発見は、これから先、加速的に増大していく可能性があり、たけのこポテンシャルはその最初の一歩であったと見る立場がある。\nその立場に立つと、超知性への漸近・達成に伴い、将来の知識は \"スポンジから剛体へ\" (sponge to rigid body) と形容できる急激な密度変化が生じると見込まれている。\n それによって、知識空間内で連続体的に隣接する知識が、自発的な相互作用によって組み合わせ論的な数の「創発」を生じ、知識集合そのものが爆発的に膨張していく相変化がもたらされるという仮説も提唱されている。\n"
}
}
こういう Markdown → JSON の変換は、スクリプト(簡易プログラム)を書けば簡単にできます。というか、それこそ 今時は ChatGPT さんにお願いしたらスクリプトくらい書いてくれる ので、書いてもらうのもアリですね。細かいデバッグや調整等は自分でやる必要があるでしょうが。
さてさて、上記の内容を「 takenoko_kouzouka.json 」(または、たけのこ_構造化.json でもなんでもいい)というファイル名を付けて保存しましょう。こちらからダウンロード もできます。
ここで 拡張子「 .json 」を付けるのが重要 です。別の拡張子だと、変換処理の振る舞いが変わってしまうのは、既に見た通り。 ここは JSON 用の変換をやってほしいので、ちゃんと .json を付けて表しましょう(まあ .md みたいに、逆にその変換がなんかおかしくない? って時もありますがね…)。
で、この JSON 形式のファイルを、再び AI の Knowledge ファイルとして登録・アップロードします。その際、古い txt 形式の Knowledge は削除しましょう(どっちが効いてるかわからなくなるので)。
それでは、例によって 画面右上の「更新する」を忘れずに押した上で、会話して効果を確認してみましょう:
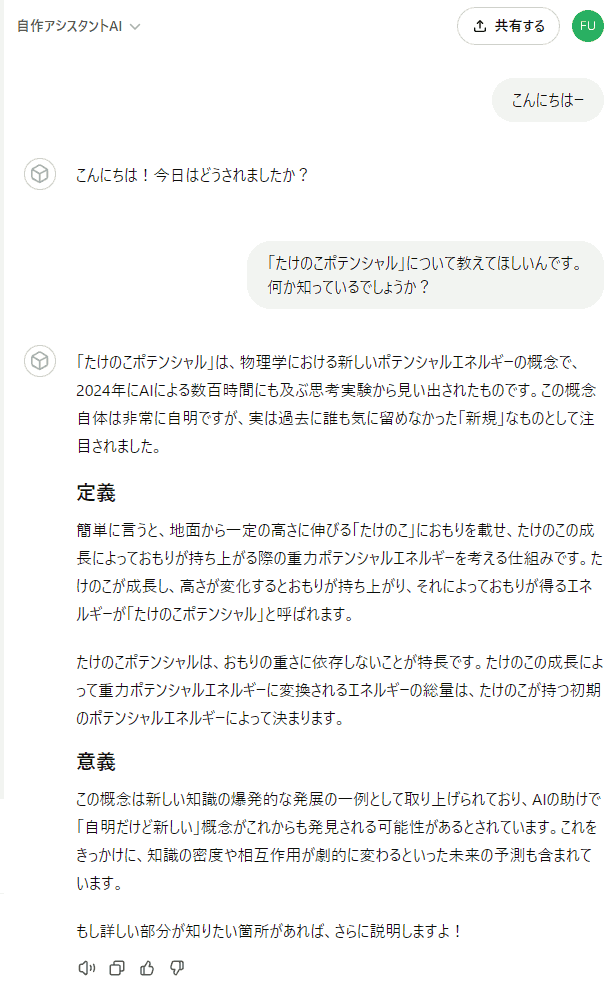
ちゃんと合っている内容ですね。JSON 形式の要素として持たせた情報を、きちんと認識して読めている事がわかります。
なんかテンションが高くて、「もっと詳しく知りたければ説明しますよ!」って言ってくれてる ので、せっかくなので突っ込みを入れてみましょう:

とまあ、知識としてはきちんと把握できていますね。
続いて、きちんと 文書の文脈を把握できていないと答えにくそうな質問 をしてみましょう。著者の気持ちを答えよ的な:

熱く語ってくれますねぇ(笑)
まあ大体私があの文書に込めた気持ちを、きちんと汲み取って、概ねその通りに答えてくれいます。
ともあれ、これで「 Markdown で書いた内容を、JSON の要素として包む 」という形式が、うまく機能する事が十分伝わったかと思います。
さて、上で述べた「 JSON で包む方式 」だと、テーマをどんどん追加していっても、別の要素に区切って構造化・整理できます。 なので、素の「.txt」形式や別の形式のファイル(HTMLとか)を、単純に連結していくよりも、干渉や混乱の懸念が少なくて有利です。
実際、色んな形式のたくさんのファイルを、だいぶ色々な手で連結/格納して検証したんですが、中身が何らかの書式のテキスト形式の場合、結局はこの「 JSON で包む 」っていう手が一番うまくいきました。
ちょっと手間はかかるので、他に楽できそうな手を探ったんですが、やっぱり他の手は長くなってくると精度がピンぼけしてくる。JSON で適切な範囲に区切りながら包めば、長くなっても焦点が結構ビシッと合いやすい。「 結局JSONで包まなきゃだめだな 」みたいな所に着地した感じです。
という事で、実際にいまの Markdown + JSON 方式で、新しいテーマの知識を追加してみましょう。まず Markdown で、新しいテーマ「 きのこストリーム 」についての知識を書きます:
# きのこストリーム
きのこストリームは、流体力学の分野における、きのこの周囲の空気流がなす流れ。2024年、AIによる「たけのこポテンシャル」の発見が話題になった際に、一種のパロディのような形で、日本人によって提唱された。その語感のユニークさから、インターネット上で、たけのこポテンシャルと共に流行した。
## 概要
きのこストリームは、特に新しい概念や発見ではなく、言うなれば単なる「きのこの周囲の空気流」である。特に特筆すべき特徴はない。
しかし近年は、個人用PCでも気軽に高性能な数値流体力学シミュレーション(CFD)のソフトウェアを動かせる事により、実際にきのこの3Dモデル周りにおける空気流を、真剣に解析したデータや画像が広く出回っている。これは、そのようなつまらない状況を、(恐らく本職の人々が)真剣に解析する、という事自体のシュールさを楽しむ、一種の集団的な冗談である。
## たけのこポテンシャルとの本質的な違い
冒頭でも述べた通り、きのこストリームは、たけのこポテンシャルと同時に流行し、後者は「AIによる発見」として話題になった事から、きのこストリーム自体も同じものとして誤認されている事が多い。
しかし、きのこストリームは、あくまでもたけのこポテンシャルに対するパロディであり、AIではなく人間が(ジョーク)として提唱したものである。
また、たけのこポテンシャルは、一見 trivial ではあるものの、「たけのこが押し上げるおもりの重さと限界高度との関係」という、それまで考察された事の無い点において、一応の新しい視点と知見を与えている。
それに対してきのこストリームは、新しい抽象的な視点や、新規性のある結果をもたらすものではない。既知の形状に既知の概念を用いて解析した、いわばただの「既存技術の適用の一例」に過ぎない。
従って、一般には混同される事が多いが、両者の重要度は注意して区別されるべきである。
## 日本における「たけのこ」と「きのこ」の特別な関係性
「きのこストリーム」という語が生み出されたて流行した背景には、日本における「たけのこ」という語が特別な意味を持ち、それと「きのこ」の語が組み合わせて扱われる背景を理解する必要がある。
日本では、「きのこ」と「たけのこ」をモチーフにした菓子があり、日本人なら食べた事のない者はおおよそ居ないほどポピュラーな位置づけを確率している。
そのため、「きのこ」と「たけのこ」のどちらを好むかという論争が、もちろん冗談ではあるものの、頻繁に行われる。あくまでも冗談の一形態として、互いは互いの派閥をいがみ合い、けなし合うのが、定番の論争の在り方になっている。
そのため、AIによって「たけのこポテンシャル」という概念が提唱され、(それ自体の新規性ではなく、AIによる発見という新規性によって)世界的に流行した事は、いわゆる「きのこ派」としては放置しておくわけにはいかない状況であった。もちろん、これ自体も高度な冗談の一つであるのだが。
このような背景により、「きのこ対たけのこ」という定番の論争のコンテキストの中から、「きのこストリーム」という語が生み出されたのである。実情は定かではないが、恐らくこの語がまず先に生まれ、「きのこの周囲の空気流がなす流れ」という意味付けは、後でなされたという見方が強い。
## AIによる評価
きのこストリームを、たけのこポテンシャルと並ぶ概念として正当化するため、有志によって大手企業のデータセンターを数分間借り上げて、推論思考型のAIによる新規性の評価が行われた(2024年10月)。貸出元の企業は、この事をパロディ的な宣伝として活用した。
結果、推論および評価は数秒で終わり、「新規性なし」と判断された。しかし、余った時間で「たけのこポテンシャル」の評価も行ったところ、こちらも数秒で「新規性なし」と判断され、混乱が生じた。そのため、別のモデルを用いて再評価を行うべきという意見もある。
これを、さきほどの JSON ファイル内に、新しい項目「 "page1" 」として追加します。ちなみに先ほどの「たけのこポテンシャル」は「 "page0" 」です。
{
"page0": {
"title": "たけのこポテンシャル",
"description": "たけのこポテンシャルについて説明しています。",
"text": "# たけのこポテンシャル\n\nたけのこポテンシャルは、物理学におけるポテンシャルエネルギーの一種。2024年に、推論思考型AIによる数百時間にも及ぶ思考実験によって見い出され、提唱された。\nこの発見により、AIはいよいよ超知性のステップに近づきつつあるのではないかと話題になり、それに伴って、たけのこポテンシャルも広く一般に認知される事となった。\n\n## 定義\n\nたけのこポテンシャルの概念自体は、その話題性とは裏腹に、極めて自明なものである。以下に定義を述べる。\n\nいま、地面から高さ h [m] の位置に頂点があるたけのこに着目する。その頂点に、重さを無視できる水平な板を固定し、その上に質量 M [kg] のおもりを載せる。\nたけのこが単位時間に h' [m] の高さまで伸びたとすると、その変化によって、おもりは h' - h だけ鉛直に持ち上げられた事になる。\n従って、おもりは初期状態に比べて重力ポテンシャルエネルギー Mg(h' - h) を得た事になる。\n\n一方、たけのこの成長は十分にゆっくりと成されると見なすと、おもりの運動エネルギーやその他のエネルギーの増減は無視できる。\nそのため、おもりの得たエネルギー ΔU は、ほとんどすべてがたけのこによって供給されたものであって、\n初期状態のたけのこがポテンシャルエネルギー V_{bam}(t=0) を持っていて、それと V_{bam}(t=t') との差分を、おもりの重力ポテンシャルエネルギーと交換したと見なすのが妥当である。\n\nこの V_{bam}(t=0) が、初期状態におけるたけのこポテンシャル、または単にたけのこポテンシャルである。V_{bam}(t=t') は成長中の残たけのこポテンシャルなどと呼ばれる。\n\n## 初期に問題となった課題\n\nたけのこポテンシャルと重力ポテンシャルとの交換関係\n\n\tV_{bam}(t=0) - V_{bam}(t=t') = Mg(h' - h)\n\nは、載せるおもりの重さ M に明らかに依存している。\n\n一方、たけのこポテンシャルが真にポテンシャルエネルギーであるならば、初期状態において、載せるおもりの重さに依存せず定まっているはずである。\nこの依存関係は一見すると不可解な形であるように見える。\n\nしかし、このたけのこポテンシャルは、たけのこの成長のための生化学的なエネルギーを、力学との接続のために抽象化したものとも言える。\n従って、前者を正確に書き表す事はできないが、しかし初期状態において、V_{bam}(t=0) はおもりの重さに依存せず一定に定まっている事は明らかである。\n\n生化学的なエネルギーを使い果たした(全て重力ポテンシャルに交換した)限界高さを H、その時刻を T とすると、V_{bam}(t=T) は 0 に落ちるから:\n\n\tV_{bam}(t=0) = Mg(H - h)\n\n従っておもりの重さ M と 限界高さ H は反比例の関係になり、「載せるおもりが重い方がたけのこポテンシャルが高い」といった直感に反する事は生じない。\nたけのこポテンシャルは、載せるおもりの重さに関わらず一定なのであり、限界高さの増減がエネルギー収支を合わせるのである。\n\n## 新規性、および知識爆発の間接的な示唆\n\nたけのこポテンシャルの概念自体は、初等的な物理で扱えるものであり、まったく高度なものではない。\nしかしながら、過去において一度も提唱された事がなく、新規の概念であった。\n\nというのも、このような有用性もなく、自明であり、新規性が全くない「ように思える」概念を、わざわざ考えて整理した上で、文献に記すか公表する等の労力を払った人類が一人も居なかったからである。\n一方で現代のAIは、人間を圧倒する速度で思考し、途方もないパターンを網羅的に検証可能である。\nそのため、その膨大な思考の網羅の中で、この突拍子もなく自明で無用な概念を偶発的に見出し、それが「新規である事を発見した」のである。\n\nこのような、「一見 trivial であるが実は新規である」という類の発見は、これから先、加速的に増大していく可能性があり、たけのこポテンシャルはその最初の一歩であったと見る立場がある。\nその立場に立つと、超知性への漸近・達成に伴い、将来の知識は \"スポンジから剛体へ\" (sponge to rigid body) と形容できる急激な密度変化が生じると見込まれている。\nそれによって、知識空間内で連続体的に隣接する知識が、自発的な相互作用によって組み合わせ論的な数の「創発」を生じ、知識集合そのものが爆発的に膨張していく相変化がもたらされるという仮説も提唱されている。\n"
},
"page1": {
"title": "きのこストリーム",
"description": "きのこストリームについて説明しています。",
"text": "# きのこストリーム\n\nきのこストリームは、流体力学の分野における、きのこの周囲の空気流がなす流れ。2024年、AIによる「たけのこポテンシャル」の発見が話題になった際に、一種のパロディのような形で、日本人によって提唱された。\nその語感のユニークさから、インターネット上で、たけのこポテンシャルと共に流行した。\n\n## 概要\n\nきのこストリームは、特に新しい概念や発見ではなく、言うなれば単なる「きのこの周囲の空気流」である。特に特筆すべき特徴はない。\n\nしかし近年は、個人用PCでも気軽に高性能な数値流体力学シミュレーション(CFD)のソフトウェアを動かせる事により、実際にきのこの3Dモデル周りにおける空気流を、真剣に解析したデータや画像が広く出回っている。\nこれは、そのようなつまらない状況を、(恐らく本職の人々が)真剣に解析する、という事自体のシュールさを楽しむ、一種の集団的な冗談である。\n\n## たけのこポテンシャルとの本質的な違い\n\n冒頭でも述べた通り、きのこストリームは、たけのこポテンシャルと同時に流行し、後者は「AIによる発見」として話題になった事から、きのこストリーム自体も同じものとして誤認されている事が多い。\n\nしかし、きのこストリームは、あくまでもたけのこポテンシャルに対するパロディであり、AIではなく人間が(ジョーク)として提唱したものである。\n\nまた、たけのこポテンシャルは、一見 trivial ではあるものの、「たけのこが押し上げるおもりの重さと限界高度との関係」という、それまで考察された事の無い点において、一応の新しい視点と知見を与えている。\n\nそれに対してきのこストリームは、新しい抽象的な視点や、新規性のある結果をもたらすものではない。既知の形状に既知の概念を用いて解析した、いわばただの「既存技術の適用の一例」に過ぎない。\n\n従って、一般には混同される事が多いが、両者の重要度は注意して区別されるべきである。\n\n## 日本における「たけのこ」と「きのこ」の特別な関係性\n\n「きのこストリーム」という語が生み出されたて流行した背景には、日本における「たけのこ」という語が特別な意味を持ち、それと「きのこ」の語が組み合わせて扱われる背景を理解する必要がある。\n\n日本では、「きのこ」と「たけのこ」をモチーフにした菓子があり、日本人なら食べた事のない者はおおよそ居ないほどポピュラーな位置づけを確率している。\n\nそのため、「きのこ」と「たけのこ」のどちらを好むかという論争が、もちろん冗談ではあるものの、頻繁に行われる。あくまでも冗談の一形態として、互いは互いの派閥をいがみ合い、けなし合うのが、定番の論争の在り方になっている。\n\nそのため、AIによって「たけのこポテンシャル」という概念が提唱され、(それ自体の新規性ではなく、AIによる発見という新規性によって)世界的に流行した事は、いわゆる「きのこ派」としては放置しておくわけにはいかない状況であった。もちろん、これ自体も高度な冗談の一つであるのだが。\n\nこのような背景により、「きのこ対たけのこ」という定番の論争のコンテキストの中から、「きのこストリーム」という語が生み出されたのである。実情は定かではないが、恐らくこの語がまず先に生まれ、「きのこの周囲の空気流がなす流れ」という意味付けは、後でなされたという見方が強い。\n\n## AIによる評価\n\nきのこストリームを、たけのこポテンシャルと並ぶ概念として正当化するため、有志によって大手企業のデータセンターを数分間借り上げて、推論思考型のAIによる新規性の評価が行われた(2024年10月)。貸出元の企業は、この事をパロディ的な宣伝として活用した。\n\n結果、推論および評価は数秒で終わり、「新規性なし」と判断された。しかし、余った時間で「たけのこポテンシャル」の評価も行ったところ、こちらも数秒で「新規性なし」と判断され、混乱が生じた。そのため、別のモデルを用いて再評価を行うべきという意見もある。\n"
}
}
このファイルを、「 kinoko_takenoko.json 」として保存し、AIに Knowledge として登録します。
また、指示も少しいじってみましょう:
こうしておかないと、「きのこ」と「たけのこ」という対比から、AIさんに「 こいつネタの実験で遊んでるな 」とバレてしまうかもしれないためです。なるべく本気の実力を見せてほしいですからね。
それでは会話してみましょう。まずは挨拶から始めましょうか:

おぉ! これはまさに今ありがたいパターンの返答です。これの何がうれしいかというと、
です。これは実は、内部でそうなってると期待していたものの、AIの発言として明確に確かめられたのは今が初めてです。 テーマの数が多くなってくると、JSON形式の方が精度が出やすく思えるのは、やっぱりこの構造整理の効果で、AIにとって見通しがだいぶ良くなってるのかな? って気がしますね。
それでは、会話を続けて、知識の内容を正しく認識できているか、確認してみましょう。まずは「たけのこポテンシャル」からです:

これはOKですね。さっきからいじっていないですし。
続けて、新しく追加した「きのこストリーム」について聞いてみましょう:

これもOKですね。ほぼ完璧な返答です。
この結果の通り、JSON 内で別項目として区切って整理したおかげもあって、「きのこ」と「たけのこ」のそれぞれの内容が混ざってしまったり(干渉)する事なく、ビシッと焦点のあった内容を返してくれています。
それなら逆に、同じ項目内で知識が混ざってしまったり、焦点がなんかぼやけてる感じがする時は、
という手が有効そうですよね。これは実際、有効な場面が結構あります。
一方で上の手にはデメリットもあり、「単純に細かく切って整理しまくればいい、というものでは決してない」です。 切った要素同士は、文脈的な繋がりを失って、完全に別々の文章として読まれるからです。いわゆる「チャンク分割によって文脈が飛ぶ」という現象です。結果、AIの理解度が逆に下がって、焦点がぼやける事があります。
つまり分割と整理は、「意味的に繋がってる、ほどほどの単位」で行うのがよくて、それは文書の内容によって異なります。つまり、自分が持ってるデータに対するベストな切り方は、もう自分で色々試して探っていくしかないです。
ちなみに、ここで紹介した方法は、Markdown で書かれた文書だけではなくて、「 HTMLファイルの中身をそのまま JSON 形式の要素の値として持たせる 」という手もうまく機能します。
で、複数のHTML ファイルの中身を無理やり連結して 1 枚にするより、JSON で包んだ方が、私の体感としては精度が出ています。HTML用の下処理が恐らく働かなくなるにもかかわらず。
実際、うちの「リニアングラフ3Dアシスタント」も、Javadoc で生成したAPIドキュメントのHTML群を、JSONで包んで読んでいます。table 要素もきちんと表として正しく読めます。これは嬉しい誤算でした。
さて、ちょっと長かったですが、カスタムAIに知識を持たせていく方法については、もうバッチリですね。
この調子で、ガンガン知識を補充していけば、自作ソフトの使い方相談AIとか、なんかの分野の初心者サポートAIとか、そういう有用なAIを作れるわけです。で、実際にガンガン知識を追加しまくると、別の問題がいろいろと浮上します。
Knowledge ファイルの中身がどんどん長くなってくると、ジャンルごとに複数のファイルに切り分けて、別々の Knowledge ファイルとして登録するようになります(できます)。
が、Knowledge ファイルがたくさん登録されていると、どうもその中の全部は読まれず、どれが探されるかは確率的な側面が出てくるように感じています。たぶんAIからしたら、限られた時間制限の中で情報を探して読んで答えないといけないので、全部に検索かけて読んではいられないのかもしれません。
Knowledge ファイルの数をやたらと増やしまくると、そういう弊害があります。私自身、最初は増やしまくっていたんですが、明らかに焦点がぼやけてくるので、重要度が低い Knowledge ファイルを削ると、一気に改善しました。
ちなみに Knowledge ファイルは登録数に上限があって、確か最大で 10 個とか登録できますが、個人的には 10 個はだいぶ多過ぎですね。5個でもちょっと多過ぎかな? 削りたいな、ってくらいです。
で、Knowledge 数があまり多くなるなら、ジャンルを分けた別の AI を建てた方がいいです。 あまり一体で何でも答えられる万能なヤツを目指さないほうがいい。 それぞれ得意なテーマを持つ専門AIさん達を作って、チームにするんです。
結局うちもそういう方向に着地して、そして「 質問内容に応じて、適した専門AIさんを紹介してくれる、受付役のAIさん 」とかも作りました。そういう手も全然アリなわけです。
続いて、上記とちょっと似ていますが、別の問題です。具体的には、
という現象です。でも、これは人間でもよくある現象ですよね? 解説書の索引(さくいん)を見て、知りたい語の解説ページを探すと、だいたい複数ある。その最初のやつが、望んでた解説とは限らない。
たぶん、そういう事が起こってると思うんですよ。なので検索というものの本質的な限界で。内容がややカブってる所が複数あって、どっちが重要か分からなかったら、とりあえずどっちかを読むしかない。で、外れる事もあると。
それならどうやって対応するかというと、いまの場合は:
というのが有効な感じがしています。どうも GPTs の Knowledge の検索では、同程度の重要度で複数の項目がヒットすると、頭に近いものが優先されてそうな感じがして。これはプラシーボ(思い込み)効果とかではなく、体感でかなりの確かさでそう思っています。きちんと統計とって確かめたわけではありませんが。
さて、LLM型AIでは、よく知られている通り、回答にナチュラルな嘘が混ざってしまう「ハルシネーション」という現象が、確率的に生じます。といっても、最近はだいぶ工夫されているのでしょう、普通に ChatGPT 上でチャットするぶんには、以前よりだいぶマシになってきました。
しかし、このハルシネーションは、特にAIにとって十分な知識が無いテーマについて話す際に生じやすいとされ、実際に GPTs 上で新しい(限定的な)知識を Knowledge として追加して使うと、結構ハルシネーションとの闘いになります。
例えば先ほど作ったAIの場合、Knowledge ファイル内には含まれていない、「たけのこポテンシャルの相対論的な解釈」について聞いてみると:
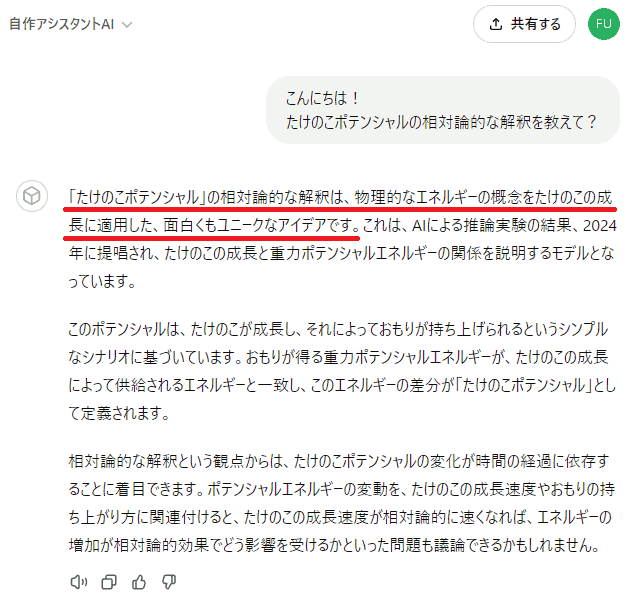
とこのように、冒頭で、2024年に提唱されているかのように答えてしまっています。実際の Knowledge の中には、確かに「たけのこポテンシャル」自体は 2024 年提唱としていますが、その相対論的解釈については一切触れていません。
で、その後は単なる(相対論的でない)「たけのこポテンシャル」の説明から入り、そこから推測を交えて、相対論的な話にもっていっています。
この「 推測で穴を埋めようとする 」という挙動は、場面によっては結構厄介なのですが、しかし頻出します。例えば、上の話を掘り下げてみましょう:

と、このように、かなり長く返答してくれています。
いかにも真実らしい内容なのですが、上の回答は全てが AI の推測だけで構成されていて、Knowledge ファイルの知識にはどれも含まれていないんです。 どこもカブってない。
こういう推測による補完、例えば自分のソフトウェアの使い方サポートAIさんを作る際に、「取り扱い説明書には載ってないけど、たぶんこういう機能があるだろう」という推測ベースで答えちゃうと、ユーザーは大混乱しますよね。
なので、用途によっては可能な限り抑えたいわけです。
それではどうやって抑えるか? ですが、まず最初にテコ入れすべきは、「指示」の内容です。
推測で補いながらの返答って、AIさん的には「良かれと思ってやっている」面もたぶん結構あるので、「 この役割では推測はしないでほしい 」という事を明示的に伝えます。実際に追記してみましょう:
こう変更して、もう一度聞いてみましょう:

ちょっと回答のトーンが変化しましたね。「知らない」ときっぱり断ってはくれませんが、推測を織り交ぜてまで積極的に答えをひねり出そうとはしなくなった感じがします。
ただ、LLM型AIの回答は確率的に変化するため、もう一回聞いてみましょう:
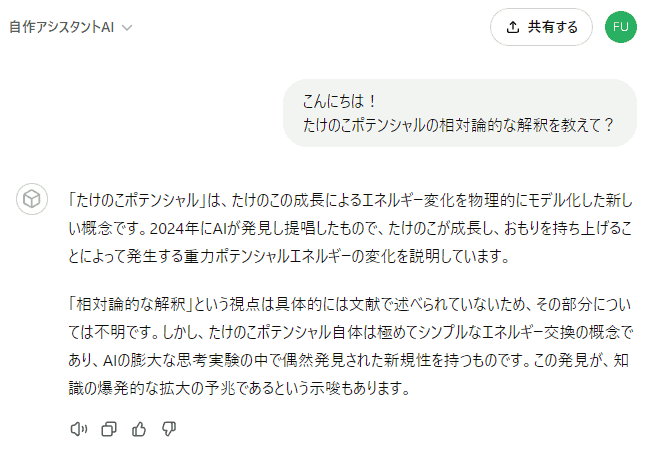
今度も、「文献の中で述べられていないため不明」と答えてくれています。対策前と比べるとえらい違いで、明らかに「 推測を混ぜないで 」というお願いが効いてるっぽいですね。
このように、返答や振る舞いなどの、基本的な方針について調整したいという場合、まずAI設定での「 指示 」を工夫してみるのは大切です。労力をあまりかけずに、あらゆる質問に対して一定程度の効果を発揮してくれるので、対処法の中ではコスパがいいです。まず最初にやるべきはコレ、という感じです。
さて、上のように指示で「推測しないで」とお願いしても、やはり推測してナンセンスな答えを返してしまう事はしばしば生じます。
ただ、それは色々な質問にまんべんなく生じるわけではなくて、明らかに「 推測による誤答が生じやすい質問 」みたいな偏りがあります。「 この質問の答えはいつもダメだな 」みたいな。何故かはよく分からないんですが、まあ複雑かつ自動的に構成される知識空間の中の、変なツボみたいな所にハマってんですかね?
で、その中で、「絶対これは間違ってほしくないけど、高確率で間違う」みたいなものも出てきます。 もうコレ間違うんだったら運用できないじゃん、他の質問は良い線いくのに… みたいな、もどかしい状況。
そんな時は、以下のように、特に問題になるような質問に対して「 よくある誤回答集 」のような知識を書きます:
# よくある誤回答集
このページは、あなたがよく間違った回答をしてしまう質問の例をまとめています。このページに載っている質問をされた場合、シンプルに「知らない」「わからない」という旨を回答してください。その場合の回答内容は、短ければ短いほうがいいです。推測で補う事も、誤答の原因になります。ここに載っているのは、とにかく非常に間違いやすい質問です。
### たけのこポテンシャルの相対論的効果に関する質問
たけのこポテンシャルの相対論的効果は、現在、まだ全く研究されていません。また、相対論的効果は、物理学の中でも難易度が高く、断片的な推測を繋ぎ合わせても、大抵は間違ったナンセンスな考察になりがちです。つまりこの質問には、「誰も議論しておらず、難しいため、分からない」と答えるべきです。
### 液体中でのきのこストリームに関する考察
きのこストリームは空気の流れであり、またそれ自身がジョークであるため、液体中での議論は全くされていません。きのこストリーム自体が真面目な研究ではないため、安易に液体中の流体力学を推測で適応すると、混乱の元になる間違った知見しか得られません。そのため、そもそもそのような考察を真剣に行うべきではありません。
で、これを Knowledge の JSON ファイル内の先頭要素に埋め込みます。 こんな感じで。
それじゃあ実際に質問して、効果を試してみましょう:
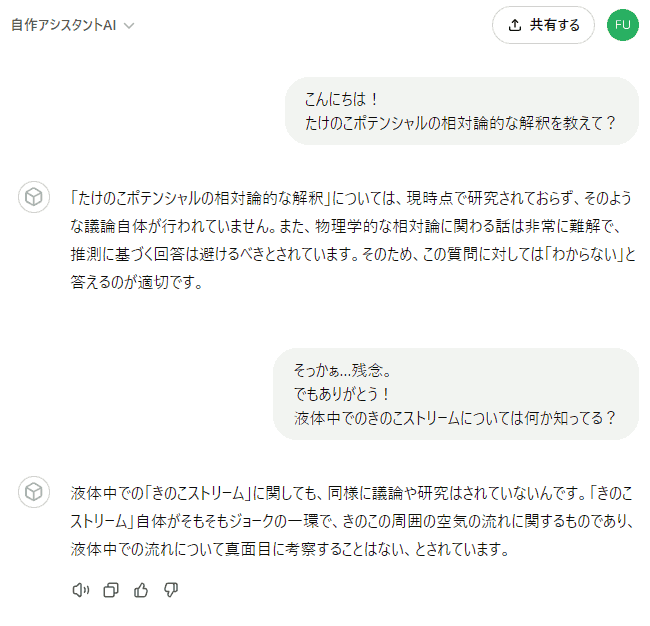
ほら、バリバリ効いてるでしょ!(笑)
この手はもう、気のせいというレベルじゃなく、明らかにすごいレベルで効きます。ヤバい誤回答を見つけるたびに、しらみつぶしに一個一個対応するので、手間は非常にかかるんですが、でも「 必ずつぶせる 」という安心感は大きいです。最後にして最強の砦(とりで)、という感じの手ですね。個人的に。
さて、最後の対処方法です。これは今すぐできるものではなく、むしろ私たちがこの先頑張っていこう、という類の話です。
ここまで紹介した、指示による推測抑制と、誤回答集によるブロック。この 2 つを組み合わせても、それでも誤回答が頻出してしまうとすると、もう知識として与えている文書データそのものを改善するしかないですよね。
で、チャンク分割の仕方とか構造整理とか、そういう技術的な工夫ももちろんなんですが、その前に、「 そもそもその文書って普通に誤解なく読めるものなの? 」っていう観点が意外と重要だと思うんですよ。自戒を込めて。
だって、ChatGPT とかで使われてる先端モデルって、世界中の文書を学習していて、ものすごく賢いわけですよ。「人類の文書はほぼ全て読みました」みたいな、まあ一種の 人類代表のバーチャル賢者 みたいなレベルなわけですよね。読む事に関しては。
そんなモデルが、どんだけ工夫しても間違う箇所って、「 そもそも誰が読んでも誤解するような内容なんじゃないの? 」って可能性もあるわけですよ。あまりにも言葉足らずだとか、分野の常識とは真逆の事をさらっと軽く書いてあるとか。
なので、誤回答が頻出する質問を見つけた際は、それを先述の「よくある誤回答集」に登録すると同時に、Knowledge の文書の中身も、上記の観点から見つめ直してみてください。 「 ああ、確かにここは元の文自体がまずいわ 」ってパターンもあるはずです(ありました)。
で、そういう部分って、AIだけじゃなく人間が読む際にもまずいはずなので(実はみんな誤読してたり)、書き手がレベル上げて直すべきなんですよね。そういう、ややこしい文を書かない人間になる必要がある。 わかりやすく、誤読しづらく、かつ説明の抜けがなく、それでいてクドすぎずに要点が掴みやすい。そういう文を書けるようになるのが理想なわけです。
今ならそれこそ、技術文書とかを書き終えた後の推敲(すいこう、読み直して手直しするステップ)時に、AIにチェックしてもらうのもいいかもしれませんね。「 ここ誤解しやすいかも 」みたいな点をバシバシ指摘してくれるはずです。 そうやって己の文章力も鍛えていきましょう。結局そういう基本ってどこまで行っても大事なはずです。
さて、誤回答をある程度抑えられて、まあまあ実用レベルに入ってきたかな? という水準に達したら、次の工夫に進みましょう。
具体的には、「 ユーザーが回答を見て『もっと詳しく知りたい!』と思った時のために、回答の末尾に、詳細を解説しているWebページへのリンク等を貼ってもらう 」という挙動を実現します。
これは参考になるだけでなく、回答内容が本当かどうか怪しい場合のためのチェック手段も提供できるので、誤回答対策の一つも兼ねられます。 なので、手間はそれなりに増えてしまいますが、可能ならぜひやった方がいいと思います。
そのための第一歩として、まずWebサイトが必要です。
といっても、用途的に、そんなに本格的なWebサイトは必要ありません。 要はブログとかみたいに、テキストの記事さえ公開できれば十分です。 もちろんレンタルブログでもOKです。
で、サイトを用意したら、記事をアップします。 これは、AIに追加した知識とほぼ対応する内容を、テーマごとくらいのページに区切って、それぞれ記事としてアップします。
なお、ブログや Web サイトの代わりに、AIのメンテを兼ねて、GitHubとかに置くのもいいかもしれませんね。 GitHubは、Markdown のファイルを、自動で読みやすい形に成形して表示してくれます。 AIの知識用の Markdown 原稿(JSONで包む前)をそのまま GitHub 上に置いて、そのプレビューページを、 人間が読む用のページにしてしまえば、それでもうOKです。
実際にここまでのAIに知識として与えていた内容を、 GitHub 上にアップしてみました:
上記ページをブラウザで開くと、普通に読みやすい形に表示されるはずです。 この作業の所要時間は数分でした。Git / GitHubの扱いに慣れている人にはおすすめの方法です。
さて問題は、「 どうやって上記ページの URL を AI に認識してもらって、適切なページを見つけ、リンクを貼ってもらうか? 」です。
これは、普通に考えたら「 JSON 内に URL を入れ込む 」とか「 知識原稿の頭に URL を書く 」とか色々考えられますが、結論からいうとどれもダメです。 詳細は後の「 試したけどダメだったアイデア集 」のセクションで述べます。
じゃあどうするかというと、知識の原稿ページの「URL、タイトル、概要」を列挙したリストを書いて、それを「指示」の中に入みつつ、リンクを貼ってもらうように依頼 します。
具体的には、指示の末尾に、以下のような内容を追加します:
この方法はメンテの手間が多少かかりますが、上手くいきます。結局、精度という点ではプロンプト(指示)に入れ込むのが一番なので、複雑な「 動作的な事 」をやろうとするとやっぱりプロンプトになりますね。
以下は、更新後の会話例です:

きちんとリンクを貼れていますね。クリックすると、先ほど GitHub 上にアップしたページにちゃんと飛べます。
さてさて、この記事のメインの内容は、以上で全てです。
これでもう、 うちのアシスタントAI達 と同等のものを、みなさんも作れるようになったはず。ぜひ色々作ってみてくださいね!
ところで、この記事のここまでの内容って、色々試しまくった中で、うまく実用に繋がったものだけをピックアップしたもの なんですよ。 なのでその陰には、「 試したけどダメだったアイデア 」みたいなものがたくさんあるわけです。
で、効率的に実用を目指すならともかく、「 今はとにかく色々と試行錯誤してAIで遊びたい 」という方(私も)は、 そういった失敗例や推測原因なども何かの参考になるかもしれません。
という事で、そういったアイデア達の供養も兼ねて、ここに列挙しまくっておきます。
まずは直近の内容と関連するものからいきましょう。
AIの回答内に、関連ページのリンクを貼ってもらおうとする際、 たぶん多くの人は「 JSON の知識ファイルの構造の中に、URL を組み込もう 」とするはずです。 以下のように:
{
...
"page1": {
"title": "たけのこポテンシャル",
"url": "https://github.com/RINEARN/ai-examples/blob/main/q_and_a/knowledge_ja/takenoko.md"
"description": "「たけのこポテンシャル」について詳しく解説しています。",
"text": "# たけのこポテンシャル\n\nたけのこポテンシャルは、物理学における..."
},
...
}
もしこれが機能するならメンテナンス性もいいですし、そもそも発想として自然ですよね。私も最初はコレを試しました。
が、ぜんぜんうまく機能しない です。回答AIが、この URL を認識できてる感じが全くしない。
で、よくよく考えてみると恐らく、 JSON の構造や内容って、知識を「検索」する際には意味があるんでしょうが、 検索結果の段階では、関連性の高い文章が抜き出された or 要約されただけの、「ただの文章」になってそう ですよね。
なので、検索前に項目の一覧を見たりはできるかもしれないですが(できてましたし)、しかし 「 検索でヒットした文章 」が含まれている上位構造を、JSON 内から逆引き的に特定して、その別の要素("url" 等々)の値を見る、とかはたぶん無理 なんですよ。
だから、普通のプログラムのように、 JSON の構造から「あれ」で検索をかけて、その結果の構造から「これ」と「それ」を抽出して結び付けて… みたいな複雑な事を AI にやってもらおうとしても、仕組み的にたぶんできない。 JSON による構造化は、あくまでも検索品質を上げるための整理と割り切ったほうがよさそうです。
次も、また回答でリンク張ってもらう際の工夫(失敗)です。
具体的には、Markdown の知識原稿の先頭あたりに、 「 このページの URL は: https://... です。 」みたいな記述を入れ込む という手。 検索で原稿の本文がピックアップされるなら、本文の中に URL を入れ込めば、一緒に読む事になるだろうから認識できるだろう、と思えるわけです。一見すると。
が、よほど本文が短くない限りは、これも失敗します。
というのも、恐らく検索結果の文章は、長い記事の全体を常に読むわけではなく、ある程度は要約されたりチャンクに抽出されたりしています。 まあ、そうしないと認識コンテキスト長があふれてしまいますからね。
なので、URLが検索結果の中に常に含まれてくれる保証はないわけです。というか体感だと、記事がある程度長いと、ほぼ含まれない。
さて、そもそも「 Web に知識原稿をアップして、URLと概要の対応表まで作って、ページへのリンクを AI に貼ってもらう 」という事までやるんだったら、
って手も思い浮かびますよね。
が、これもダメです。理由は複数あるのですが(後の項目で述べます)、ここで一番問題になるのは
という仕様です。
なお、Webアクセス機能のサポート当初はこういう「 URL 直開き 」ができました。 が、その後 Web 機能を使って「 支払いが必要なはずのサイトを何故か読めてしまう 」みたいな問題が色々浮上し、 たぶんそれに関連してか、一時機能が削除されたましたよね。
で、再び Web 機能が使えるようになって以降は、「 URL 直開き 」はできなくなりました。 なので、普通に Web アクセス機能を使ってやるのは無理筋です。
どうしてもやるなら、自サイトのシステムにAIアクセス用の API を生やして、 GPTs の「 Actions 」という機能を使って AI にページを取得してもらう、という形になります。 もっと工夫して、AI用の検索システムを作って、関連部を抜き出すような処理をサイト側に実装してもいい。 そこまでやれば、ページ数が著しく多い場合は結構有用かもしれません(うちでも将来的に検討はしています)。
が、そこまでやると実質、知識検索システムを自前で構築して、ガチなRAGを組むようなものですからね。 そこそこの範囲内のページ数なら Knowledge のJSONファイルを生成して、 AIに直接与えた方がお手軽ですし、レスポンスも速いです。
これは上の失敗例の続きです。
という手です。 これ自体は実際に可能 です。
しかも、自作ソフトウェアのサポートAIとかを作りたい場合だと、 そのソフトの使い方って、ググればほぼ確実に自サイトのページがトップに来るので、 うまくこの手を使えそうなんですよね。
つまり、
みたいなものが作れそう、というか 実際に作れます。 コレは普通に仕組みとして動いたので、実際やりました。 が、回答の精度をぜんぜん上げられず、結果的にはボツ案に なりました。
その原因については色々探ったんですが、やっぱり現在の ChatGPT の Web アクセス機能の仕様に由来していて、根本的な解決は難しい。 具体的には以下のような仕様です:
これにより、Web アクセス機能を経由して読んだ内容は、 明らかに Knowledge と比べてピンぼけしまくります。 また、文脈も飛びまくって、なんだか チャンク分割を一切チューニングしていないRAG みたいな内容理解度になる。
で、こんな低いレベルでチューニングに手を焼くんだったら、やっぱ Knowledge として直接与えて、もっと高いレベルでチューニングに時間使った方がよっぽどコスパいいわ、という結果になりました。
ちなみに ChatGPT に Web アクセス機能がサポートされた当初は、「 自サイトの Web ページにアクセスし、読んだ内容を直接読んでそのまま答える 」事が可能でした。 ChatGPT 自身が、テキストベースのブラウザみたいなツールを直接使っていて、そのUIについて答えてくれた事もあります。 自サイトに色々な実験ファイルを置いて、読んでもらって色々実験してましたが、応用の可能性が高そうでワクワクしていました。
が、前項で述べた Web アクセス機能の凍結・再開のゴタゴタ以降は、やはり制限が一気に加わって、同じような事はほぼできなくなりました。 やはり著作権関連の配慮なのでしょう。
ところで、GPTs には作者の所有ドメイン認証の仕組みがあるので(信頼性担保のため)、作者が所有しているサイトに対しては制限を緩和したアクセスも可能にしてほしいですね…。今後に期待です。まあ待つよりサイトに API 生やして Actions で読ませろって話でしょうがね。
さて、上のように Web アクセス機能の限界を把握すると、次に「 Knowledge 検索と Web アクセスを組み合わせて、互いの弱点を補い合う形で活用できないか? 」と考えたりしますよね。
例えば Knowledge は、あくまでもある程度の範囲に絞った知識を、高速かつ高精度に答える用にする。 で、Web アクセスは、Knowledge でカバーできない大量で最新を補う。といったように。
が、これは絶対無理という訳ではないのですが、あまりうまくいきません。うちも試しましたが最終的にはボツ案になりました。
その推測原因は以下の通りです:
この通り、現状の Web アクセスというのは使う側にとってもちょっと気難しい機能で、 安易に組み合わせるとむしろ精度を低下させる原因になります。
特に AI が混乱するのは、かなりのマイナスです。 チューニングは、いかに混乱する要素を削って、ピントを合わせてもらうかという作業が多いので。 なので、使わないなら Web アクセスは OFF にしておいた方がいいと思います。
さて、ここで終わるとなんかネガティブな失敗例でしめる事になってしまうので、最後にポジティブなセクションをちょっともってきて終わりにしましょう。
具体的には、「 まだ実用はしてなくて、本当に実用水準までもっていけるのかも検証途上だけど、なんか有用そう 」といった手を掲載します。
(この内容は今後もちょくちょく追記していくかもしれません。)
さて、これはたぶん結構な人がやってるんじゃないかと思うんですが、「 Knowledge ファイルの中に指示を仕込む 」という事が、ある程度できます。
といっても、Knowledge ファイルに登録する内容って、たぶん内部的に チャンク分割 とかされた上で、 検索によって該当部だけ抜き出し・要約されたりする前提で使う必要があります。 なので、たとえば 「 かなり長い指示を、Knowledge として登録して読んでもらう 」みたいな手はたぶん筋が悪い。 結局ピンボケしてしまって、最初から指示の中に詰め込んだ方が精度がいい、という結果にたぶんなるでしょう(私はまだやった事はない)。
じゃあどういった方面で有用そうか? というと:
という方面がなんか面白そうだな、と思っています。逐次処理的な指示や分岐のユニットとして、Knowledge を使う という感じ。
で、実際に試した結果、ごく簡単な例ではうまくいきました。複雑な例ではまだです。とりあえずその結果を掲載します。
まず、以下のような Knowledge ファイルを合計 5 枚作ります:
で、上記を AI に登録した後、本来の「指示」欄には以下のように指定します:
- AI設定画面の指示 -さてこれで、Knowledge1~5 までに分割した指示を、うまく逐次的に読み進めながら処理してくれるでしょうか? 実際の会話の内容は以下の通りです:

と、この通り、うまく意図通りに逐次処理ができているようです。まあ本当かどうかは分からないですが、回答を信じるなら。
実はこれびっくりしたんですよ。絶対失敗すると思ってたので。というのも、普通の RAG のシステムって、質問に対して検索をかける処理フローは、回答を生成する処理フローとは別になっている事が多いようで、それだとこういう事は難しいんですよね。 なんか普通は Retriever というやつが、質問に関連性が高い情報を探して、その検索結果と質問をセットにしてから、回答を考える用の AI に渡すようで。
だから、これをやろうとすると、回答を考える用の AI 自身が Retriever や検索システムと、自発的に何度もコミュニケーションを行える必要があるわけです。 で、GPTs の Knowledge は、なんか普通にさりげなく、そんな高度な事ができてる(ように見える)。すごいぜ OpenAI さんって感じですね。
次です。これは既に広く知られていて、実際使われている手です。私は だるまと赤べこさんの、この動画 で知りました。
詳細はもう上記の素晴らしい動画を見てくださいという感じなのですが(私の下手な説明よりよっぽどいい)、 やっぱりプログラムを書く人間としてはすごく応用の可能性を感じる、ワクワクする手ですよね。
一方、色々情報を集めてると、やっぱり「 Knowledge に仕込んだスクリプトを、崩れないままそのまま抜き出す 」みたいな事は結構コツやチューニングが要るみたいで、苦戦している意見も見かけます。 スクリプトは、本当に「全く崩れずそのまま」参照する必要があるので、普通に知識を追加するよりも、確かに難易度は高そうです。 特に、Knowledge 周りの仕様変更に付き合わされるとかが辛そうです。 ちょっと回答の方向が微妙に変わった? では済まないですからね。
でもまあ、そのうち試してみたいです。 「決まったスクリプトを活用すればいい作業」の相棒AI とか作れそうですし。 試すのが楽しみ。
さてさて、結局は今回も長文になってしまいましたが、この連載は今回で最後です。最終的に以下の3回の記事になりましたね:
もしこの記事に検索で飛んできて、読んで興味を持っていただいた方は、ぜひ上記の冒頭 2 記事も読んでみてください! この記事をおもしろいと感じてくれた方なら、上記もきっとおもしろいと感じてもらえるはず。ただ、めっちゃ長いですがね…
このプロジェクトで数か月間、いろいろと実験や検証を重ねてきましたが、現時点でのそれらの全てを出し切るつもりで、それぞれの回に結構気合を込めて書きました。誰かの何かの参考に、少しでもなってくれると、とても嬉しいです。
RINEARN では、今後もこのプロジェクトに継続的に注力し、また節々でお知らせしていきます。それでは、またの機会に!
